](/media/header/black_and_white_white_boat.jpg)
Vorwort
Es empfiehlt sich sehr, für das tiefere Verständnis des Themas den Quell-Code dieses Beitrages runterzuladen und sich diesen bei Ungewissheiten anzuschauen, um eine Anwendung des Themas RMarkdown mitzunehmen. Dieser Beitrag dient in erster Linie dazu, Ressourcen zu bieten und einen Überblick zu verschaffen! Viel Erfolg beim durcharbeiten.
Setup für dieses Tutorial: R & RStudio
Für die Nutzung von RMarkdown ist eine Installation von R unabdingbar um Mitzuarbeiten und den Code selbst anzuwenden. RStudio ist auch ein großer Vorteil, da es viele hilfreiche Integrationen für die Arbeit mit RMarkdown bietet, sowie einen visuellen Editor, dazu aber später mehr.
Dementsprechend empfiehlt sich, einer Installationsanleitung zu folgen und gleichzeitig auch bestenfalls grundlegende R-Kenntnisse zu besitzen oder aufzuholen, wie sie in unseren Einleitungskurs R-Crash Kurs oder dem RefresheR-Workshop erklärt werden.
Hier auch eine Schnellverlinkung der Downloads für R und RStudio, falls Sie bereits inhaltlich mit R vertraut sind, aber noch eine Installation benötigen.
Sofern die technischen Gegebenheiten überprüft wurden, geht es mit dem nächsten Abschnitt weiter.
Was ist RMarkdown?
RMarkdown ist ein Dateiformat, welches es ermöglicht, dynamische Dokumente zu generieren, die R-Code ausführen können. Es kombiniert reinen R-Code mit formatierten Texten, Tabellen, Plots, Gleichungen und, welche alle auf verschiedene Weise mit Code und dessen Ergebnissen aktiv verbunden werden können.
Dies ist durchaus hilfreich im Eigengebrauch, wenn man sich Konzepte der Programmiersprache oder Statistik anschauen will, man Daten hat die man dynamisch betrachten will oder sich mit der Zeit verändern wie bei einer Bachelorarbeit mit laufender Erhebung, oder allgemeine Berichte hat, welche immer ähnliche Eingaben entgegennehmen.
Aus der Perspektive der Disziplin der Psychologie und auch für die weitere Wissenschaft ist es vor allem spannend, da es die eigene Arbeit automatisiert und gleichzeitig transparenter, verständlicher und damit replizierbarer für Externe macht. Die Arbeit mit RMarkdown macht es somit auch einfacher Open Science zu betreiben.
Eine ausführlichere technische Beschreibung von RMarkdown
RMarkdown-Dateien enthalten sowohl R-Code-Abschnitte, als auch Markdown-Text-Abschnitte, vergleichbar mit Jupyter Notebooks & Python. Dabei sind die zugrundeliegenden Markdown-Funktionen an sich sehr basic und finden sich auch auf der Pandoc-Dokumentationsseite. Hier sei zu unterscheiden zwischen denen Abschnitten mit dem Hinweis Extension: und denen ohne diesen Präfix - erstere sind nur verwendbar, wenn man direkt mit Pandoc per knitr::knit-Befehl oder knit-Button das Dokument in ein gewünschtes Endformat rendert. Wenn man hingegen den rmarkdown::render()-Befehl verwendet hat man meist nur Zugriff auf die simplen Funktionen, die keine gesonderte Erweiterung von Pandoc sind. Der Prozess wird auch auf der offiziellen RMarkdown-Seite erläutert unter How it works. Damit lässt sich auch bereits eigenständig fast der ganze Rahmen der Möglichkeiten eigenständig erarbeiten unter Verwendung dieser beiden verlinkten Dokumentationen.
Wie öffne ich RMarkdown-Dateien in RStudio?
Glücklicherweise besitzt RStudio einige Integrationen in seiner Nutzeroberfläche und hat das rmarkdown-package bereits vorinstalliert. Die Dateien lassen sich also, wie ein R-Skript, per Doppelklick in Rstudio öffnen und direkt per Knit verarbeiten oder einzeln ausführen.
