](/media/header/puzzle.jpg)
Modell-Fit, Stichprobengröße und Fehlspezifikation
Ein Exkurs
Der Likelihood-Ratio-Test ($\chi^2$-Differenzentest) vergleicht die Likelihoods zweier Modelle und somit implizit eigentlich die Kovarianzmatrizen (und Mittelwerte). In Lehrbüchern steht häufig der $\chi^2$-Wert ist stichprobenabhängig und wächst mit der Stichprobengröße, was ebenfalls als Grund für die Fit-Indizes genannt wird. Das ist allerdings nur teilweise richtig, denn der $\chi^2$-Wert ist nur für Modelle stichprobenabhängig, in welchen die $H_0$-Hypothese nicht gilt. In einigen Lehrbüchern steht zudem die Formel für den $\chi^2$-Wert wie folgt: Wir definieren zunächst die sogenannte Fit-Funktion $F_{ML}$ (diese wurde bereits in der Sitzung zur CFA erwähnt), welche die Differenz zwischen der Kovarianzmatrix der Daten sowie der modellimplizierten Kovarianzmatrix quantifiziert (für die Formeln siehe gerne auch bspw. in Schermelleh-Engel, Moosbrugger & Müller, 2003): $$F_{ML}(\hat{\Sigma}_M,S) = \log(|\hat{\Sigma}_M|)-\log(|S|)+\text{Spur}\left[S\hat{\Sigma}_M^{-1}\right] - p,$$ wobei $\hat{\Sigma}_M$ die modellimplizierte Kovarianzmatrix und $S$ die Kovarianzmatrix der Daten ist und $p$ die Anzahl an beobachteten Variablen. $|\bullet| = \det(\bullet)$ ist die Determinante einer Matrix (bspw. $|S|=\det(S)$) und $\text{Spur}$ bezeichnet hierbei die Summe der Diagonalelemente des jeweiligen Objekts (der resultierenden quadratischen Matrix). Die Null-Hypothese besagt: $$H_0:S=\Sigma_M$$ Diese Null-Hypothese sagt also, dass die Kovarianzmatrix der Daten ($S$) und die modellimplizierte Kovarianzmatrix ($\Sigma_M$) identisch sind. Es wird also behauptet, dass interindividuelle Unterschiede und deren Zusammenhänge durch die modellierte Struktur abgebildet werden können. Der $\chi^2$-Wert ergibt sie wie folgt: $$\chi^2:=(n-1)F_{ML}(\hat{\Sigma}_M,S)$$
Somit wirkt es so, dass der $\chi^2$-Wert zwangsläufig mit der Stichprobengröße wachsen muss. Allerdings ist für wachsendes ( $n\to\infty$) $F_{ML}(\hat{\Sigma}_M,S)\to0$, solange die Null-Hypothese gilt. Dies liegt daran, dass $F_{ML}(\hat{\Sigma}_M,S)$ gerade die Differenz zwischen den beiden Matrizen quantifiziert und diese Differenz unter der Null-Hypothese im Mittel gegen 0 konvergiert. Diese Differenz geht für steigende Stichprobengröße gegen den Wert 0, wird also kleiner mit steigender Stichprobengröße. Wenn das Modell korrekt ist, sollten Abweichungen zwischen den beiden Matrizen durch zufällige Schwankungen in der Stichprobe zustande kommen - wenn diese Stichprobe größer wird, werden diese stichprobenbedingten Schwankungen geringer.
