](/media/header/treebranches.jpg)
Branches
Was sind Branches?
Das Konzept von Branches lässt sich gut durch einen Baum visualisieren. Es gibt einen Stamm, der mit der Erde verwurzelt ist und den ganzen Baum trägt. Aus diesem Stamm wachsen viele verschiedene kleinere Äste heraus, die den Baum vielfältiger machen. In diesem Szenario ist der Hauptstamm unser master-branch. In der Entwicklung für sensitivere Sprache wird dieser inzwischen auch manchmal main-branch, aber da das lokale Erstellen eines Repositories meist master erstellt, bleiben wir bei der Bezeichnung. Dieser Branch trägt das Hauptprojekt und ist von Beginn an da. Die anderen kleineren Äste sind Branches, die wir zusätzlich erstellen können. Diese sind viele verschiedene Versionen unseres Hauptprojekts und erlauben uns kreativ zu sein.
Für Psycholog/innen kann es zum Beispiel nützlich sein bei Datenanalysen mit Branches zu arbeiten. Sagen wir mal, ihr habt in eurem Hauptprojekt eure Analyse schon fertig, euch fällt aber im Nachhinein auf, dass es vielleicht noch einen besseren und einfacheren Weg gibt. Dann könnt ihr einen neuen Branch zu eurem Hauptprojekt erstellen, an dem ihr euren neuen Weg erstmal testweise ausprobieren könnt. Falls der neue Analyseweg doch nicht so klappt, wie ihr es euch vorgestellt habt, könnt ihr ganz einfach wieder in euer Hauptprojekt wechseln mit der funktionierenden Analyse und da weiterarbeiten.
Wenn ihr jetzt aber den neuen Analyseweg besser findet als den Alten und ihn in euer Hauptprojekt übernehmen wollt, mergt ihr die beiden. Der Ast verwächst also mit dem Baumstamm.
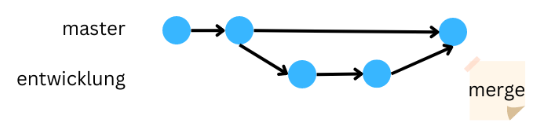
Hier noch ein weiteres Beispiel, warum Branches nützlich sein können. Ihr seid gerade an einer Hausarbeit dran oder sogar eurer Bachelorarbeit und gebt eine erste Version davon ab. Dann könnt ihr zur besseren Dokumentation, für diese Abgabe einen Branch erstellen und diesen dann einfrieren. Das heißt ihr benutzt ihn nicht mehr, sodass er bleibt wie er ist. Dadurch könnt ihr diese “Version” eurer Arbeit speichern, falls ihr sie später nochmal benötigt.
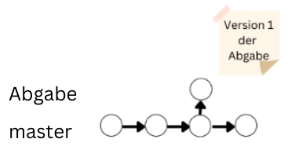
Der Master-Branch
Der master-Zweig ist der default-Branch in Git. Dieser wird mit dem Befehl git init automatisch erstellt und die meisten Personen ändern dies nicht. Der master-Branch ist also nicht speziell, sondern einfach nur die Voreinstellung.
Commits und befindet sich automatisch immer auf unserem aktuellen Commit. Damit wir wissen, wo sich der Branch gerade befindet, hat Git einen Zeiger oder Pfeil eingebaut.

Commit ist der mit dem Namen “Neuer Commit”. Der grüne Zeiger des master-Branches zeigt darauf.
Einen neuen Branch erstellen
Wir wollen jetzt einen neuen Branch in unserem Ordner “Praktikum” erstellen, um zu testen, ob ein neuer Analyseweg besser ist als der Alte. Die erste Möglichkeit ist über das Terminal. Navigiert zu dem Ordner in dem der neue Branch sein soll mit cd und gebt anschließend das Command git branch Analyse1 ein.