Visual Editor vs. Source Mode
Man kann entweder direkt in einer Word-artigen Darstellung in einem WYSIWYM-Editor (What you See Is What You Mean) mit größerer Stütze im Visual Editor arbeiten, womit einige Prozesse generell schneller laufen können, statt wie sonst auch mit dem direkten Source-Code in RStudio zu arbeiten. Bei direkter Umsetzung per Knit ist dies eine gute Möglichkeit, besonders wenn man sich nicht auf HTML stützt. Jedoch sei Vorsicht geboten, in einem bereits existierenden Projekt oder bei der Anwendung komplexerer Verfahren und HTML-Befehle auf den Visual Editor zu wechseln, da er einige Formatierungen verallgemeinert oder gänzlich verschluckt und damit Details entfernt oder sogar die Funktionalität des bisherigen Projektes zerstören kann. Außerdem weicht auch die Darstellung im Visual Editor unter Umständen von der finalen Darstellung in der Enddatei ab.
Zusammengefasst lohnt sich die Gemütlichkeit des Visual Editors besonders bei kleinen Projekten die direkt in Pandoc übersetzt werden. Aber für jegliches größere Projekt, das auch mehr HTML nutzt oder sogar gänzlich andere zusätzliche Frameworks empfiehlt sich dringlichst die Arbeit am Source-Code, um die Kontrolle über das eigene Schaffen zu behalten.
Durch regelmäßiges Knit-en lässt sich ebenfalls ein visueller Abgleich schaffen, mit welchem auch der größte Vorteil des Visual Editors etwas weniger einschlägig ist.
Textbearbeitung mit (R-)Markdown
Reiner Text lässt sich in RMarkdown einfach runterschreiben und fungiert erstmal als einfacher Text. Das entsprechende Ausgabeformat und damit verbundene externe Software oder Frameworks bestimmen dann das Aussehen des Texts auf globaler Ebene. Aber natürlich gehören zu einem Dokument typischerweise auch mehr Aspekte als nur reiner Text. Und selbst dieser ist teils auch formatiert um auf gewisse Worte eine Betonung zu legen.
Diese Textformatierung sowie weitere Elemente, darunter Tabellen, Abbildungen, Überschriften und Gleichungen werden im Nachfolgenden in ihrer Implementation in (R-)Markdown besprochen, besonders in Differenzierung zwischen den absolut universellen Basics und den Eigenheiten des Interpreten, der nur über knit vorhanden ist, Pandoc.
Text stylen
Text lässt sich relativ einfach schiefstellen und fettdrucken. Er lässt sich auch als CODE darstellen oder durchstreichen! Diese lassen sich auch frei kombinieren (mit Ausnahme von Code).
Um Texte so zu verändern, muss man ihn nur mit entsprechenden Sonderzeichen umschließen. Dies sieht folgendermaßen aus
*Dieser Text ist schiefgestellt*
**Dieser Text ist fettgedruckt**
~~Dieser Text wird durchgestrichen~~
~~***Dieser Text bekommt alles auf einmal ab!***~~
Letzteres folgend auch visualisiert:
Dieser Text bekommt alles auf einmal ab!
Blockzitate
Blockzitate lassen sich so schreiben, wie man es vielleicht von Mails kennt.
Mit > zu Beginn einer Zeile lässt sich ein Blockzitat für einen gegebenen Paragraphen erstellen. Dies sieht dann folgendermaßen aus:
>Dies ist ein Zitat
wird zu
Dies ist ein Zitat
Blockzitate können auch ineinander verschachtelt werden!
>Dies ist ein Zitat
>
>>Dies ist ein Zitat in einem Zitat
wird zu
Dies ist ein Zitat
Dies ist ein Zitat in einem Zitat
Titel & Links
Man kann Titel der Stufe 1 bis 6 hinzufügen. Diese sind vergleichbar mit den einzelnen (Unter-)Überschriften in bspw. Word. E muss immer eine freie Zeile vor dem Heading sein, wie bei vielen Elementen in Markdown die nicht reiner Text sind. Diese bekommen auch automatisch einen Link oder auch Verweis zugeordnet, den man aber auch selbst bestimmen kann.
ATX-Überschriften
# Level 1 Heading
## Level 2 Heading
### Level 3 Heading
Es gibt auch theoretisch ein anderes Format, dies bringt jedoch keinen nennenswerten Vorteil mit sich und ist sogar eingeschränkter ins seinen Levels.
Wie sorge ich dafür, dass mein Text nicht verarbeitet wird?
Dieser Beitrag ist eigentlich ja auch in RMarkdown geschrieben - wie kann man dann den Code darstellen, ohne dass er angewandt wird? Einerseits gibt es Code-Chunks, die wir noch besprechen werden, welche hier genutzt werden. Andererseits besitzt Pandoc aber auch eine direkte Verbatim-Umwandlung. Verbatim heißt, dass alles was man schreibt “wortgetreu”(=verbatim) erhalten bleibt, Sonderzeichen die sonst eine Bedeutung haben und sich umwandeln würden bleiben also erhalten. Dies setzt man um, indem man den entsprechenden Abschnitt um 4 Leerzeichen oder ein Tab einrückt! Diese Lösung ist aber nicht zwingend universell - stattdessen lassen sich einzelne Zeichen mit einem Backslash direkt davor (´\´) auch von der Umwandlung ausschließen.