Um eine Verteilung als Referenz verwenden zu können (hier: die kritischen Werte der $\chi^2$-Verteilung), ist eine Art Reskalierung vonnöten. Aus diesem Grund wird $F_{ML}(\hat{\Sigma}_M,S)$ mit $n-1$ multipliziert und die bekannte $\chi^2$-Verteilung entsteht. Gilt nun eine Alternativ-Hypothese: $$H_1:S\neq\Sigma_M$$ dann konvergiert $F_{ML}(\hat{\Sigma}_M,S)$ im Mittel nicht mehr gegen Null; es gilt also ( $n\to\infty$) $F_{ML}(\hat{\Sigma}_M,S)\nrightarrow0$, sondern $F_{ML}(\hat{\Sigma}_M,S)\to d$, wobei $d>0$ gerade die wahre Differenz zwischen den beiden Modellen quantifiziert. Das bedeutet gleichzeitig, dass für den zugehörigen mittleren $\chi^2$-Wert unter $H_1$ gilt: $\chi^2_{H_1}\to dn \to \infty$, der $\chi^2$-Wert also mit der Stichprobengröße wächst (da $dn$ gerade proportional zu $n$ wächst)! Wir wollen uns dies an folgendem Modell klar machen:
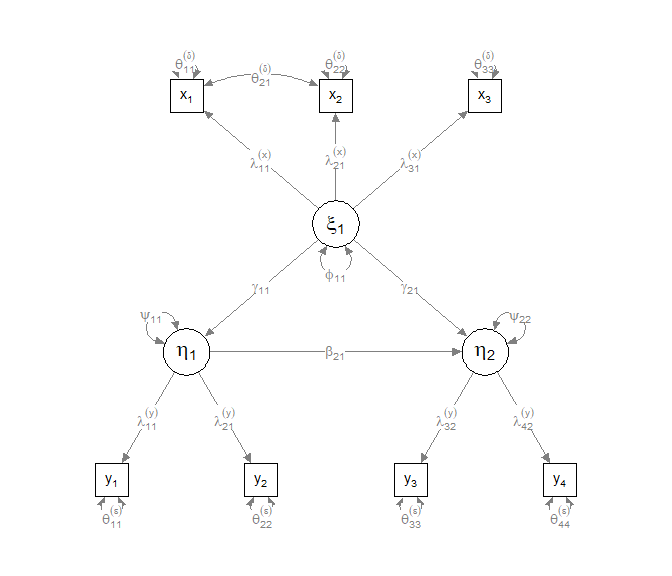
Als Populationsmodell wählen wir das Folgende:
pop_model_H0 <- '
# Messmodelle
Xi1 =~ x1 + 0.7*x2 + 0.6*x3
Eta1 =~ y1 + 0.8*y2
Eta2 =~ y3 + 0.9*y4
# Strukturmodell
Eta1 ~ 0.5*Xi1
Eta2 ~ 0.54*Xi1 + 0.4*Eta1
# Fehlerkovarianzen
x1 ~~ 0.4*x2
'
set.seed(123456)
data <- simulateData(model = pop_model_H0, meanstructure = F, sample.nobs = 200)
Die Werte, die in diesem Modell stehen, symbolisieren die wahren Populationsparameter. Bspw. bedeutet Xi1 =~ x1 + 0.7*x2 + 0.6*x3, dass in der Population gilt: $\lambda_{11}=1,\lambda_{21}=.7$ und $\lambda_{31}=.6$ (wobei $\lambda_{11}=1$ auch der Skalierer ist!). Oder Eta2 ~ 0.54*Xi1 + 0.4*Eta1 steht für: $\eta_2=0.54\xi_1+0.4\eta_1+\zeta_2$ in der Population. x1 ~~ 0.4*x2 symbolisert eine Fehlerkovarianz von 0.4, also $\theta_{21}=.4$.
