](/media/header/gaming.jpg)
Meta-Analyse von Interventionsstudien
Grundlagen des Vorgehens in der Meta-Analyse
Inhaltsverzeichnis
Einleitung
Metaanalysen sind Zusammenfassungen verschiedener Studienergebnisse – meistens sogar ganzer Forschungsbereiche – mit dem Ziel, die breite, manchmal widersprüchliche Befundlage zu einem konkreten Thema statistisch aufzubereiten und zusammenzufassen. Somit kommt ihnen insbesondere in der Wissenschaftskommunikation eine wichtige Rolle zu, da sie es ermöglichen, über die Limitationen und Schwankungen einzelner Studien hinaus eine aktuelle wissenschaftliche Befundlage zu präsentieren.
Bei der Untersuchung psychotherapeutischer Interventionen haben Meta-Analysen in verschiedenen Abschnitten des „Lebenszyklus“ therapeutischer Problemstellungen unterschiedliche Funktionen. In Gebieten mit jahrzehntelanger Forschungstradition können spezifische Teileffekte und die Entwicklung der Interventionseffektivität vor dem Hintergrund gesellschaftlichen Wandels betrachtet werden. Bei der Untersuchung neuerer Störungsbilder können sie dazu dienen, Gemeinsamkeiten besonders effektiver Interventionen zu identifizieren und Richtungen zukünftiger Entwicklungen anzustoßen.
Meta-Analyse therapeutischer Ansätze für Gaming Disorder
Auch wenn die Gaming Disorder bereits 2013 in das DSM-V aufgenommen wurde, stellt die Interventionsforschung zum Thema ein noch relativ junges und breit gefächertes Gebiet dar. Mit der Aufnahme des Störungsbildes in die ICD-11 haben sich auch in Europa neue Rahmenbedingungen für die Entwicklung von Interventionsansätzen gebildet. In diesem Beitrag befassen wir uns mit der Meta-Analyse von Danielsen et al. (2024), in der therapeutische Ansätze für die Gaming Disorder unter drei zentralen Fragen untersucht wurden (S. 2):
Do therapeutic interventions decrease symptoms in patients with gaming disorder?
Does effectiveness of different therapeutic interventions vary in patients with gaming disorder?
Does the effect size vary by how the outcome is measured?
Wie in allen Beiträgen aus diesem Kurs handelt es sich auch bei dieser Studie um einen Fall, in dem die relevanten Daten und Analyseskripte in einem OSF-Repo öffentlich zur Verfügung gestellt wurden: osf.io/kb7f6. Da die Daten – ebenso wie in den anderen Beiträgen dieses Semesters – in der Rohfassung „ein wenig“ unübersichtlich sind, können Sie mit diesem Befehl eine Aufbereitung der Daten durchführen, die das Ganze auf die wesentlichen Variablen einschränkt und bereits etwas bereinigt:
source('https://pandar.netlify.app/daten/Data_Processing_game.R')
An diesem Datensatz (game) sehen wir das zentrale Konzept der Meta-Analyse: Hier ist ein Studienergebnis die empirische Untersuchungseinheit. Jede Zeile des Datensatzes stellt ein Ergebnis dar, wobei natürlich die allermeisten Studien mehr als einen Effekt berichten, sodass diese dann (ganz im Sinne der kürzlich besprochenen gemischten Modelle) Cluster für mehrere Beobachtungen darstellen. Die abhängige Variable stellt die Effektstärke es dar, welche zunächst generell untersucht werden soll (um zu sehen, ob die Interventionen insgesamt etwas bringen). Eine detailliertere Aufbereitung der 12 Variablen aus dem Datensatz finden Sie hier verborgen:
Variablenübersicht
| Variable | Beschreibung | Ausprägungen |
|---|---|---|
cite | Kurze Zitation des Artikels | |
study | ID der Studie | |
effect | ID des Effekts innerhalb der Studie | |
tr_type | Art der Intervention | behavioral, prevention, psychotherapy, other |
ct_trye | Art der Kontrollbedingung | character (10 Ausprägungen) |
dv_type | Erhebungsinstrument | IAT, YIAS, DSM-5, Other |
es | Effektstärke | Standardisierte Mittelwertsdifferenz |
v | Effektvariabilität | |
tr_n_ob | $N$ in der Interventionsgruppe | |
ct_n_ob | $N$ in der Kontrollgruppe | |
follow | Abstand der Messung vom Ende der Intervention | |
male | Anteil der männlichen Teilnehmer in der Studie |
Extraktion der Effekte
Die Suche und Identifikation von Studien, die in einer Meta-Analyse eingeschlossen werden sollen, sind komplexe und vielschichtige Arbeitsschritte. Dabei ist es, wie bei einzelnen empirischen Studien, inzwischen üblich, das Vorgehen mittels Präregistrierung vorab festzuhalten. Für Meta-Analysen mit klinischem Fokus gibt es die zentrale Datenbank PROSPERO, welche neben den Vorgaben für die Präregistrierung auch einen (Versuch eines) vollständigen Überblicks über aktuell laufende und bereits abgeschlossene Meta-Analysen und Reviews aus dem medizinischen, humanbiologischen, pharmakologischen und psychologischen Bereich bietet. Dort findet sich auch die Präregistrierung der hier vorgestellten Meta-Analyse: CRD42022338931.
Insgesamt wurden nach dem Vorgehen, das im Artikel in Abbildung 1 (S. 5) dargestellt ist, 39 Studien in die Meta-Analyse aufgenommen (von ursprünglich 2861 gesichteten Einträgen). Das deckt sich soweit mit den Inhalten des Datensatzes:
# Anzahl der Studien im Datensatz
unique(game$cite) |> length()
## [1] 38
Die zentralen Variablen für Meta-Analysen sind die Effektstärken – als AV sollen sie eine Einschätzung über den gefundenen Effekt in jeder Studie zusammenfassen und deren Analyse ermöglichen. Leider hat sich in den wenigsten Teildisziplinen ein Konsens entwickelt, wie genau die Ergebnisse einer Interventionsstudie berichtet werden sollten, sodass es mitunter sehr viele Schritte erfordert, um die Ergebnisse aller Studien vergleichbar zu machen. Für einen Fall wie diesen, in dem wir daran interessiert sind, Interventions- und Kontrollgruppen hinsichtlich eines relativ einfachen Interventionseffekts zu vergleichen, kommt einem zunächst der übliche Verdächtige – Cohen’s $d$ – in den Sinn. Cohen’s $d$ ist allerdings anfällig für Verzerrungen bei kleinen Stichproben, sodass eine Korrektur (Hedge’s $g$) insbesondere in Meta-Analysen gängig ist. Darüber hinaus bieten z. B. Varianzanalysen das Effektstärkemaß $\eta^2$, welches eng verwandt ist mit einem anderen Effektstärkemaß, dem $R^2$ aus der Regression. Zum Glück gibt es diverse Wege, um Effektstärken ineinander zu überführen, sodass (solange ein Artikel ein paar wesentliche Informationen über die Studie bereitstellt) die meisten Effekte in eine Analyse eingehen können.
Es haben sich diverse Webseiten etabliert, die Online-Effektstärke-Umwandler anbieten. Auch wenn die Nutzung dieser gängig ist (und z. B. auch von Danielsen et al. (2024) eine solche Seite verwendet wird), ist es empfehlenswert, eine syntaxbasierte Variante zu nutzen, da diese meist weniger fehleranfällig ist als das Übertragen von Output einer Website in den eigenen Datensatz und von anderen schnell und direkt reproduziert werden kann. Empfehlenswert für die Berechnung und Umwandlung von Effektstärken in R ist das Paket esc (für effect size calculation).