Verlinkung auf Überschriften
Folgende Überschrift:
## Level 2 Heading
Können wir automatisch als Link mit der Schreibweise: [Level 2 Heading] oder [Text](#level-2-heading) aufrufen um zu ihr zu springen.
Wollen wir diese Verlinkung ändern mache wir das folgendermaßen:
## Level 2 Heading {#neuer-link}
Jetzt lässt sich auf diese Überschrift nun verweisen, indem [neuer-link] oder [Text](#neuer-link) verwendet wird. Dies ist beispielweise interessant, wenn man die selbe Überschrift mehrfach verwendet oder seinen link verkürzen will.
Automatische Links
Wenn man einen externen Website-Link verlinken will, reicht es diesen in <> einzuschließen. Er verlinkt dann automatisch an die entsprechende Adresse, E-Mails eingeschlossen!
Inline Links
Inline Links werden mit [Text oder Titel der angezeigt wird](LINK) erstellt. Der Text kann hierbei auch Markdown-Formatierung wie * nutzen. Diese Lösung ist eleganter wenn im Text den Lesefluss nicht unterbrechen möchte und Links in andere Wörter einbinden will. mit dem Präfix mailto: im Link lassen sich auch hier Mails verlinken!
Shortcut Links
Wiederholende Links können auch als Shortcut vorderfiniert werden und bei gleichem Namen immer aufgerufen werden. Dies sieht folgendermaßen aus:
Siehe [diesen Link] oder [diesen Link].
[diesen Link]: Hier_Link_einfügen`
Listen
Mit Markdown lassen sich auch Listen erstellen, welche Inhalte in verschieden geordneter Form darstellen. Viele dieser Formate funktionieren auch bei Messengerdiensten, um einen weiteren Nutzen mitzugeben.Bei allen Listen außer der Mehrebenenliste ist es für Pandoc-Markdown wieder wichtig, dass eine Leerzeile vor der Liste existiert.
Liste der Listen
Einfache kompakte Liste
* one
* two
* three
- one
- two
- three
Einfache lockere Liste
* one
* two
* three
one
two
three
Liste über mehrere Zeilen pro Eintrag
* Text
Weitergeführter Text
* Weiterer Paragraph. Mit einem Codeblock:
{ code }
Text
Weitergeführter Text
Weiterer Paragraph. Mit einem Codeblock:
{ code }
Mehrebenenliste
* Item 1
+ Item 2
- Item 3
- Item 1
- Item 2
- Item 3
- Item 2
Zahlen-Listen
1. one
2. two
3. three
- one
- two
- three
To-Do Listen
- [ ] noch zu machen
- [x] bereits erledigt!
- noch zu machen
- bereits erledigt!
Zahlen-Mehrebenenlisten (PANDOC)
9) Ninth
10) Tenth
11) Eleventh
i. subone
ii. subtwo
iii. subthree

Automatisch sortierte Listen (PANDOC)
#. one
#. two
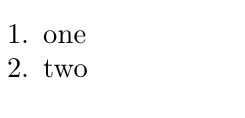
Tipp zum Schreiben mehrerer Listen
Um sicherzugehen, dass nicht zwei aufeinander folgende Listen fälschlich verbunden werden oder folgender Content mit eingerückt wird, empfiehlt es sich, einen nicht-eingerückten HTML-Kommentar <!-- --> nach der Liste einzubauen, statt eine leere Lücke zu hinterlassen.
Horizontale Trennstriche
Um Inhalte schön zu trennen bietet sich folgender Befehl an:
Man nutzt entweder *, - oder _ 3 mal am Stück in einer eigenen Reihe und separiert diese bestenfalls noch unten und oben mit einer Leerzeile. Damit bildet sich dann automatisch ein horizontaler Trennstrich!
Valide Möglichkeiten diesen darzustellen wären etwa:
* * * *
oder
---------------!
Man beachte auch die Leertellen überhalb und unterhalb, die eingebaut wurden in dieser Veranschaulichung. Für eine Beispiel siehe die Quellen.
Tabellen
Tabellen lassen sich einfach, grafisch anschaulich im Text einbinden.