Wenn ein Modell in dieser Form vorliegt, so kann die simulateData Funktion in lavaan verwendet werden, um dieses Modell zu simulieren. Wir übergeben der Funktion dazu das Modell model = pop_model_H0, spezifizieren mit meanstructure = F, dass alle Mittelwerte im Mittel 0 sind und legen die Stichprobengröße fest mit sample.nobs = 200. In data liegen nun die $N = 200$ Beobachtungen der simulierten manifesten Variablen (die latenten Variablen werden nicht abgespeichert). Hierbei entscheiden die Kürzel, die wir vergeben (z.B. x1 oder y2) über die Namen in data:
head(data)
## x1 x2 x3 y1 y2 y3 y4
## 1 -0.5118338 1.11104804 -0.0729622 -2.2439826 -0.57866486 -1.74546084 -0.37273965
## 2 0.4893225 -0.03456975 -0.2210260 -0.1614957 0.04591967 0.68927309 0.47261383
## 3 -0.4599010 -0.11154386 -1.0774381 0.8126298 -0.68456466 0.71829334 1.67739737
## 4 -0.1563487 -1.94395700 0.5893962 0.2923347 0.38382322 0.08129874 -0.03750505
## 5 -3.9850494 -1.34148731 -3.8810032 -0.4478478 -0.43452292 -2.28563349 -2.76810071
## 6 -1.7981084 -0.66823365 0.6577428 1.4657190 0.13731687 -1.95109209 -1.82901441
Wir verwenden das $H_0$ Modell auch, um die Daten zu analysieren (dies ist das Modell von oben ohne jegliche Zahlen, also in dem Format, welches wir bereits kennen!):
model_H0 <- '
# Messmodelle
Xi1 =~ x1 + x2 + x3
Eta1 =~ y1 + y2
Eta2 =~ y3 + y4
# Strukturmodell
Eta1 ~ Xi1
Eta2 ~ Xi1 + Eta1
# Fehlerkovarianzen
x1 ~~ x2
'
Das Pfaddiagramm sieht so aus (hier wurden die Zusatzeinstellungen curve = T, curvePivot = T im semPlot verwendet):
fit_H0 <- sem(model = model_H0, data = data)
semPaths(fit_H0, curve = T, curvePivot = T)
Schätzen wir nun das Modell und gucken uns den den $\chi^2$-Wert an.
fit_H0 <- sem(model = model_H0, data = data)
fit_H0
## lavaan 0.6.16 ended normally after 44 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 18
##
## Number of observations 200
##
## Model Test User Model:
##
## Test statistic 10.722
## Degrees of freedom 10
## P-value (Chi-square) 0.380
Wie bereits im Beitrag zur CFA besprochen, können wir den $\chi^2$-Wert, die $df$ und den zugehörigen $p$-Wert auch über die fitmeasures-Funktion erhhalten:
fitmeasures(fit_H0, c("chisq", 'df', "pvalue"))
## chisq df pvalue
## 10.722 10.000 0.380
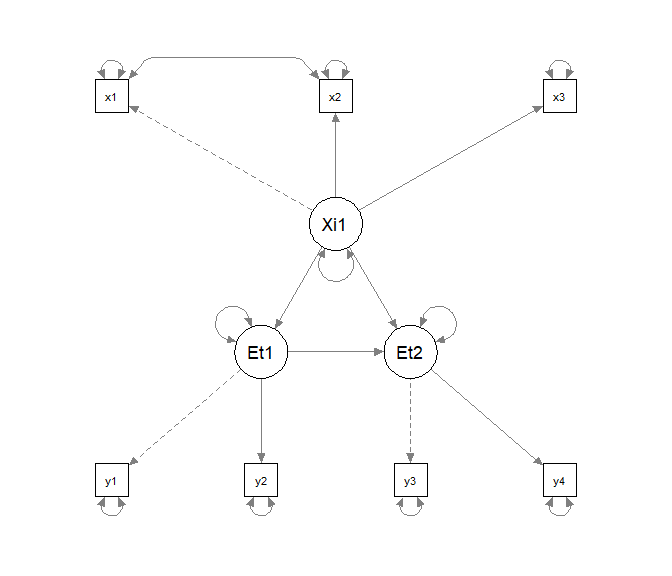
Außerdem wollen wir zwei fehlspezifizierte Modelle betrachten. Unter model_H1_kov speichern wir ein Modell, welches, bis auf die fehlende Fehlerkovarianz, äquivalent zu model_H0 ist.