Schauen wir uns am Beispiel der Studie von Wölfling et al. (2019) an, wie eine einzelne Studie in dieser Meta-Analyse berücksichtigt wird. Laut Danielsen et al. (2024, S. 3) wurde hier Folgendes getan:
Effect size calculations were based on unadjusted means and standard deviations from post-tests, even if the design included baseline measures. If means and standard deviations were not provided, effect sizes were computed from other statistics, if given (e.g., test statistics from mean comparisons), or requested from authors.
Zum Glück finden wir bei Wölfling et al. (2019, S. 1023) die rohen Mittelwerte und Standardabweichungen, um daraus eine Effektstärke zu berechnen. Genauer sind dort in Tabelle 2 drei Messzeitpunkte für die Interventionsgruppe und Kontrollgruppe abgetragen. Um Mittelwerte und Standardabweichungen in R zu übertragen, können wir einen data.frame erstellen.
# Effektstärke für Wölfling et al. (2019)
wolf <- data.frame(
occasion = c(1, 2),
tr_mean = c(5.7, 4.6),
ct_mean = c(11.4, 10.5),
tr_sd = c(3.99, 3.46),
ct_sd = c(4.70, 4.33),
tr_n = c(72, 72),
ct_n = c(71, 71)
)
wolf
## occasion tr_mean ct_mean tr_sd ct_sd tr_n ct_n
## 1 1 5.7 11.4 3.99 4.70 72 71
## 2 2 4.6 10.5 3.46 4.33 72 71
Der Datensatz enthält jetzt für beide Zeitpunkte (während der Intervention, nach der Intervention) die Mittelwerte und Standardabweichungen der Interventions- und Kontrollgruppe. Wie bereits erwähnt, ist das Paket esc für die Berechnung von Effektstärken empfehlenswert:
# Paket laden
library(esc)
## Warning: Paket 'esc' wurde unter R Version 4.3.1 erstellt
# Effektstärke berechnen
with(wolf[1, ], # Datensatz, 1. MZP auswählen
esc_mean_sd(
grp1m = tr_mean, # Mittelwert der Interventionsgruppe
grp1sd = tr_sd, # Standardabweichung der Interventionsgruppe
grp1n = tr_n, # Stichprobengröße der Interventionsgruppe
grp2m = ct_mean, # Mittelwert der Kontrollgruppe
grp2sd = ct_sd, # Standardabweichung der Kontrollgruppe
grp2n = ct_n, # Stichprobengröße der Kontrollgruppe
)
)
##
## Effect Size Calculation for Meta Analysis
##
## Conversion: mean and sd to effect size d
## Effect Size: -1.3082
## Standard Error: 0.1843
## Variance: 0.0340
## Lower CI: -1.6694
## Upper CI: -0.9471
## Weight: 29.4484
Neben dem Cohen’s $d$ werden hier außerdem der Standardfehler und dessen Quadrat (Variance) berechnet. Dieses Ausmaß an Unsicherheit in der Schätzung der Koeffizienten ist für Meta-Analysen besonders zentral, da es kennzeichnet, wie zuverlässig die Information aus einer Studie ist und wie sie demzufolge gegenüber Informationen aus anderen Studien gewichtet werden muss.
In der Präregistrierung von Danielsen et al. (2024) ist allerdings nicht von Cohen’s $d$, sondern von Hedge’s $g$ (eine Korrektur für kleine Stichproben) die Rede:
Effect sizes will be presented as standardized mean difference (Hedges’ g) with confidence intervals.
Das können wir mit dem Argument es.type = 'g' anfordern:
# Hedges g berechnen
with(wolf[1, ], # Datensatz, 1. MZP auswählen
esc_mean_sd(
grp1m = tr_mean, # Mittelwert der Interventionsgruppe
grp1sd = tr_sd, # Standardabweichung der Interventionsgruppe
grp1n = tr_n, # Stichprobengröße der Interventionsgruppe
grp2m = ct_mean, # Mittelwert der Kontrollgruppe
grp2sd = ct_sd, # Standardabweichung der Kontrollgruppe
grp2n = ct_n, # Stichprobengröße der Kontrollgruppe
es.type = 'g' # Effektstärke Hedge's g
)
)
##
## Effect Size Calculation for Meta Analysis
##
## Conversion: mean and sd to effect size Hedges' g
## Effect Size: -1.3013
## Standard Error: 0.1843
## Variance: 0.0340
## Lower CI: -1.6625
## Upper CI: -0.9401
## Weight: 29.4484
Gucken wir, ob diese Effektstärke sich auch im Datensatz von Danielsen et al. (2024) wiederfindet:
# Effektstärke für Wölfling et al. (2019) im Datensatz
game[game$cite == 'Woelfling et al. (2019)', ]
## cite study effect tr_type ct_type dv_type es v tr_n_ob
## 73 Woelfling et al. (2019) 41 1 psychotherapy waiting list Other 1.3082 0.0340 72
## 74 Woelfling et al. (2019) 41 2 psychotherapy waiting list Other 1.5066 0.0359 72
## ct_n_ob follow male
## 73 71 -7 100
## 74 71 0 100
Es fallen zwei Dinge auf: 1. Die Effektstärke hat das entgegengesetzte Vorzeichen (damit positive Zahlen für einen positiven Interventionseffekt sprechen) und 2. es wurde letztlich (entgegen der Präregistrierung und der Bildunterschrift von Abbildung 6 im Artikel) doch mit Cohen’s $d$ gearbeitet. Warum – oder auch dass – dem so ist, wird in der Publikation leider nicht weiter erwähnt.
Fixed Effects Model
Das für die Studie von Wölfling et al. (2019) beschriebene Vorgehen wurde für jede der 38 Studien durchgeführt, sodass wir für jede von ihnen mindestens eine Effektstärke im Datensatz finden. Manche Studien fließen mehrfach ein, weil sie z. B. mehrere Zeitpunkte in ihrer Untersuchung betrachtet haben (wie die Studie von Wölfling et al., 2019) oder aber gleichzeitig mehrere Interventionsansätze mit einer Kontrollgruppe vergleichen (wie z. B. die Studie von Maden et al., 2020).
Ersteres stellt uns vor ein Problem, da wir zunächst verhindern wollen, dass die wiederholte Untersuchung desselben Effekts mehrfach in unsere Meta-Analyse eingeht. Betrachten wir also zunächst nur die Effekte, die sich auf die Messungen mit dem geringsten Abstand zur Intervention beziehen:
# Minimaler Abstand zur Intervention pro Studie
post <- aggregate(game$follow, list(game$cite), \(x) min(abs(x)))
names(post) <- c('cite', 'follow')
# Post-Messungen auswählen
post <- merge(game, post, by = c('cite', 'follow'))
So bleiben 48 Effekte übrig, die wir direkt zusammen untersuchen können. Rufen wir uns die erste Forschungsfrage von Danielsen et al. (2024) kurz in Erinnerung:
Do therapeutic interventions decrease symptoms in patients with gaming disorder?
Letztlich ist hier also eine Einschätzung des mittleren Effekts der entwickelten Interventionsansätze gefragt. In der Notation der Meta-Analyse wird der globale, wahre Effekt mit $\theta$ bezeichnet. In jeder Studie wird versucht, diesen Effekt möglichst gut zu schätzen, was aber z. B. aufgrund des sampling errors nur bedingt gelingt. So wird jeder Effekt $\hat{\theta}_k$ als eine Kombination aus dem wahren Effekt und einem Fehler verstanden:
$$ \hat{\theta}_k = \theta + \epsilon_k $$
Weil sich Fehler traditionellerweise ausmitteln sollten (so unsere große Hoffnung in den meisten Formen der Analyse, die wir in der Psychologie betreiben), könnten wir also einfach den Mittelwert über alle Effektschätzer bestimmen:
# Mittelwert der Effekte
mean(post$es)
## [1] 0.7734437
Mit einem einfachen Einstichproben-$t$-Test könnten wir auch direkt noch prüfen, ob dieser Effekt von 0 verschieden ist, was ich uns angesichts der eklatanten Effektgröße an dieser Stelle aber erspare.