Pipe Tabellen
Die über Formate hinweg verbreitesten Tabellen sind vermutlich Pipe-Tabellen. Diese setzen sich auch von den darauf folgenden Tabellen ab durch ihre flexible Form. Es lassen sich unter anderem auch verschiedene Ausrichtungen für die Spalten wählen!
| Right | Left | Default | Center |
|---|---|---|---|
| 12 | 12 | 12 | 12 |
| 123 | 123 | 123 | 123 |
| 1 | 1 | 1 | 1 |
Die Ausrichtung lässt sich an folgendem Code erklären:
| Right | Left | Default | Center |
|------:|:-----|---------|:------:|
| 12 | 12 | 12 | 12 |
| 123 | 123 | 123 | 123 |
| 1 | 1 | 1 | 1 |
Wobei die Doppelpunkte : die Ausrichtung der gesamten Spalte bestimmen! Beim auslassen folgen sie dem allgemeinen Standard des Textes.
Es gibt auch weitere Tabellen, die für Nutzer der knit-Funktion bzw. Pandoc relevant sind. Pipe-Tabellen erlauben nämlich bspw. keine Mehrzeilen, Listen oder eine weniger aufwendige Form.
Weitere Tabellenformate
Simple Tabelle (Pandoc)
Simple Tabellen sehen bspw. folgendermaßen aus:
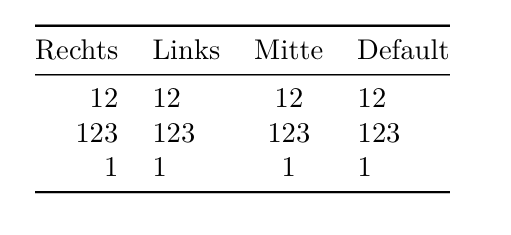
Hierbei ist die Position der Inhalt in der Tabelle abhängig davon, wie die Überschrift zu den Trennlinien positioniert ist. Ist sie rechts angeordnet, ist es rechtsbündig, links linksbündig, mittig ist sie zentriert und Default folgt der Standardanordnung, typischerweise links.
Rechts Links Mitte Default
------- ------ ---------- -------
12 12 12 12
123 123 123 123
1 1 1 1
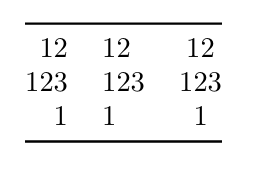
Statt einer Überschrift lässt sich auch eine weitere Reihe Trennlinien unter den Inhalten einrichten. Dann folgt die Ausrichtung dem ersten Element der Tabelle, statt der Überschrift.
------- ------ ----------
12 12 12
123 123 123
1 1 1
------- ------ ----------
Wird also zu einer Tabelle, bei der die erste Spalte rechts, die zweite links und die dritte zentriert ihre Inhalte ausgibt!
Mehrzeilen-Tabellen (Pandoc)
In relativ ähnlichem Schema lassen sich auch Tabellen erstellen, die mehrere Zeilen pro Eintrag spannen (nur für PDFs!). Dafür müssen die Trennlinien am Anfang und Ende stehen und Reihen voneinander mit Leerzeilen auseinandergeschrieben werden. Die Header trennt man auch weiterhin mit einem Trennstrich von den restlichen Inhalten, wenn man sie nutzt.
------------------------------------------
Index Inhalt
---------- -----------------------------
Erste Zeile Hier steht etwas über Sachen.
Hier stehen weitere Sachen.
Zweite Zeile Oh, noch mehr Sachen!
------------------------------------------
wird etwa zu

Jedoch erlauben diese Tabellen noch nicht, dass man bspw. verschiedene Zellen kombiniert. Dafür gibt es noch ein anderes Format.
Grid-Tabellen (Pandoc)
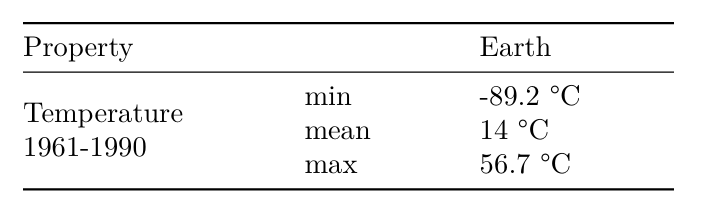
Grid-Tabellen sind, wie der Name vermuten lässt ein Raster welches strukturiert werden kann, um einzelne Zellen der Tabelle zu definieren, dabei auch Zellen welche 2+ Reihen oder Spalten einnehmen. Ihre Header sind mit Gleichheitszeichen von den Inhalten getrennt statt mit Bindestrichen. Folgend wieder ein Beispiel:
+---------------------+----------+
| Property | Earth |
+=============+=======+==========+
| | min | -89.2 °C |
| Temperature +-------+----------+
| 1961-1990 | mean | 14 °C |
| +-------+----------+
| | max | 56.7 °C |
+-------------+-------+----------+
wird zu:
Auch die Ausrichtung des Texts wird leicht anders bestimmt, mit : links für links, rechts für rechts und auf beidn Seiten für eine zentrierte Ausrichtung. Bei Tabellen mit Kopfzeile ist dies an dem Trenner, der aus Gleichzeichen besteht.