model_H1_kov <- '
# Messmodelle
Xi1 =~ x1 + x2 + x3
Eta1 =~ y1 + y2
Eta2 =~ y3 + y4
# Strukturmodell
Eta1 ~ Xi1
Eta2 ~ Xi1 + Eta1
'
semPaths(sem(model_H1_kov, data))
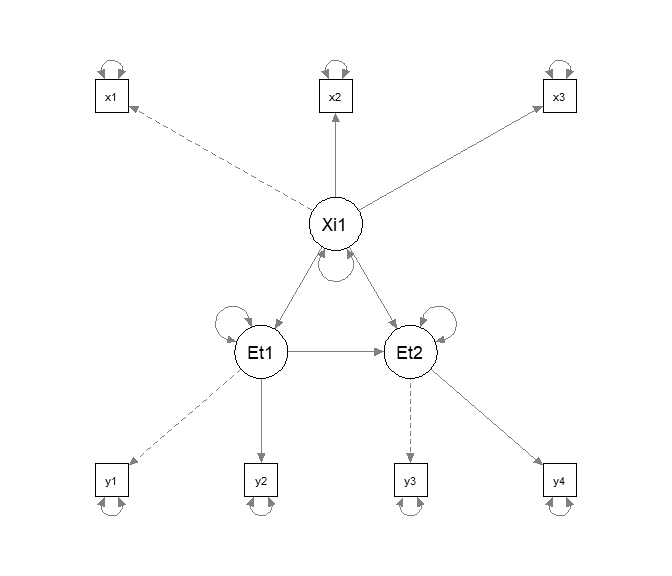
Unter model_H1_Struk speichern wir ein Modell, welches erneut äquivalent zu model_H0 ist, bis auf die fehlende gerichtete Beziehung zwischen $\xi_1$ und $\eta_2$.
model_H1_Struk <- '
# Messmodelle
Xi1 =~ x1 + x2 + x3
Eta1 =~ y1 + y2
Eta2 =~ y3 + y4
# Strukturmodell
Eta1 ~ Xi1
Eta2 ~ Eta1
# Fehlerkovarianzen
x1 ~~ x2
'
semPaths(sem(model_H1_Struk, data))
Hierbei ist das Weglassen der Fehlerkovarianz ein “kleiner” Fehler, während die Annahme einer vollständigen Mediation hier zu einem deutlichen Fehler führen sollte, da in die Fehlervarianz nur zwei Variablen involviert sind, während die gerichtete Beziehung zwischen den beiden latenten Variablen $\xi_1$ und $\eta_2$ mindestens alle manifesten Variablen, die Messungen von $\xi_1$ und $\eta_2$ sind, betrifft. Wir gucken uns den Modellfit für alle drei Modelle an:
fit_H1_kov <- sem(model_H1_kov, data)
fit_H1_Struk <- sem(model_H1_Struk, data)
fitmeasures(fit_H0, c("chisq", 'df', "pvalue"))
fitmeasures(fit_H1_kov, c("chisq", 'df', "pvalue"))
fitmeasures(fit_H1_Struk, c("chisq", 'df', "pvalue"))
## H0:
## chisq df pvalue
## 10.722 10.000 0.380
## H1: Fehlerkovarianz
## chisq df pvalue
## 15.254 11.000 0.171
## H1: Vollständige Mediation
## chisq df pvalue
## 27.263 11.000 0.004
Nun wiederholen wir das ganze für eine größere Stichprobengröße von $n=1000$.