In diese Mittelung ist gerade jeder Effekt $\hat{\theta}_k$ gleichmäßig eingegangen – der auf $n = 15$ basierende Effekt von Maden et al. (2020) war hier also genauso wichtig wie der auf $n=800$ basierende Effekt von Krossbakken et al. (2018). Das scheint etwas unglücklich, weil wir eigentlich annehmen würden, dass größere Stichproben mit einem geringeren Fehler in der Effektschätzung einhergehen.
Dieses Prinzip halten wir in einzelnen Studien im Standardfehler fest: größeres $n$ und geringere Schwankung des Outcomes gehen mit weniger Unsicherheit einher, weswegen uns die inferenzstatistische Absicherung leichter fällt. Da wir im Standardfehler also ein gängiges Maß für die Unsicherheit in der Effektschätzung vorliegen haben, können wir dieses auch direkt wieder benutzen, wenn wir die Effekte zusammentragen. Dabei wollen wir die Effekte, die besonders sicher geschätzt sind, stärker in unsere Schätzung eingehen lassen als die, die mit höherer Unsicherheit versehen sind.
Dieses Gewicht wird traditionellerweise als Inverse des quadrierten Standardfehlers berechnet:
$$ w_k = \frac{1}{SE(\hat{\theta}_k)^2} $$
Als wir vorhin mit dem esc-Paket die Effektgröße einer einzelnen Studie bestimmt hatten, wurde dieser Wert als Weight direkt mit ausgegeben. Im Datensatz sind die quadrierten Standardfehler als v (für sampling variance) gespeichert, sodass wir die Gewichte einfach berechnen können, bevor wir die gewichtete Effektschätzung mit
$$ \hat{\theta} = \frac{\sum_{k=1}^K w_k \hat{\theta}k}{\sum{k=1}^K w_k} $$
ermitteln:
# Gewichte bestimmen
post$w <- 1 / post$v
# Gewichtete Effektschätzung
sum(post$w * post$es) / sum(post$w)
## [1] 0.260876
Wie häufig zu beobachten, ist der geschätzte Effekt dramatisch viel geringer, wenn wir weniger auf veröffentlichte Ergebnisse kleiner Studien achten (zum Thema Publikationsbias gleich mehr).
Fixed Effects Model in metafor
Damit wir die Effektschätzung nicht immer per Hand machen müssen und vielleicht auch noch ein paar interessante Zusatzinformationen bekommen (wie z.B. ob der Effekt über alle Studien hinweg jetzt eigentlich statistisch bedeutsam ist), können wir das metafor-Paket nutzen:
# Gegebenenfalls das Paket installieren
install.packages('metafor')
# Paket laden
library(metafor)
Die Kernfunktion des Pakets ist rma (wahrscheinlich für R und Meta-Analyse?). Die Hilfe zu dieser Funktion ist unfassbar detailliert und enthält diverse Zitationshinweise, sodass es sich wirklich lohnt, auch bei inhaltlichen Unsicherheiten einfach ?rma zu konsultieren. Dadurch, dass diese Funktion für so viele Varianten der Meta-Analyse gleichzeitig ausgelegt ist, sind die Argumente allerdings ein wenig einschüchternd, wenn man sie das erste Mal sieht. Für uns sind zunächst nur vier Argumente relevant:
yi: Die Effektschätzer (in unserem Fall die Variablees)vi: Die Stichprobenvariabilität, also das Quadrat des Standardfehlers (in unserem Fall die Variablev)data: Der Datensatz, in dem die Effekte und ihre Varianzen gespeichert sind (hier zunächstpost)method: Der Ansatz, mit dem wir die Effekte analysieren wollen
Für den Fixed-Effects-Ansatz setzen wir method = 'FE' und können dann die Effekte schätzen lassen:
# Fixed Effects Model (Post Erhebungen)
modFE <- rma(yi = es, vi = v, data = post, method = 'FE')
# Ergebnisse
summary(modFE)
##
## Fixed-Effects Model (k = 48)
##
## logLik deviance AIC BIC AICc
## -228.7385 507.9046 459.4771 461.3483 459.5640
##
## I^2 (total heterogeneity / total variability): 90.75%
## H^2 (total variability / sampling variability): 10.81
##
## Test for Heterogeneity:
## Q(df = 47) = 507.9046, p-val < .0001
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## 0.2609 0.0198 13.1608 <.0001 0.2220 0.2997 ***
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Fixed-Effects Model (k = 48)
zeigt uns, dass wir $k = 48$ Studien analysiert haben.
## logLik deviance AIC BIC AICc
## -228.7385 507.9046 459.4771 461.3483 459.5640
sind Modell-Fit Ergebnisse. Das Modell wurde mit der Maximum-Likelihood (ML)-Methode geschätzt, weswegen wir unsere alten Bekannten, die Log-Liklihood (logLik), die Devianz (deviance), sowie weitere Informationskriterien (AIC, BIC, AICc) ausgegeben bekommen (die gleichen Maße hatten wir z.B. bei der logistischen Regression und den gemischten Modellen schon gesehen).
## I^2 (total heterogeneity / total variability): 90.75%
## H^2 (total variability / sampling variability): 10.81
sind Heterogenitätsmaße. Sie beschreiben, wie viel der Variation der Studienergebnisse durch mögliche Subpopulationen zu stande gekommen sind. $I^2$ ist ein häufig berichtetes Maß, welches den Anteil an der Gesamtvariation der Effektstärken schätzt, die durch Heterogenität zwischen den Studien resultiert. Wir sehen hier also, dass ein substantieller Teil durch die Unterschiede zwischen den Studien und ein vergleichsweise geringfügiger Anteil (die restlichen Prozent) durch Unterschiede zwischen Personen innerhalb der Studien zustande kommt. Inhaltlich ist dieses Maß mit der ICC vergleichbar, die wir bei den gemischten Modellen detailliert besprochen hatten.
Diese Heterogenität wird hier auf Signifikanz geprüft mithilfe von Cochran’s $Q$.
## Test for Heterogeneity:
## Q(df = 47) = 507.9046, p-val < .0001
Wie immer wird unter Model Results eine Übersicht über die Parameterschätzung gegeben (estimate = Schätzung, se = Standarfehler, zval = zugehöriger $z$-Wert, pval = zugehöriger $p$-Wert und abschließend die Grenzen des Konfidenzintveralls ci.lb, ci.ub). Da wir hier nur den mittleren Effekt der Intervention schätzen, wird nur ein Parameter ausgegeben:
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## 0.2609 0.0198 13.1608 <.0001 0.2220 0.2997 ***
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Zum Glück kommen wir hier auf das gleiche Ergebnis, wie in unserer händischen Berechnung.