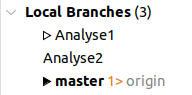
Auf SmartGit müssten euch nun unter Local Branches drei Optionen angezeigt werden: master, Analyse1 und Analyse2.
Woher wissen wir auf welchem Branch wir uns gerade befinden? In SmartGit ist das wie immer ziemlich einfach. Da wird der aktuelle Branch einfach dick gedruckt.
Aber auch im Terminal gibt es die Möglichkeit herauszufinden, was unser aktueller Branch ist.
Git hat dazu einen speziellen Zeiger namens HEAD. Dieser zeigt immer auf den lokalen Branch auf dem man sich gerade befindet.Mit dem Befehl git log --oneline --decorate kann man im Terminal sehen, wo der HEAD-Zeiger gerade hinzeigt.


Auf GitHub seht ihr direkt auf der Startseite eures Projekts auf welchem Branch ihr euch befindet.

Branches wechseln
Wir wollen jetzt zu dem Branch Analyse1 wechseln. In der Sprache von Git wird diese Betrachtung eines Branches als checkout bezeichnet. Über das Terminal ist der Befehl daher git checkout Analyse1. Der HEAD-Zeiger bewegt sich damit zu unserem ausgewählten Branch. Ob es geklappt hat, können wir mit dem bereits eben verwendeten Befehl git log --oneline --decorate testen.

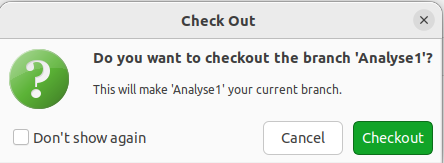
Auch interessant zu wissen: Die Dateien, die in eurem normalen Dateiexplorer angezeigt werden, ändern sich äquivalent dazu.
Machen wir uns das Ganze mal an unserer Datei “Datenauswertung” deutlich. Sagen wir mal, dass wir mit den Daten einen t.test() durchführen wollen, uns aber noch nicht ganz sicher sind, ob das überhaupt etwas bringt. Dazu ändern wir erstmal die Datei.

Jetzt öffnen wir SmartGit und stellen sicher, dass wir immer noch auf unserem Branch Analyse1. Wir führen nun einen Commit auf diesem Branch durch, der die oben aufgeführten Änderungen enthält. Unser HEAD-Zeiger zeigt nun auf Analyse1. Wechselt nun mal zwischen den zwei Branches hin und her und schaut euch den obersten Commit an. Hier sehen wir den Unterschied. Der t.test()-Commit ist nur auf dem Branch Analyse1 vorhanden (Bild 1). Auf dem Branch master ist nur unser inzwischen alter “Neuer Commit” (Bild 2).
Bild 1: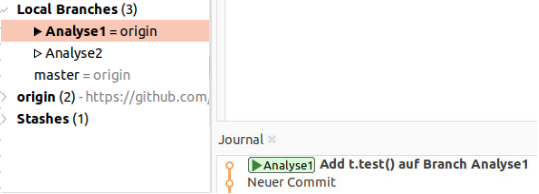
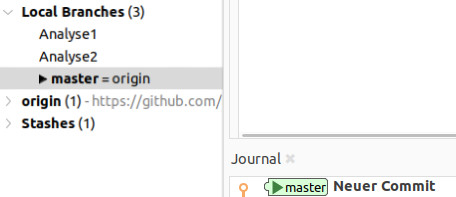
Falls ihr jetzt also auf master wechselt und hier irgendwelche Veränderungen macht, tut ihr das mit euerer alten Dateiversion (ohne die Veränderungen, die auf dem Analyse1-Branch gemacht wurden). So weit wollen wir allerdings jetzt noch nicht gehen. Wie ihr aus dem Abschnitt Conflict Solver in SmartGit wisst, entsteht ein Konflikt immer dann, wenn in derselben Zeile unterschiedliche Dinge stehen. Aktuell stehen unsere zwei Branches demnach nicht in einem Konflikt, da wir hier in Analyse1 nur eine Zeile hinzugefügt haben und in der Zeile unseres master-Branches nichts steht. Falls ihr euch für die technische Seite dieses Vorgangs interessiert, schaut in den Appendix A.
Da wir zu Übungszwecken einen Merge mit Konflikt ausführen wollen, werden wir jetzt sich widersprechende Branches erstellen. Dafür gehen wir wieder in unsere Datei und ändern dieselbe Zeile wie vorhin.