set.seed(123456)
data <- simulateData(model = pop_model_H0, meanstructure = F, sample.nobs = 1000)
fit_H0 <- sem(model = model_H0, data = data)
fit_H1_kov <- sem(model_H1_kov, data)
fit_H1_Struk <- sem(model_H1_Struk, data)
fitmeasures(fit_H0, c("chisq", 'df', "pvalue"))
fitmeasures(fit_H1_kov, c("chisq", 'df', "pvalue"))
fitmeasures(fit_H1_Struk, c("chisq", 'df', "pvalue"))
## H0:
## chisq df pvalue
## 10.436 10.000 0.403
## H1: Fehlerkovarianz
## chisq df pvalue
## 22.704 11.000 0.019
## H1: Vollständige Mediation
## chisq df pvalue
## 62.1 11.0 0.0
Wir sehen, dass das Weglassen der gerichteten Beziehung zu einem größeren mittleren Fehler führt, also zu einem größeren mittleren $\chi^2$-Wert. Gilt die Null-Hypothese, so sollte der mittlere $\chi^2$-Wert bei der Anzahl der $df$ liegen. Nun wollen wir uns die mittleren $\chi^2$-Werte ansehen für verschiedene $n$. Da diese Simulation länger dauern würde, schauen wir uns nur die Ergebnisse an:
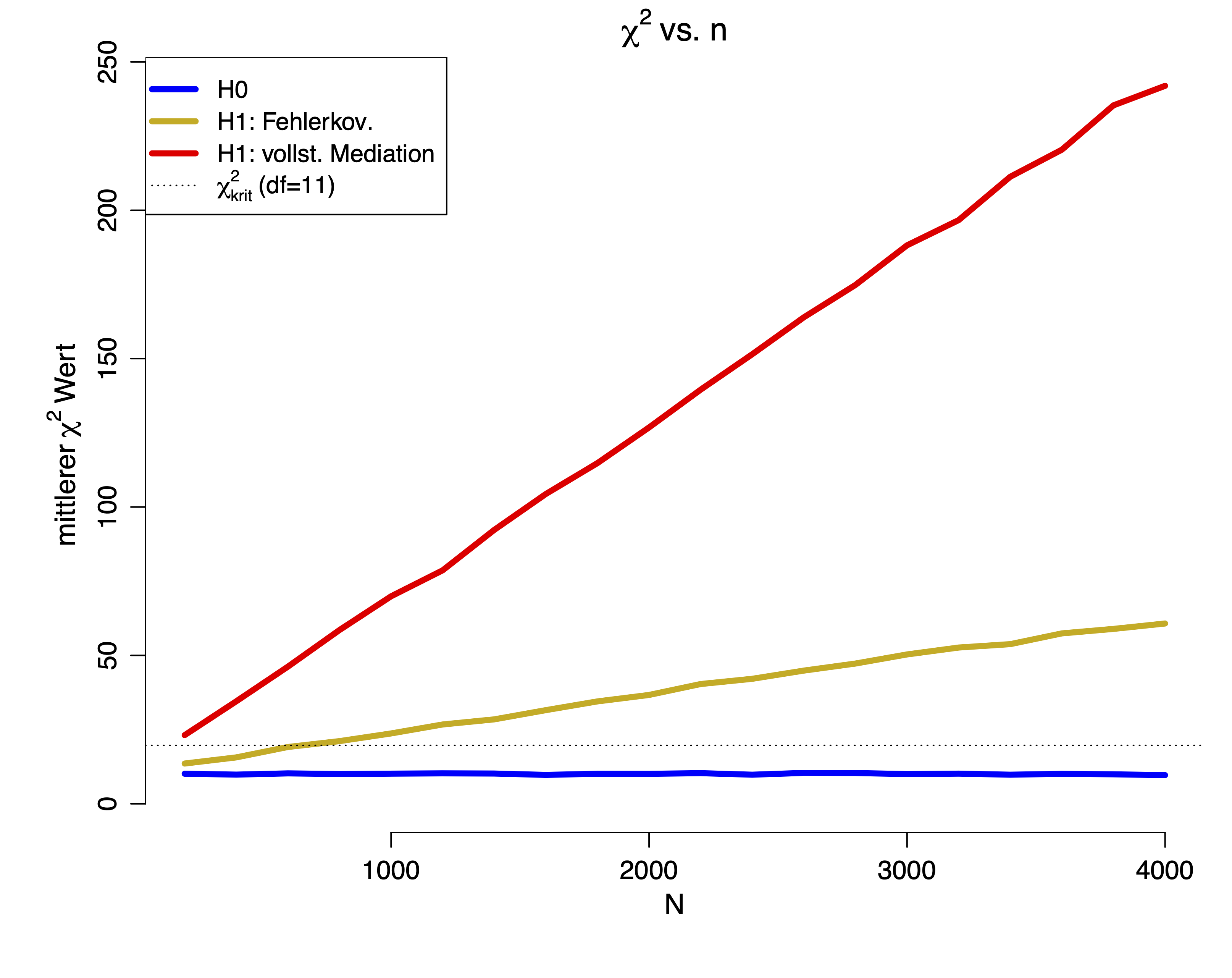
Wir sehen deutlich, dass in beiden $H_1$-Bedingungen der mittlere $\chi^2$-Wert mit der Stichprobengröße wächst. Nur in der $H_0$-Bedingung pendelt sich der mittlere $\chi^2$-Wert gerade bei den $df$ ein. Die gestrichelte Linie repräsentiert den $\chi^2_\text{krit}(df=11)$, somit ist ersichtlich, dass beide $H_1$-Modelle ab einer gewissen Stichprobengröße verworfen werden. Nun ist es aber so, dass in der Wissenschaft Daten häufig nicht perfekt vorliegen, sondern kleine Fehlspezifikationen (also Abweichungen von der Theorie, die aber an sich nicht bedeutsam sind) vorhanden sind. Aus diesem Grund wurden Fit-Indizes entwickelt, welche kleine Fehlspezifikationen relativieren sollen. Ansonsten würde das Verhalten dieses Tests die Wissenschaft dazu bringen, kleinere Stichproben zu untersuchen, was allerdings das Aufdecken von Effekten erschwert. Um diesem Dilemma aus dem Weg zu gehen, wird auf die Fit-Indizes zurückgegriffen.
Beispielhaft gucken wir uns nun das Verhalten des $CFI$ und des $RMSEA$ an. Die Definition des $CFI$ ist:
$$CFI:= 1- \frac{\max(\chi^2_t-df_t,0)}{\max(\chi^2_t-df_t,\chi^2_i-df_i,0)},$$