Bei kopflosen Grid-Tabellen sind diese an den oberen Trennstrichen. Beispielhaft sieht dies folgendermaßen aus:
+--------------:+:--------------+:------------------:+
| Rechts | Links | Mitte |
+---------------+---------------+--------------------+
Abbildungen
Abbildungen und Bilder können folgendermaßen eingebunden werden:

Wie man sieht sind diese quasi strukturiert wie Links mit einem !-Präfix, letztendlich ruft man auch nur den Link eines lokalen oder externen Bildes (aus dem Internet) auf und stellt es danach dar. Falls das Bild inline dargestellt werden soll, muss es dafür einfach mit anderen Inhalten zusammen im selben Paragraph stehen.
LaTeX-Gleichungen
Mit RMarkdown lassen sich auch mathematische Gleichungen mittels LaTeX erstellen. Wer nicht weiß, was LaTeX ist und nicht mit der Syntax vertraut ist, kann sich den Abschnitt hier drunter anschauen, indem kurz erklärt wird, was es ist und wie es funktioniert.
Was ist LaTeX?
LaTeX ist eine weitverbreitete Syntax, um für Dokumente mathematische Gleichungen zu schreiben. Es ist einerseits in einem eigenständigen Editor der Wahl nutzbar, findet aber auch auf Websiten und anderen Formaten Anwendung, indem es eingebunden wird. Pandoc besitzt beispielsweise auch die Kapazitäten, LaTeX zu verarbeiten. Wer nun die Syntax lernen möchte und etwas tiefer Einblicken möchte kann bei Interesse [diesen Guide](https://www.overleaf.com/learn/latex/Learn_LaTeX_in_30_minutes#What_is_LaTeX?) durcharbeiten.Es ist möglich jederzeit LaTeX-Blöcke zu öffnen, sowohl mit der begin-end Syntax als auch mit einem $ für Inline Math bzw zwei $-Symbole für Gleichungen die eine eigenen Block bekommen sollen.
Hier ist eine Beispielgleichung, die in LaTeX geschrieben wurde und in einen Block gelegt ist:
\begin{equation*} \mathrm{Var}(Y) = \sum\limits_{i=1}^{n} (y_i - \mu)^2 \cdot \Pr(Y = y_i) = \sum\limits_{i=1}^{n} (y_i - \mu)^2 \cdot p_i \end{equation*}
Mit einem Rechtsklick auf eben jene lässt sich auch der LaTeX-Code meist anzeigen, da die letztendliche Gleichung auf der Seite durch ein JavaScript namens MathJax gerendert wird. Dies entspricht auch dem PanDoc-Standard
Footnotes (PANDOC)
Footnotes sind ein weiteres sehr nützliches Feature, welches spezifisch in Pandoc, aber auch in vielen anderen Markdown-Interpretern existiert. Es handelt sich um Fußnoten wie man sie aus verschiedenen (wissenschaftlichen) Texten kennt.
Hier packen wir unsere erste Fußnote hin,[^1] und hier die Nächste.[^lang]
[^1]: Eine einzeilige Fußnote
[^lang]: Diese Fußnote erstreckt sich über mehrere Zeilen in meinem Code.
Um die Zugehörigkeit zu zeigen müssen die Inhalte entsprechend eingerückt sein (1-2x Tab)!
Dieser nächste Text-Part sollte nicht mehr zur Fußnote gehören.
Hier packen wir unsere erste Fußnote hin,1 und hier die Nächste.2
Dieser nächste Text-Part sollte nicht mehr zur Fußnote gehören.
Auf der PandaR-Seite werden diese Fußnoten auch automatisch an das Ende im designierten Footer platziert, statt an der aufgerufenen Stelle direkt referenziert zu werden! Dies zeigt auch gut, inwiefern man gewisse Zuordnungsprozesse mit (R-)Markdown automatisieren kann, die man je nach Text-Editor händisch einarbeiten müsste.
Erweiterungen mit CSS, HTML - Divs & Spans
Man kann Bildern auch mit einer weiteren, eckigen Klammer HTML-Attribute geben, um so unter anderem ihre Größe zu beeinflussen!
bspw. {width = 60%} setzt das Bild auf 60% der verfügbaren Weite.