Random Effects Model
Wie wir gerade anhand von Cochran’s $Q$ gesehen haben, sprechen die Daten für Effektheterogenität. Im letzten Abschnitt sind wir davon ausgegangen, dass es einen wahren Effekt der Intervention bei Gaming Disorder gibt und dass dieser in jeder Studie durch Zufallsschwankungen ein wenig unter- oder überschätzt wird:
$$ \hat{\theta}_k = \theta + \epsilon_k $$
Wenn wir ein wenig in uns gehen, scheint diese Annahme aber ziemlich … gewagt. In jeder Studie werden unterschiedliche Bedingungen für unterschiedliche Personen geschaffen, um mitunter unterschiedliche Interventionsansätze zu evaluieren. Man könnte durchaus annehmen, dass selbst dann, wenn wir zwei Forschungsgruppen ein unendliches Budget und eine unendliche Stichprobengröße zur Verfügung stellen würden, die Untersuchungsdesigns so unterschiedlich wären, dass mindestens etwas unterschiedliche Effekte untersucht würden.
Dieser Tatsache wird im Random-Effects-Model durch einen studienspezifischen Effekt $\vartheta_i$ Rechnung getragen:
$$ \hat{\theta}_k = \theta + \vartheta_k + \epsilon_k $$
Die Aussage ist jetzt also, dass sich der Effektschätzer aus der Studie $k$ aus drei Komponenten zusammensetzt: dem globalen Effekt der Intervention ($\theta$), der studienspezifischen Abweichung im Effekt ($\vartheta_k$) und der Zufallsschwankung ($\epsilon_k$). Die Varianz von $\vartheta_i$ wird als Heterogenitätsvarianz bezeichnet und häufig mit $\tau^2$ beschrieben.
Letztlich sind die Varianzen von $\varepsilon_i$ und $\vartheta_i$ konzeptuell das Gleiche, das wir bei der Varianzzerlegung in den gemischten Modellen gesehen haben. Wenn wir die Gewichtung für die Schätzung des mittleren Effekts für das Random-Effects-Model erweitern, müssen wir zusätzlich zur Stichprobenschwankung ($v_k$, der quadrierte Standardfehler) auch die Schwankung der Effekte zwischen den Studien ($\tau^2$) berücksichtigen:
$$ w_k = \frac{1}{v_k + \tau^2} $$
Da wir bereits wissen, dass wir die mittleren Effekte nicht händisch bestimmen müssen, überspringen wir an dieser Stelle mal den Spannungsaufbau und kommen direkt zur Umsetzung in metafor.
Wie vorhin nutzen wir für die Analyse erneut die rma-Funktion. Der einzige Unterschied besteht darin, dass wir jetzt nicht mehr mit method = 'FE' das Fixed-Effects-Model annehmen, sondern die voreingestellte Schätzung des Random-Effects-Models verwenden:
# Random Effects Model (Post Erhebungen)
modRE <- rma(yi = es, vi = v, data = post)
# Zusammenfassung der Ergebnisse
summary(modRE)
##
## Random-Effects Model (k = 48; tau^2 estimator: REML)
##
## logLik deviance AIC BIC AICc
## -56.1646 112.3292 116.3292 120.0295 116.6019
##
## tau^2 (estimated amount of total heterogeneity): 0.3682 (SE = 0.0919)
## tau (square root of estimated tau^2 value): 0.6068
## I^2 (total heterogeneity / total variability): 94.69%
## H^2 (total variability / sampling variability): 18.83
##
## Test for Heterogeneity:
## Q(df = 47) = 507.9046, p-val < .0001
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## 0.6886 0.0968 7.1122 <.0001 0.4988 0.8783 ***
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Gegenüber dem vorherigen Output kommt hier eine Schätzung für $\tau^2$ (also die Varianz der Studieneffekte) hinzu. Auch die restlichen Schätzer verändern sich (z.B. $I^2$). In diesem Fall fällt besonders auf, dass die Schätzung des mittleren Effekts sich erneut drastisch verändert und von 0.26 auf 0.69 springt. Wenn Sie eine “kurze” Begründung dafür interessiert, klappen Sie gerne den nächsten Abschnitt auf.
Warum ändert sich der Effekt?
Im Fixed-Effects-Model hatten wir gesagt, dass wir durch die Gewichtung mit der Stichprobenvariabilität ($SE(\hat{\theta})^2$ oder auch $v_k$) die Effekte von kleineren Studien in der Bestimmung des mittleren Effekts niedriger gewichten wollen. Das ist prinzipiell dann sinnvoll, wenn wir davon ausgehen, dass es eine Varianzquelle (die Stichprobenschwankung) gibt.Bei einer Studie entsteht der berichtete Effekt $\hat\theta$, theoretisch betrachtet, dadurch, dass wir aus einer der Normalverteilung $\mathcal{N} \sim (\theta, v_k)$ aller möglichen Ausgänge dieser Studie eine gezogen haben. Dabei ist $v_k = \frac{\sigma^2}{n_k}$, hängt also von der Streuung des Merkmals in der Population der Individuen (aller Personen, die an einer Intervention teilnehmen könnten) und der Stichprobengröße ab.
Wenn wir eine andere Studie mit einem anderen $n_k$ durchführen, ziehen wir aus einer Verteilung mit einer anderen Streuung, aber dem gleichen Mittelwert, weil der Effekt der Intervention für alle Studien gleich sein sollte.
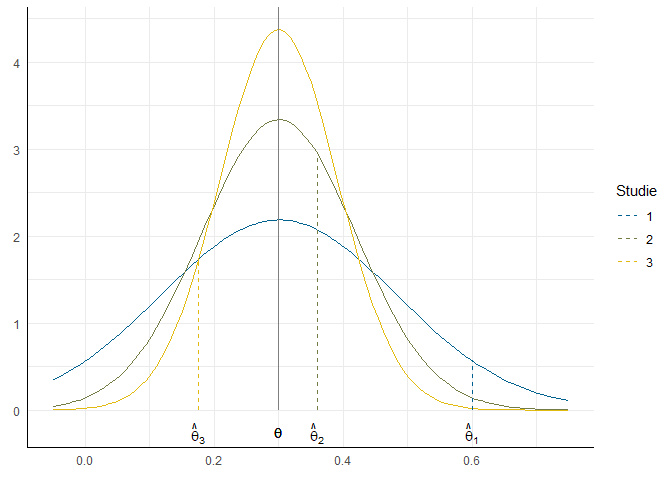
Da die Effekte kleinerer Stichproben stärker schwanken und daher per Zufall häufiger weiter vom wahren Effekt entfernt liegen, sollten wir sie bei der Berechnung des wahren Effekts gegenüber größeren Stichproben auch weniger stark gewichten (genau genommen mit $w_k = \frac{1}{v_k}$).