wobei die Subskripts $t$ und $i$ für das target-Modell, also unser Modell, und das independence-Modell stehen, welches keine Beziehung zwischen den manifesten Variablen annimmt (das Unabhängigkeitsmodell, also das am schlechtesten passende Modell). Einen Ausdruck wie $\max(\chi^2_t-df_t,0)$ bzw. $\max(\chi^2_t-df_t,\chi^2_i-df_i,0)$ oder einfacher $\max(a,0)$ bzw. $\max(a,b,0)$ lesen wir so: hier wird das Maximum zwischen 2 bzw. 3 Ausdrücken bestimmt und damit weitergerechnet; dadurch, dass einer der 2 bzw. 3 Ausdrücke gerade die 0 ist, bedeutet dies, dass dieses Maximum immer größer oder gleich 0 sein wird ($\ge0$). Der $CFI$ ist ein Vergleich zwischen dem schlechtesten und dem betrachteten Modell. Der mittlere $CFI$ unter der $H_0$-Hypothese sollte bei 1 liegen für große $n$, da für große $n$ der $\chi^2$-Wert im Mittel bei den $df$ liegt und somit $\chi^2_t-df_t=0$, also der Bruch im Mittel bei 0 liegt (somit wird von der 1 im Mittel nichts abgezogen unter der $H_0$). Dies erkennen wir in der Grafik daran, dass im $H_0$-Modell der mittlere $CFI$-Wert gegen 1 geht (dies bedeutet gleichzeitig, dass kleine $CFI$s gerade für einen schlechten Fit sprechen!):

Der $RMSEA$ wird wie folgt definiert
$$RMSEA:= \sqrt{\max\left(\frac{F(S,\hat{\Sigma}_M)}{df}-\frac{1}{n-1}, 0\right)}.$$ und ist die mittlere Abweichung pro Freiheitsgrad kontrolliert für die Stichprobengröße. Der mittlere $RMSEA$ unter der $H_0$-Hypothese sollte bei 0 liegen für große $n$, da für große $n$, $F(S,\hat{\Sigma}_M)$ nahe 0 liegt (das hatten wir weiter oben bereits disskutiert, als es darum ging, dass unter $H_0$ gilt: $F(S,\hat{\Sigma}_M)\to0$) und damit $\frac{F(S,\hat{\Sigma}_M)}{df}-\frac{1}{n-1} < 0$ also negativ ist. Das Maximum wiederum zwischen einer negativen Zahl und 0 liegt gerade bei 0. In der Grafik erkennen wir dies daran, dass der mittlere $RMSEA$-Wert des $H_0$-Modells gegen 0 geht (dies bedeutet gleichzeitig, dass große $RMSEA$s gerade für einen schlechten Fit sprechen!):