Dies ist nur ein Beispiel für HTML-Attribute, es gibt auch viele weitere, die sich auf Links, Bilder und allesmögliche anwenden lassen, aber dies sprengt schnell den Rahmen für unsere Anwendungszwecke.
Putting the R in RMarkdown: Angewandter Code
Die vorigen Elemente, die wir erklärt haben beziehen sich erstmal nur auf reines Markdown, der Grundbaustein unseres Editors mit dem bisher nur Text und Textelemente abgedeckt sind. Jetzt gehen wir in die Anwendung welche begründet, warum wir genau RMarkdown verwenden. Die Anwendung von Codeblöcken und In-lineCode sowie Parameter
Codeblöcke
Codeblöcke sind das Herz eines jeden statistischen oder anderweitig Programm-anwendenden Berichts. Mit ihnen lässt sich der eigene Code nicht nur gegliedert im Text präsentieren sondern auch ausführen.
Man schreibt diese in genereller Form mit folgendem Zeichen ``` in der dargestellten dreifachen Ausführung, dafür müssen die Striche (auch Backticks genannt) oberhalb und unterhalb des Code platziert werden, um so den abgeschlossenen Block zu formen. Dies sieht folgendermaßen aus:
```
Hier steht Code!
```
In dieser Form bilden sie jedoch erstmal nur reinen Code ab - keine Zuordnung zu einer Programmiersprache oder Möglichkeit zur Ausführung liegt vor.
Wenn wir nun vor die oberen Striche eine eckige Klammer setzen und in diese unsere gewünschte Programmiersprache schreiben, ändern wir dies und sorgen dafür, dass der Code passend zur Sprache formatiert dargestellt wird. R ist dabei in unserem Fall auch zusätzlich direkt lauffähig, eine Eigenheit von RMarkdown. Theoretisch unterstützt RMarkdown auch viele weitere Sprachen, dies sprengt aber den Rahmen für diesen Beitrag.
Inline-Code
Inline-Code unterscheidet sich in seiner Anwendung nicht stark vom Codeblock - es erlaubt einfach wie der Name vermuten lässt, einzelnen Code im Fließtext einzubinden. Dieser wird jedoch typischerweise automatisch ausgewertet ohne im Text angezeigt zu werden, wenn wir bpsw. {r} anhängen um es als R-Code zu werten! Damit eignet sich Inline-Code bspw. um Berichtsvorlagen anzufertigen und Ergebnisse der Deskriptiv- und Inferenzstatistik automatisch aus dem ausgeführten Code zu extrahieren. Dies ist super, wenn man seine (laufenden) Daten öfters neu berechnen muss und die Ergebnisdarstellung nicht immer händisch neu aufbauen möchte.
Outputs & deren Darstellung
Es gibt verschiedene Möglichkeiten, wie man die einzelnen Codeblöcke darstellt und wie sie mit ihren Ausgaben umgehen. Dies ist besonders relevant wenn man Packages wie ggplot2 benutzt. HIER WEITER
The (in this case not!) Working Directory
Es sei darauf hingewiesen, dass das Working Directory, welches per getwd() aufgerufen wird nicht zwingend dem Working Directory entspricht, welches innerhalb des RMarkdown-Dokuments genutzt wird, wenn man den entsprechenden Beitrag knit-ed. Standardmäßig fällt dieses nämlich auf den Ordner zurück, in dem die RMarkdown-Datei liegt!
Eine Veränderung des Working Directories in einem Chunk ruft auch ein Warning hervor und erhält dieses veränderte Directory auch nur für diesen Chunk aufrecht - im Anschluss bezieht er sich wieder auf den Ort, an dem sich das RMarkdown-Dokument befindet!
Daher der Hinweis, dass Verweise auf andere Dateien (auch auf eingefügte Bilder!) in Relation zur Datei geschrieben werden, statt zum allgemeinen Working Directory, welches in RStudio angezeigt wird. Es kann natürlich in einem der Code-Chunks mit setwd() das Directory überschrieben werden, welches im weiteren knit-Prozess verwendet für den Code verwendet wird. Dies ändert aber nichts an den Bildern oder sonstigen Verweisen des Dokuments.
Parameter - Anpasssungsvariablen der Code-Chunks
Wir können unsere Code-Chunks noch weiter individualisieren, in dem wir ihnen Parameter hinzufügen. Diese Parameter im “Tag=value”-Format erlauben die Darstellung des Codes und seine Outputs zu beeinflussen.