Wir stellen sicher, dass wir uns auf dem master-Branch befinden und führen einen Commitdurch. Unser Projekt hat jetzt eine Divergent History, was soviel bedeutet wie auseinandergehende Geschichte.
Die Datei auf dem einen Branch hat einen t.test(), die andere einen Vektor namens z.
Jetzt haben wir ein Original auf dem master und eine Entwicklungsdatei auf dem Analyse1-Branch. Man kann mit der Entwicklungsdatei herumexperimentieren, ohne an dem Original etwas ändern zu müssen.
Zwei Branches Mergen
Natürlich kann man zwei Branches auch wieder zu einem zusammenführen. Das Prinzip ist dasselbe wie wenn man zwei Autoren hat, die unterschiedliche Versionen einer Datei erstellt haben und dann den Conflict Solver benutzen müssen. Das steht im Abschnitt über SmartGit.
Wenn ihr dem Tutorial bis hierher gefolgt seid, dann müsstet ihr zwei verschiedene Versionen eines Projekts auf verschiedenen Branches liegen haben.
Wir wollen nun den Branch Analyse1 und master zusammenfügen. Dafür wechseln wir auf den master-Branch und gehen bei SmartGit auf den Button Merge rechts oben in der Ecke.
Dann öffnet sich ein Fenster bei dem wir auf Merge to Working Tree gehen.
SmartGit sollte nun so aussehen:

Wenn wir jetzt auf die entsprechende Datei gehen, von der es auf den zwei Branches unterschiedliche Versionen gibt, sollte man den Conflict Solver angezeigt bekommen. Wie dieser funktioniert, steht im Abschnitt über SmartGit genauer. Trotzdem kommt hier nochmal eine kurze Zusammenfassung.
Die Datei, die im Konflikt ist, sieht so aus:

Conflict Solver.

Auf diesen klicken wir und es geht ein neues Fenster mit dem Conflict Solver auf.
Jetzt müssen wir entscheiden, welche Version wir nehmen. Hier ist das noch sehr simpel, da wir nur eine Zeile haben, die sich unterscheidet.
Wir haben entschieden, dass wir die Analyse unserer Entwicklungsdatei in unser Original einbauen wollen.

t.test() in die Mitte “gezogen” haben, speichern wir das und schließen den Conflict Solver. Es öffnet sich erneut ein Fenster.
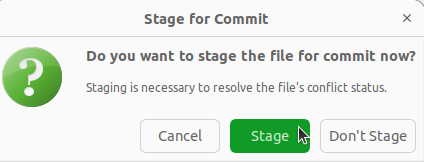
Commit durchführen können.
Es öffnet sich dieses Fenster durch das wir unseren Commit finalisieren können und eine Commit-Message hinzufügen können.
Jetzt habt ihr zwei Branches erfolgreich gemerged.
Auf SmartGit seht ihr den erfolgreichen Merge im Log.