Der $CFI$ sowie der $RMSEA$ pendeln sich für die $H_1$-Modelle gerade bei den “wahren” Abweichungen des Modells unabhängig von der Stichprobengröße ein. Somit ist ersichtlich, dass dies nicht die tatsächlichen Modelle sind, welche den Daten zugrunde liegen, aber zumindest wird quantifiziert, wie stark diese Modelle vom wahren Modell abweichen — unabhängig von der Stichprobengröße.
Die gestrichelten Linien geben jeweils die Grenze an, ab welchem Wert nicht mehr von einem “guten” Fit gesprochen werden sollte: $CFI < .97$ und $RMSEA > .05$ (Schermelleh-Engel et al., 2003).
Die Abweichungen von 0 bzw. 1 beim $RMSEA$ sowie bei $CFI$ sind allerdings nur für eines der beiden $H_1$ Modelle “extrem”. Nur in diesem würde von keinem guten Fit mehr gesprochen werden: nämlich beim Modell, in welchem fälschlicherweise eine vollständige Mediation angenommen wird (keine gerichtete Beziehung zwischen $\xi_1$ und $\eta_2$). Allerdings sind diese Cut-Off-Werte, die von Schermelleh-Engel et al. (2003) postuliert wurden, keine in Stein gemeiselten Größen, sondern Richtwerte. Schermelleh-Engel et al. haben ein ganz bestimmtes SEM herangezogen und sich dann angeschaut, ab wann die Fit-Indizes so stark vom erwarteten Wert unter der $H_0$-Hypothese abweichen, als das nicht mehr von einem guten Modellfit gesprochen werden kann. Auch andere Autoren wie etwa Hu und Bentler (1999) haben solche Fit-Kriterien postuliert. Allerdings haben auch diese Autoren spezielle Modelle herangezogen und an diesen Cut-Off Werte abgeleitet. Diese Kriterien mögen für viele Modelle “ganz gut” passen, allerdings besteht immer die Möglichkeit, dass sie ggf. für bestimmte Modelle oder Stichprobengröße zu konservativ oder zu liberal sind. Aus diesem Grund wurde das R-Paket ezCutoffs entwickelt, welches simulationsbasierte Cut-Kriterien speziell angepasst an das vorliegende Modell berechnet. Dieses Paket wurde in der Sitzung zu Pfadanalysen und SEM kurz vorgestellt.
Literatur
Hu, L. T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6(1), 1-55.
Schermelleh-Engel, K., Moosbrugger, H., & Müller, H. (2003). Evaluation the fit of structural equation models: tests of significance and descriptive goodness-of-fit measures. Methods of Psychological Research Online, 8(2), 23-74.