Ein Beispiel für einen Parameter ist bspw. “echo = TRUE”, wenn dieser Parameter TRUE ist, wird der Code im finalen Dokument angezeigt, wenn er auf FALSE steht, wird der Code nicht angezeigt und nur sein Output bleibt. Auch kann man mit c(a:b) oder c(-(a:b)) entweder nur die Zeilen a bis b anzeigen oder genau diese ausschließen. Diese Option ist bspw. nützlich wenn man ein Tutorial macht, bei welchem man nur Teile seines Gesamtcodes zeigen möchte.
Hier ist eine Übersicht der Parameter, welche im offiziellen RMarkdown-Cheatsheet aufgeführt sind:
| Parameter | Default-Wert | Effekte & Möglichkeiten |
|---|---|---|
| echo | TRUE | TRUE Zeigt den Code an |
| error | FALSE | TRUE zeigt Error im Output des Chunks an, FALSE bricht den Render ab, wenn ein Error auftritt |
| eval | TRUE | TRUE sorgt dafür, dass der Code überhaupt ausgeführt und evaluiert wird |
| include | TRUE | TRUE notwendig, damit Code & Output gezeigt wird, bei FALSE wird er im Hintergrund ausgeführt, aber nirgends im Dokument gezeigt |
| message | TRUE | TRUE zeigt normale Messages im Output |
| warning | TRUE | TRUE zeigt Warnnachrichten im Output |
| results | “markup” | “asis” Gibt die Ergebnisse als Markdown raus (normale Ergebnisse werden als Code behandelt, nicht von Markdown weiter verarbeitet), “hide” versteckt die Ergebnisse, oder “hold”, welches alle Ergebnisse sammelt und nach dem Code platziert |
| fig.align | “default” | “left”, “right”, oder “center” sind Ausrichtungsmöglichkeiten für die Bilder und Plots die gerendert werden |
| fig.alt | NULL | Hier kann ein String als Alt-Text für Bilder übergeben werden |
| fig.cap | NULL | Hier kann ein String für Bildunterschriften übergeben werden |
| fig.path | “figure/” | Präfix des Ordners in dem die gerenderten Bilder landen |
| fig.width & fig.height | 7 | Die Dimensionen der gerenderter Bilder in Zoll, orientiert an der physischen Größe |
| out.width & out.height | Skaliert die Größe der Ausgabe des Bildes am digitalen Output (exakte Pixel / Prozentteil der Seitenhöhe/-breite) | |
| collapse | FALSE | TRUE Kombiniert einzelne Codezeilen und Ergebnisse zu einem Chunk “##"-Präfix für Ergebnisse |
| child | NULL | Nimmt Vektor oder einzelnes Element entgegen, welches ein R-Skript ist. Führt dieses aus, kann alternativ auch nur unter Erfüllung einer if-Bedingung ausgeführt werden. |
| purl | TRUE | bei FALSE wird der gesamte Code-Chunk aus dem Rendervorgang entnommen |
Für noch mehr Optionen führe str(knitr::opts_chunk$get()) aus!
Setup-Chunk, globale Settings
Es empfiehlt sich, bei längeren Dokumenten einen Setup-Chunk zu nutzen und in diesem Optionen mit knitr::opts_chunk$set(tag = val) global für alle weiteren Chunks einzustellen, sofern man sonst einen gewissen Default-Wert regelmäßig überschreiben würde. Hier ein Beispiel, bei dem ein Ordner zur Ablage für alle generierten Plots & Bilder spezifiziert wird.
if (exists("figure_path")) {
knitr::opts_chunk$set(fig.path = figure_path)
}
Zweck und Darstellung - das Output-Format
Ein Rmarkdown-Dokument lässt sich für verschiedene Zwecke und Formatte anwenden. Hierzu gibt es eine Vielzahl von Dateiformaten und weiterführenden Umgebungen, die diese Dateiformate nutzen. Es findet unter anderem Anwendung als interaktives Notizbuch oder automatisierte Statistikauswertung, als Teil einer Seite im Internet, als Word-Dokument oder Latex-Dokument für einen wissenschaftlichen Bericht. All diese Ausgabeformate kann man direkt im Kopf bestimmen und weiterverwenden. Im folgenden ein paar gängige Formate. Dieses Format lässt sich in der Kopfzeile hinzufügen. Dafür neben den bereits vorhandenen Bestandteilen der Kopfzeile wie title: und date: in einer neuen Zeilen output: hinzufügen und das entsprechende Format festlegen.