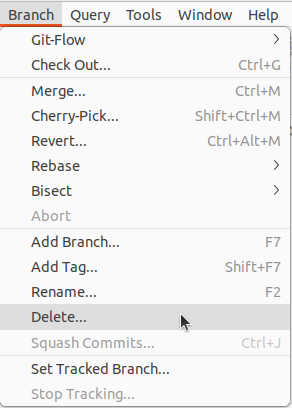
Branches löschen
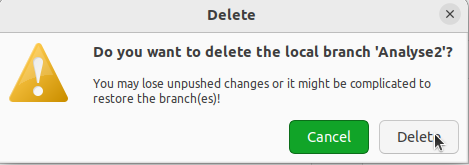
Wie ihr in dem Tutorial mitbekommen habt, haben wir den Branch Analyse2 gar nicht benötigt. Also werden wir ihn jetzt löschen. Dafür klicken wir auf Analyse2 (sodass er rot hinterlegt ist). Dann gehen wir in der Menüleiste auf Branch und dann auf Delete….
Remote Branches lokal hinzufügen
Zum Abschluss des Tutorials gehen wir nochmal in ein Setting, in dem ihr mit mehreren anderen Personen zusammen an einem Projekt arbeitet. Hier kann es sein, dass eine andere Person einen Branch erstellt und auf GitHub hinzufügt, den ihr vielleicht auch nutzen wollt. Trotzdem wird er nicht automatisch bei euch lokal hinzugefügt. Remote Branches sind in diesem Fall also Branches, die auf GitHub in eurem Repository liegen, aber noch nicht bei euch lokal.
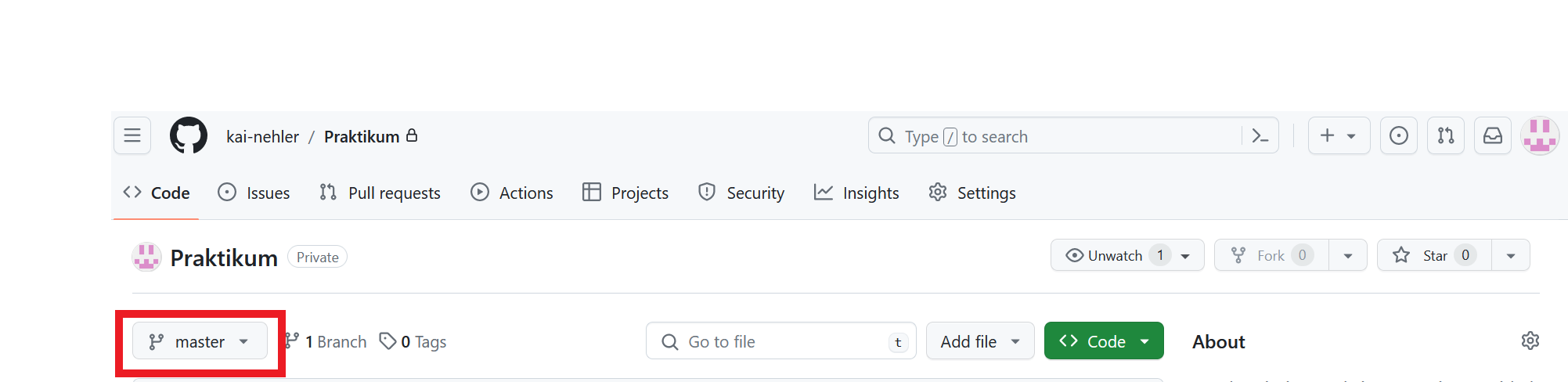
Damit wir diese Situation alleine simulieren können, fügen wir einfach auf GitHub einen neuen Branch hinzu. Dazu geht ihr zunächst auf die Hauptseite eures Repository - also die auf dem Bild dargestellte Ansicht - und drückt auf master.
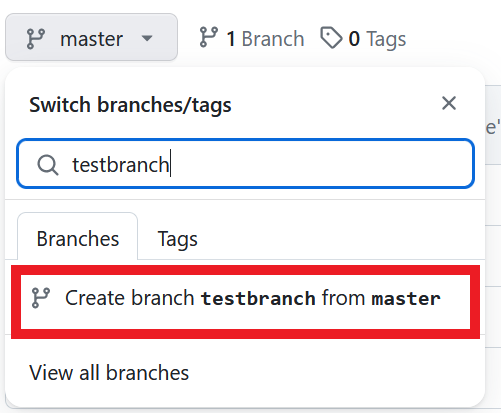
Nun haben wir also einen neuen Branch auf GitHub erstellt, der bei uns lokal noch nicht existiert. Dafür wechseln wir zurück auf SmartGit. Die Ansicht muss nochmal aktualisiert werden (bspw. über einen pull, aber da kann man verschiedene Wege gehen. Ihr solltet jetzt angezeigt bekommen, dass es einen Branch im origin mehr gibt, den ihr nicht unter local Branches seht.