Im Random-Effects-Model wird im Gegensatz zu diesem Fall jedoch ein zweischrittiges Samplingverfahren angenommen. Es gibt eine Verteilung möglicher Effekte, die in Studien gefunden werden könnten:
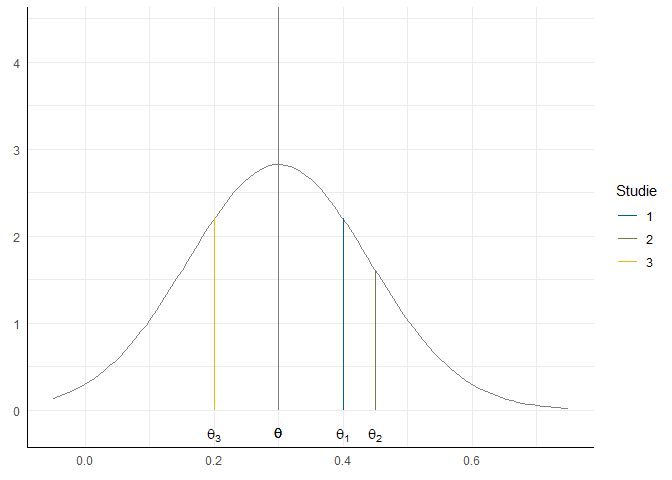
Wenn wir nun die drei Studien mit unterschiedlichen Stichprobengrößen durchführen, ziehen wir aus diesen Verteilungen mit jeweils unterschiedlichen Erwartungswerten:
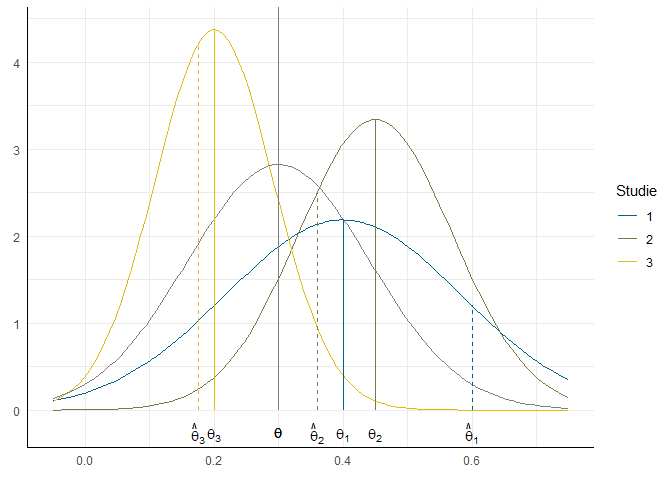
Dabei entsteht also eine Gewichtung sowohl über die Stichprobenvariation als auch über die Heterogenität der Effekte (graue Verteilung), also
$$ w_k = \frac{1}{v_i + \tau^2} $$
Da immer gilt, dass $\tau^2 \geq 0$, fällt in diesem Ansatz die Schwankung durch die Stichprobengröße weniger ins Gewicht als beim Fixed-Effects-Model, sodass hier kleineren Stichproben wieder mehr Einfluss auf die Schätzung des Gesamteffekts zugestanden wird.
Modelldiagnostik
Wie bei allen statistischen Verfahren (insbesondere den regressionsbasierten) ist es wünschenswert, die Daten etwas genauer anzusehen, bevor die Ergebnisse interpretiert und berichtet werden. Klassischerweise gehört dazu die Modelldiagnostik, wie wir sie z. B. bei der linearen Regression schon im Bachelor besprochen haben.
Die dort verwendeten Befehle cooks.distance und hatvalues können auch für Ergebnisse aus dem metafor-Paket verwendet werden. Allerdings liefert die influence-Funktion direkt eine Zusammenfassung verschiedener Diagnosemaße:
# Diagnosemaße
diagnostics <- influence(modRE)
In diagnostics sind jetzt verschiedene Maße für jede Studie enthalten. Wie in eigentlich allen Belangen liefert auch hier die fantastische Dokumentation des metafor-Pakets eine Übersicht und diverse Literaturhinweise bezüglich der Interpretation und Anwendung der Maße: ?influence.rma.uni.
In der Meta-Analyse der Gaming Disorder Interventionen schreiben Danielsen et al. (2024, S. 6):
A Cook’s distance diagnostic (Cook & Weisberg, 1982; Viechtbauer & Cheung, 2010) was run on the intercept model to check for outliers. By visually scanning the plot (Fig. 4), we detected and excluded the outlier which had an effect size of 6.30 (Kochuchakkalackal Kuriala & Reyes, 2020).
Da die tabellarische Darstellung solcher Werte für die meisten etwas ermüdend erscheint, schauen wir uns die Cook’s Distanz grafisch an. Dafür können wir einen ggplot verwenden:
# Zusammenführen der Diagnosemaße und Studieninformationen
diagnostics <- data.frame(cite = post$cite, es = post$es,
diagnostics$inf)
# ggplot
ggplot(diagnostics, aes(y = cite, x = cook.d)) +
geom_point() +
labs(x = 'Cook\'s Distanz', y = 'Studie') +
theme_pandar()
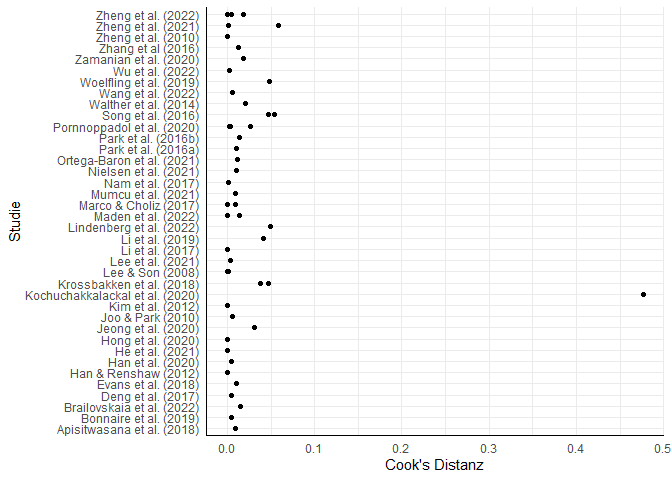
Wie Danielsen et al. (2024) berichten, fällt die Studie von Kochuchakkalackal Kuriala und Reyes (2020) hier auf. Dort wurde eine Effektstärke von 6.3 festgestellt, und auch wenn wir an dieser Stelle gerne glauben möchten, dass in dieser Studie das Wundermittel entdeckt wurde, deutet die Bias-Analyse von Danielsen et al. (2024, S. 9) darauf hin, dass diese Effektschätzung mit Vorsicht genossen werden sollte.
Um die Studie von Kochuchakkalackal Kuriala und Reyes (2020) auszuschließen, entfernen wir diese zunächst aus dem post-Datensatz und aktualisieren dann unsere beiden meta-analytischen Modelle mit der update-Funktion:
# Ausreißer entfernen
post <- post[post$study != 15, ]
# Fixed Effects Model
modFE <- update(modFE, data = post)
# Random Effects Model
modRE <- update(modRE, data = post)
Abbildung der Effekte
Eine eingängige Möglichkeit, um einen Überblick über die gesammelten Informationen bezüglich der Interventionseffekte bei Gaming Disorder zu bekommen, ist die Verwendung eines Forest Plots. In Abbildung 5 (S. 11) ist auch bei Danielsen et al. (2024) genau so ein Plot zu sehen.
Im metafor-Paket gibt es dafür die forest-Funktion, welche für die Umsetzung mit geschätzten Modellen unter ?forest.rma dokumentiert ist.
Die meisten Voreinstellungen entsprechen bereits unserer Vorstellung davon, wie das Ganze aussehen sollte: Die Schätzer und Konfidenzintervalle der Effekte werden in der Grafik abgebildet, die Ergebnisse der Modellschätzung werden einbezogen und die Nulllinie wird zur Orientierung eingefügt. Darüber hinaus könnte noch slab (für study label) sinnvoll sein, um statt einer Nummerierung eine Benennung der einzelnen Studien zu erhalten.