HTML
Jegliche R-Inhalte auf PandaR sind in ihrer Darstellung ein Beispiel für HTML-Inhalte in RMarkdown. Ein selbsterstelltes HTML-Dokument wird im Vergleich zu diesen jedoch simpler aussehen.
HTML lässt sich bei diesem Ausgabeformat direkt in das RMarkdown-Dokument einbinden und anwenden.
Ein Anwendungsbeispiel für HTML für wenig Vertraute:
<span style="color: darkred;">Dieser Text ist rot</span>
Dieser Text ist rot
Dies ist eine simple Anwendung, welche reines Markdown schon nicht umsetzen kann!
Interaktives Notebook
Die folgende Art des Outputs und die daraus folgende Darstellung sollte für alle vertraut sein, die bereits mit Jupyter Notebooks arbeiten.
Das Working Directory des Notebooks verhält sich genau wie zuvor für RMarkdown-Dokumente beschrieben. Ein interaktives Noteboook, auch html_notebook spiegelt größtenteils die IDE-interne Darstellung des RMarkdown-Dokuments dar, kann aber beispielsweise auch auf einer externen Seite gehostet werden.
Markdown-Dokument
Markdown-Dokumente als Output-Format transformieren den Code und seine Ausgaben um bevor diese dann in einer fertigen Markdowndatei dargestellt werden. Durch ihr universelles Format können diese Dokumente dann für verschiedene Zwecke bereitgestellt werden, es gibt etwa viele Frameworks und Dienstleister welche das Hosten von eigenen Websites auf Basis von Markdown-Dokumenten erlauben.
Das Output-Format pdf_document erstellt ein normales PDF-Dokument. Die einzige Besonderheit, welche interessant ist sofern man mit mathematischen Gleichungen arbeitet, ist dasss man direkt LaTeX anwenden kann und dafür sogar eigene Makros definieren kann. Für entsprechende Details siehe den Guide von Yihui.
“Literate Programming” als abschließender Gedanke
Nach dem ganzen Reden über die Technik und die Möglichkeiten hinter RMarkdown möchten wir auf das Kernkonzept hinter Programmierdarstellungen wie RMarkdown und Jupyter Notebook blicken, um den Sinn nochmal abschließend zu verdeutlichen. Das grundlegende Konzept nennt sich nämlich “Literate Programming” und befasst sich damit, dass man eingebetteten Code mit in natürlicher Sprache geschriebenen Erklärungen abwechselnd darstellt. Dies macht man, dass man damit anderen seinen Gedankengang transparent erläutern kann, aber auch um selbst durch den Prozess des Erklärens seinen Code besser zu verstehen und auch bei Gelegenheit verbessern zu können!
Damit ist das Kernkonzept definitiv nicht nur darauf ausgelegt, transparente, offene Wissenschaft zu ermöglichen, sondern auch dazu, um seine eigenen Analyse-, Darstellungs- und Coding-Fähigkeiten zu dokumentieren und verbessern.
Darauf aufbauend empfiehlt es sich nun, dieses Konzept für sich selbst im Anschluss auszuprobieren.
Weitere Tools
Abschließend sind hier noch weitere Tools, die interessant in der Arbeit mit Rmarkdown sein könnten.
Angefügte Zitationen mit csl oder .bib sowie citation()
Neben dem bereits genannenten Output-Format lassen sich auch mit bibliography: BibTeX-Dateien eninbinden und mit csl: csl-Dateien einbinden.
bibliography: literatur.bib
csl: apa.csl
BibTex sind dabei die Dateien, welche die Quellen, welche sich automatisch als Zitationen und Literaturverzeichnisse abbilden lassen, enthalten. Die csl-Datei macht das Format dieser Quellen aus. Durch die Einbindung dieser beiden Dateien lässt sich das Zitieren größtenteils automatisieren!
R-Pakete lassen sich oft auch direkt in R(-Studio) zitieren per citation(). Diese geben auch meist direkt einen BibTex-Eintrag mit, den man in eine entsprechende Datei packen kann. Ein gutes Beispiel dafür ist citation("ggplot2").
StyleR
Eine abschließende Empfehlung zur Darstellung des eigenen Codes, ist es diesen einfach automatisch zu formatieren, damit er gut lesbar ist und man dafür keinen erheblichen Mehraufwand aufbringen muss.
Dafür muss man nur das entsprechende Package per install.packages("styler") installieren und anschließend styler::style_file("tutorial.Rmd") das (fertige) Dokument anwenden.
Damit wäre auch schon alles erledigt für ein schönes Endprodukt!
Grundlagen-Guides und Quellen
https://bookdown.org/yihui/rmarkdown/