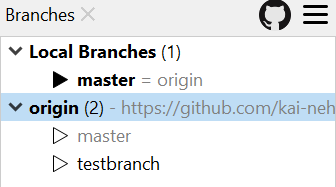
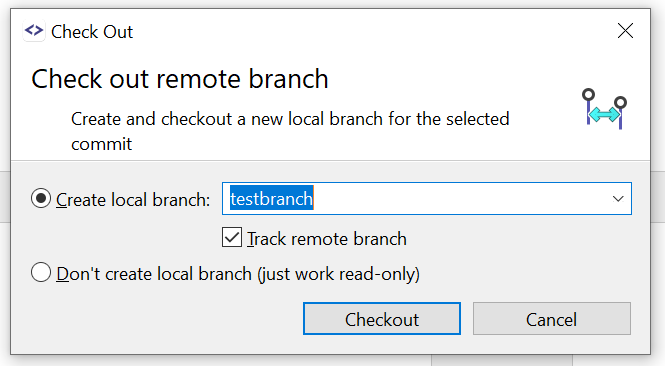
Nun habt ihr den Branch auch lokal.
Fazit und Ausblick
Wie ihr seht, sind Branches in Git ein sehr nützliches Tool, beispielsweise wenn ihr ein Original und eine Entwicklungsdatei habt. Natürlich ist das Branches-Tool noch viel umfangreicher als hier beschrieben. Ihr könnt auch die Entwicklungsdatei nochmal spalten und dann entscheiden, welche ihr mergen wollt - im Endeffekt also die Branches immer weiter aufsplitten. Hier aber aufpassen, dass ihr den Überblick behaltet.
Appendix A
Wie funktioniert die Datenspeicherung?
Ihr kennt bereits das grobe Konzept von Branches, widmen wir uns mal der etwas technischeren Erklärung von Branches. Wir müssen zunächst verstehen wie Git Daten speichert. Zunächst erstmal eine grobe Erklärung.
Nehmen wir hier zur Verdeutlichung unser schon existierendes Git-Repository Praktikum. In diesem liegt die Datei Datenauswertung.R.
Verändern wir jetzt etwas kleines an der Datei. Fügt in einer Zeile ein Ausrufezeichen hinzu oder einen Punkt. Wichtig ist, dass die Datei in einen neuen Commit gepackt werden muss. Öffnen wir nun das Terminal und mit cd unser Git-Repository.