Außerdem wurde z. B. bei Danielsen et al. (2024) die Darstellung nach der Größe des Effekts sortiert (order = post$es). Um die Ergebnisse etwas übersichtlicher zu machen, nutzen wir hier außerdem shade = TRUE, um jede zweite Zeile etwas einzufärben:
# Forest Plot
forest(modRE, slab = post$cite, order = post$es,
shade = TRUE)
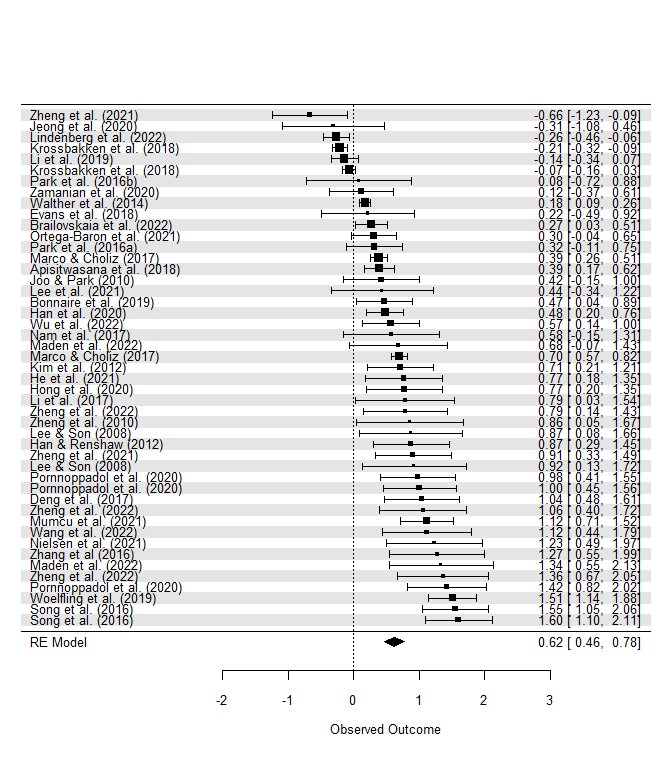
Die Abbildung enthält für jede Studie die Schätzung der Effektstärke (das Quadrat) und das dazugehörige 95%-Konfidenzintervall. Rechts stehen diese Informationen noch einmal als Zahlen. Die Größe des Quadrats der Effektstärke hängt von der Gewichtung der Studie (also der inversen Stichprobenvariabilität) ab. Ganz unten sehen wir die Schätzung des Gesamteffekts aus dem Random-Effects-Model. Die Enden dieses Karos zeigen die Grenzen des Konfidenzintervalls an. Durch addpoly(modFE) könnten wir in dieser Abbildung auch die Ergebnisse des Fixed-Effects-Models nachtragen lassen. Darüber hinaus können wir diverse optische Eigenschaften des Plots ändern, z. B. können wir mit dem colout-Argument die einzelnen Studien nach der Art der Intervention einfärben:
# Farben für Interventionstyp
colors <- factor(post$tr_type,
labels = pandar_colors[1:4]) |> as.character()
# Forest Plot
forest(modRE, slab = post$cite, order = post$es,
colout = colors)
# Legende hinzufügen
legend('bottomleft', legend = levels(factor(post$tr_type)),
fill = pandar_colors[1:4],
cex = .75)
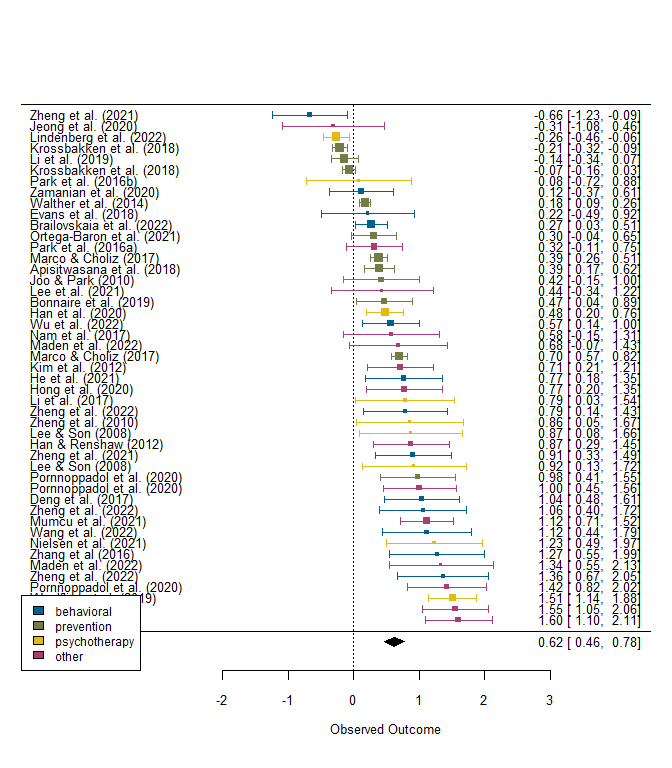
Die Setzung der Legende ist alles andere als perfekt und hängt leider von der Bildschirmauflösung und der Größe des Grafikfensters ab, sodass es hier nötig wird, extrem detailliert vorzugehen, um eine druckreife Abbildung zu erzeugen. Was sich allerdings schon deskriptiv erkennen lässt, ist, dass Präventionsmaßnahmen (erwartungsgemäß) geringere Effekte aufzeigen als die Interventionseffekte.
Meta-Regression
Nachdem wir es nun geschafft haben, die Effekte zusammenzutragen und uns ein relativ realistisches Bild von der Studienlage bezüglich der Interventionen bei Gaming Disorder zu machen, schauen wir noch einmal auf die drei Fragen, mit denen Danielsen et al. (2024) ihre Meta-Analyse angetreten hatten:
Do therapeutic interventions decrease symptoms in patients with gaming disorder?
Does effectiveness of different therapeutic interventions vary in patients with gaming disorder?
Does the effect size vary by how the outcome is measured?
Zumindest auf die erste Frage konnten wir eine Antwort finden, denn im Random-Effects-Model hatten wir einen bedeutsamen Effekt identifiziert. Die beiden weiteren Fragen beziehen sich darauf, ob Unterschiede in den Effekten durch Eigenschaften der Studie erklärt werden können.
Da das Random-Effects-Model letztlich ein spezielles gemischtes Modell ist, können wir einfach Prädiktoren in das Modell aufnehmen.
In rma können wir mit dem Argument mods diese Moderatorvariablen aufnehmen. Sie werden hier Moderatoren genannt, obwohl wir nicht explizit Interaktionen modellieren, da unsere abhängige Variable ja bereits einen Effekt – in unserem Fall den Unterschied zwischen Interventions- und Kontrollgruppe – abbildet. Weil dieser Effekt von Eigenschaften der Studie abhängen kann, wird der Interventionseffekt also potenziell moderiert.
Danielsen et al. (2024) haben sich in ihren Analysen dazu entschieden, die beiden Hypothesen separat zu bearbeiten, auch wenn es generell empfehlenswert ist, alle potenziellen Moderatoren in einem Modell zu berücksichtigen, um so potenzielle Konfundierungen der Effekte zu vermeiden. Wir orientieren uns hier an der ursprünglichen Studie und nehmen zunächst nur den Interventionstyp auf.
Im mods-Argument kann mit der üblichen Formelnotation von R gearbeitet werden. Da die abhängige Variable durch das yi-Argument schon festgelegt ist, bleibt die linke Seite der Formel leer, sodass hier immer ~ UV1 + UV2 + UV3... stehen kann.