Jetzt wollen wir die Datei für einen Commit vorbereiten. Dafür muss man sie, wie ihr wisst, erstmal ins Staging Environment laden.

Anschließend führen wir einen Commitdurch.

Wie unterscheidet Git jetzt aber den neuen Commit vom Alten?
Dafür erstellt Git bei jedem Commit, den ihr durchführt, sogenannte Checksums. Zu jeder Checksum gehört dann logischerweise auch eine andere Version der Datei. Git erstellt somit quasi einen Schnappschuss eurer Datei, dessen Name die jeweilige Checksum ist.
Schauen wir uns mal an, wie so eine Checksum aussieht.
Dafür gebt ihr im Terminal den Befehl git log ein oder ihr schaut euch über SmartGit euer Log an.
Dieser Befehl zeigt euch eure Commit-Historie an und auch die jeweiligen Checksums, die Git erstellt hat. Das sind diese langen Zeichenabfolgen:

Commits. Ihr werdet nie zwei identische finden.
Auf SmartGit sind die Checksums etwas schwerer zu finden und sehen auch ein bisschen anders aus. Geht dafür auf den Log-Button in der obersten Leiste.

Es öffnet sich noch ein Fenster, dass jeden eurer Commits in diesem Repository anzeigt.
Die Checksum zu unserem neuen Commit finden wir rechts in dem Commit Fenster.
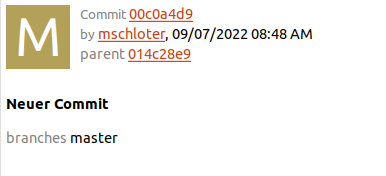
Wie ihr hier sehen könnt, zeigt SmartGit nicht die ganze Checksum an, sondern nur den Anfang von ihr.
Auch interessant ist, dass SmartGit euch auch anzeigt von welchem Commit der neue abstammt. Welcher Commit also das “Elternteil” des Neuen ist. So könnt ihr, vor allem in der Hinsicht auf verschiedene Branches, sehr gut den Überblick über eure Commit-Historie behalten.
**Tieferes Verständnis von Speicherprozessen**
Eine Checksum oder auch Prüfsumme wird jedes Mal erstellt, wenn man eine Datei in das Staging Environment lädt. Diese kann zum Beispiel so aussehen: “7a3k9”. Mit der Checksum soll die Integrität von Daten geprüft werden. Das beinhaltet die Kontrolle der Korrektheit, Vollständigkeit und Konsistenz unserer Datei. Der Computer kann so sicherstellen, ob die Datei einen Fehler hat oder nicht.
Nützlich ist das zum Beispiel, wenn ihr eine Datei aus dem Internet ladet und sichergehen wollt, dass kein Fehler beim Herunterladen passiert ist. Ihr müsst einfach nur die Checksum der Datei aus dem Internet und euerer Datei auf dem Computer vergleichen. Sollten die Checksums identisch sein, ist kein Fehler aufgetreten.
Zurück zu Git. Ihr habt gerade eure Datei in das Staging Environment geladen und dabei für diese Datei eine Checksum erstellt. Anschließend wird diese Version der Datei in einem Git-Repository untergebracht und die Checksum zum Staging Environment hinzugefügt.
Wenn ihr jetzt den Commit durchführt, nimmt Git die Checksum jedes Subordners und speichert diese in einem Tree-Objekt in eurem Git-Repository. Darauf folgend wird ein Commit-Objekt erstellt, das diese Metadaten enthält. So kann ein Schnappschuss der Daten erstellt werden, wann immer es gebraucht wird.
Datenstruktur von Git
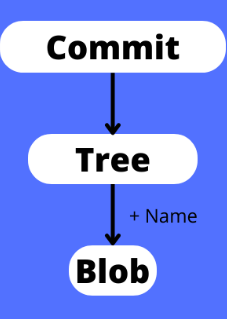
Zurück zu unserem Ordner “Praktikum”. Dieser enthält unser Objekt Datenauswertung.R. Dazu zugehörig wird ein sogenannter “Blob” erstellt. Ein “Blob” ist ein Objekttyp, der benutzt wird, um den Dateininhalt in einem Repository unterzubringen. Jetzt brauchen wir allerdings noch ein Objekt, das diesen Dateiinhalten auch Namen wie hier Datenauswertung.R zuordnen kann. Dafür ist das “Tree-Objekt” zuständig. Zu guter Letzt befindet sich in diesem Ordner auch noch ein neues Commit-Objekt, das wir durch die Durchführung des Commits von Datenauswertung.R erstellt haben. In diesem befindet sich ein Schnappschuss der Datei zu dem Zeitpunkt an dem der Commit erstellt wurde.
Hier könnt ihr euch diese grobe Erklärung der Datenstruktur von Git nochmal verbildichen:
Metadaten
Noch ein kleiner Ausflug zum Thema Metadaten. Wenn ihr ein Foto von etwas macht, speichert eure Kamera oder euer Smartphone nicht nur das Foto, sondern auch die zugehörigen Metadaten. Dazu kann gehören:
Wann ist das Foto entstanden?
Wo ist das Foto entstanden?
Was für eine Kamera wurde benutzt?
…
Metadaten sind also im Prinzip Daten, die Informationen über bestimmte Merkmale anderer Daten enthalten.