# Meta-Regression
modMR1 <- rma(yi = es, vi = v, data = post, mods = ~ tr_type)
# Ergebnissdarstellung
summary(modMR1)
##
## Mixed-Effects Model (k = 47; tau^2 estimator: REML)
##
## logLik deviance AIC BIC AICc
## -32.0575 64.1151 74.1151 82.9211 75.7367
##
## tau^2 (estimated amount of residual heterogeneity): 0.1861 (SE = 0.0547)
## tau (square root of estimated tau^2 value): 0.4314
## I^2 (residual heterogeneity / unaccounted variability): 90.08%
## H^2 (unaccounted variability / sampling variability): 10.08
## R^2 (amount of heterogeneity accounted for): 19.40%
##
## Test for Residual Heterogeneity:
## QE(df = 43) = 340.8010, p-val < .0001
##
## Test of Moderators (coefficients 2:4):
## QM(df = 3) = 9.6763, p-val = 0.0215
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## intrcpt 0.6473 0.1451 4.4597 <.0001 0.3628 0.9317 ***
## tr_typeprevention -0.3617 0.2000 -1.8080 0.0706 -0.7537 0.0304 .
## tr_typepsychotherapy 0.0325 0.2291 0.1418 0.8873 -0.4165 0.4815
## tr_typeother 0.2423 0.2027 1.1956 0.2318 -0.1549 0.6396
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Bevor wir uns die Mühe machen, die detaillierten Ergebnisse zu interpretieren, können wir zunächst prüfen, ob die Art des Interventionsansatzes generell relevant ist. Dafür könnten wir, wie z. B. im Beitrag zu den gemischten Modellen besprochen, einen Likelihood-Ratio-Test nutzen. Allerdings wird in Meta-Analysen empfohlen, stattdessen den Omnibus-Test $Q_m$ zu nutzen, welcher hier direkt von metafor mit ausgegeben wird (Test of Moderators). Der Test spricht hier dafür, dass es zumindest irgendeinen Effekt der Interventionsart gibt:
## Test of Moderators (coefficients 2:4):
## QM(df = 3) = 9.6763, p-val = 0.0215
Die zweite Forschungsfrage
Does effectiveness of different therapeutic interventions vary in patients with gaming disorder?
können wir also schon jetzt mit “ja” beantworten. Neben diesem Test gibt die summary auch das $R^2$ aus, welches uns dabei helfen könnte, das Ausmaß der Relevanz dieses Moderators zu beurteilen:
## R^2 (amount of heterogeneity accounted for): 19.40%
Wie die Beschriftung hier noch einmal verdeutlichen soll, können wir mit solchen Moderatoren nur die Variation zwischen den Studien aufklären. Unterschiede in den Effekte zwischen Personen würden - naheliegenderweise - auch Daten von Einzelpersonen erfordern.
Weil sich herausgestellt hat, dass wir uns die Mühe machen müssen, die Ergebnisse genauer zu inspizieren, gucken wir noch einmal in die Ergebnistabelle:
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## intrcpt 0.6473 0.1451 4.4597 <.0001 0.3628 0.9317 ***
## tr_typeprevention -0.3617 0.2000 -1.8080 0.0706 -0.7537 0.0304 .
## tr_typepsychotherapy 0.0325 0.2291 0.1418 0.8873 -0.4165 0.4815
## tr_typeother 0.2423 0.2027 1.1956 0.2318 -0.1549 0.6396
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Wie in Tabelle 3 (S. 7) von Danielsen et al. (2024) dargestellt, wurden die Interventionsansätze zu vier Oberkategorien zusammengefasst:
# Interventionsarten
table(post$tr_type)
##
## behavioral prevention psychotherapy other
## 13 11 9 14
Da es sich hier also um eine 4-stufige, nominalskalierte Variable handelt, wird diese in die Dummykodierung überführt und die erste Kategorie als Referenzkategorie gesetzt. Das intrcpt stellt also den vorhergesagten Effekt für Studien dar, in denen eine Verhaltensintervention (behavioral) durchgeführt wurde.
Nach Danielsen et al. (2024) sind solche Interventionen:
abstinence, craving behavioral intervention (CBI), or a kind of response inhibition training using computer tasks
Die drei Regressionsgewichte stellen hier den Unterschied zwischen diesen Ansätzen und dem jeweiligen Vergleich (also z. B. Prävention) dar.
Das heißt, dass die Schätzung der Effekte von Präventionen aus Intercept und Regressionsgewicht als
$$ \beta_0 + \beta_1 = 0.65 -0.36 = 0.29 $$
zusammengesetzt werden muss.
Wenn wir die Ansätze nicht vergleichen wollen, sondern stattdessen mehr daran interessiert sind, wie die einzelnen Interventionsansätze gegenüber den jeweiligen Kontrollgruppen abschneiden, können wir das Intercept unterdrücken und stattdessen alle vier Kategorien in die Regression aufnehmen:
# Meta-Regression
modMR1b <- rma(yi = es, vi = v, data = post, mods = ~ 0 + tr_type)
# Ergebnissdarstellung
summary(modMR1b)
##
## Mixed-Effects Model (k = 47; tau^2 estimator: REML)
##
## logLik deviance AIC BIC AICc
## -32.0575 64.1151 74.1151 82.9211 75.7367
##
## tau^2 (estimated amount of residual heterogeneity): 0.1861 (SE = 0.0547)
## tau (square root of estimated tau^2 value): 0.4314
## I^2 (residual heterogeneity / unaccounted variability): 90.08%
## H^2 (unaccounted variability / sampling variability): 10.08
##
## Test for Residual Heterogeneity:
## QE(df = 43) = 340.8010, p-val < .0001
##
## Test of Moderators (coefficients 1:4):
## QM(df = 4) = 78.4394, p-val < .0001
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## tr_typebehavioral 0.6473 0.1451 4.4597 <.0001 0.3628 0.9317 ***
## tr_typeprevention 0.2856 0.1376 2.0749 0.0380 0.0158 0.5554 *
## tr_typepsychotherapy 0.6797 0.1772 3.8352 0.0001 0.3324 1.0271 ***
## tr_typeother 0.8896 0.1415 6.2878 <.0001 0.6123 1.1669 ***
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Wie wir in der summary sehen können, sind beide Modelle hinsichtlich der Passung identisch – sie sind lediglich eine Umformulierung voneinander. Wir sehen hier, dass alle drei Interventionsarten bedeutsame Effekte erzeugen – statistisch signifikante Effekte bleiben lediglich bei Präventionen aus. Das ist nicht weiter verwunderlich, wenn man bedenkt, dass wir hier die Messung der Effekte direkt nach Durchführung der Maßnahmen betrachten – Präventionen sind jedoch meist darauf angelegt, langfristig die Entstehung von Problemen zu verhindern.
Kovariaten
Im Artikel von Danielsen et al. (2024) wird unter anderem erwähnt, dass die Effekte auf den relativen Anteil der männlichen Studienteilnehmer kontrolliert werden sollen, um potenzielle Verzerrungen (z. B. zu Ungunsten von Breitband-Präventionen) zu vermeiden. Wie bereits erwähnt, können wir Kovariaten einfach in der Formelnotation im mods-Argument aufnehmen. Damit die Effekte der Interventionen als Effekte bei Geschlechtergleichverteilung interpretiert werden können, wurde (laut Analyseskript auf OSF) vom Anteil der Wert 50 abgezogen. (Bitte beachten Sie, dass diese Variable entgegen der Aussage auf S. 10 im Artikel nicht zentriert wurde.)
# Umrechnen der Geschlechtervariable
post$genbal <- post$male - 50
# Meta-Regression mit Kovariate
modMR2 <- rma(yi = es, vi = v, data = post, mods = ~ 0 + tr_type + genbal)
## Warning: 9 studies with NAs omitted from model fitting.
Noch bevor wir uns die Ergebnisse ansehen, werden wir hier direkt mit einer Gefahr der Kovariatenaufnahme konfrontiert. In diese Analyse können nur Studien aufgenommen werden, die die Geschlechterverteilung berichten. In diesem Fall bedeutet das, dass wir gegenüber der vorherigen Analyse 9 Effekte verlieren. Es ist daher besonders wichtig, bei solchen Analysen darauf zu achten, dass nur relevante Kovariaten explizit betrachtet werden und gegebenenfalls die Autor*innen kontaktiert werden müssen, um solche Zusatzinformationen zu erhalten – wobei sie häufig nicht antworten werden.
# Ergebniszusammenfassung
summary(modMR2)
##
## Mixed-Effects Model (k = 38; tau^2 estimator: REML)
##
## logLik deviance AIC BIC AICc
## -20.5119 41.0238 53.0238 62.0029 56.2546
##
## tau^2 (estimated amount of residual heterogeneity): 0.1329 (SE = 0.0483)
## tau (square root of estimated tau^2 value): 0.3645
## I^2 (residual heterogeneity / unaccounted variability): 83.73%
## H^2 (unaccounted variability / sampling variability): 6.15
##
## Test for Residual Heterogeneity:
## QE(df = 33) = 177.9587, p-val < .0001
##
## Test of Moderators (coefficients 1:5):
## QM(df = 5) = 103.1853, p-val < .0001
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## tr_typebehavioral 0.4340 0.2094 2.0730 0.0382 0.0237 0.8444 *
## tr_typeprevention 0.3562 0.1334 2.6707 0.0076 0.0948 0.6176 **
## tr_typepsychotherapy 0.2262 0.2337 0.9678 0.3331 -0.2319 0.6843
## tr_typeother 0.4684 0.2208 2.1210 0.0339 0.0356 0.9012 *
## genbal 0.0106 0.0042 2.5103 0.0121 0.0023 0.0188 *
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Wir sehen, dass in diesem Fall die Effekte der Interventionen gegenüber der unbedingten Effektschätzung ein wenig schrumpfen, die der Präventionen jedoch steigen. Insbesondere ist beachtenswert, dass der durchschnittliche Effekt von Präventionen bei Geschlechtergleichverteilung statistisch bedeutsam ist, der von psychotherapeutischen Ansätzen jedoch nicht. Wie den Ergebnissen zu entnehmen ist, liegt dies jedoch trotz gleicher Effektstärke wahrscheinlich an der geringeren Power der psychotherapeutischen Studien. Der Effekt der Kovariate ist ebenfalls statistisch bedeutsam und zeigt, dass die Effektschätzung in einer Studie pro Prozentpunkt des Anteils männlicher Teilnehmer um ca. 0.01 in der standardisierten Mittelwertsdifferenz zunimmt.
Multilevel Meta-Analysen
In den bisherigen Analysen haben wir nur einen Teil der tatsächlich berichteten Ergebnisse untersucht. Zu Beginn hatten wir uns auf diejenigen Effekte beschränkt, die den ersten Messzeitpunkt nach der Intervention darstellen.
Wenn wir alle Informationen berücksichtigen wollen, die wir erhalten können, macht es Sinn, die wiederholten Messungen der Effekte in die Analyse einzubeziehen. Dadurch entsteht eine weitere Ebene der Abhängigkeit in unseren Daten, da wir nun zusätzlich die Messwiederholungen berücksichtigen müssen.
Zum Glück ist es sehr üblich, dass Studien die gleichen Effekte mehrfach untersuchen (gerade im Rahmen der Psychotherapieforschung ist das klassische Pre/Post/Follow-Up-Design sehr gängig), sodass auch die Umsetzung zu den Standards in metafor gehört. Die Funktion rma.mv bietet hierfür beinahe alles, was wir benötigen.
Damit klar ist, welche Effekte zu welcher Studie gehören, brauchen wir zwei ID-Variablen: eine für jede Studie (im Datensatz study) und eine für jeden Effekt in dieser Studie (im Datensatz effect).
Damit wir alle Effekte berücksichtigen können, arbeiten wir jetzt nicht mehr mit dem eingeschränkten Datensatz, sondern mit dem vollständigen game-Datensatz.
Zunächst schließen wir die Studie von Kochuchakkalackal Kuriala und Reyes (2020) wieder aus – die gleiche Diagnostik, die wir oben durchgeführt haben, signalisiert auch in diesem Fall Bedenken hinsichtlich der Effektschätzung aus dieser Studie.
# Ausreißer entfernen
game <- game[game$study != 15, ]
In Meta-Analysen, in denen sehr viele unterschiedliche Konstellationen von Messzeitpunkten, Outcomes und Interventionsansätzen innerhalb der untersuchten Studien genutzt werden, kann es nötig sein, zu berücksichtigen, dass die Standardfehler und Effektschätzungen innerhalb der einzelnen Studien zusätzlich korreliert sind. Danielsen et al. (2024) berufen sich dabei auf die Empfehlung von Pustejovsky und Tipton (2022), die für solche Fälle einen robusten Schätzer empfehlen. Dieser wird dadurch erzielt, dass wir die Abhängigkeiten der Standardfehler in einer Kovarianzmatrix festhalten, die wir mithilfe des clubSandwich-Pakets schätzen können:
# Paket laden
library(clubSandwich)
# Geschätzte CHE Kovarianzmatrix
V <- impute_covariance_matrix(
game$v,
cluster = game$study,
r = .6,
smooth_vi = TRUE)
Die genauen Hintergründe dieser Schätzung gehen über die Inhalte dieses Beitrags ein bisschen hinaus, aber der Artikel von Pustejovsky und Tipton (2022) bietet sowohl eine gute Übersicht, als auch einen praktischen Entscheidungsbaum für die eigene Meta-Analyse. Mit dieser Kovarianzmatrix können wir jetzt die multilevel Meta-Analyse durchführen:
# Multilevel Meta-Analyse
modML <- rma.mv(yi = es, V = V, data = game,
random = ~ 1 | study/effect)
In der rma.mv Funktion ist wenig anders, als in den Anwendungen der rma, die wir bisher genutzt haben. Statt vi heißt das Argument für die Sitchprobenvariabilität jetzt V, weil es nicht mehr zwingend einfach die einzelnen Varianzen für jeden Effekt darstellt, sondern auch eine Kovarianzmatrix von Stichprobenschwankungen sein kann. Im random-Argument halten wir die bereits erwähnte Schachtelung der Effekte in Studien fest. Hierbei bedeutet die Angaben ~ 1 | study/effect soviel wie “das Intercept schwankt über die Studien und die darin befindlichen Einzeleffekte hinweg”.
# Ergebnissdarstellung
summary(modML)
##
## Multivariate Meta-Analysis Model (k = 75; method: REML)
##
## logLik Deviance AIC BIC AICc
## -39.3933 78.7865 84.7865 91.6987 85.1294
##
## Variance Components:
##
## estim sqrt nlvls fixed factor
## sigma^2.1 0.1498 0.3871 37 no study
## sigma^2.2 0.0418 0.2044 75 no study/effect
##
## Test for Heterogeneity:
## Q(df = 74) = 455.4486, p-val < .0001
##
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## 0.5552 0.0802 6.9231 <.0001 0.3980 0.7124 ***
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Der geschätzte mittlere Effekt entspricht (mit Abweichungen in der dritten Nachkommastelle des Konfidenzintervalls) dem, was Danielsen et al. (2024) in Tabelle 2 berichten. In der Ergebniszusammenfassung erhalten wir jetzt aufgrund der zusätzlichen Komplexität der Variabilitätszusammensetzung keine einfachen Schätzer für $I^2$ oder den prozentualen Anteil der Schwankung innerhalb vs. zwischen den Studien.
Stattdessen erhalten wir zwei Varianzschätzer.
- Zwischen den Studien ist eine Varianz von $0.15$ zu beobachten.
- Innerhalb der Studien fällt die Varianz mit $0.04$ deutlich geringer aus – es sind also mehr Unterschiede zwischen den Studien als innerhalb der Studien (über verschiedene Interventionsansätze und Zeitabstände hinweg) zu beobachten.
Natürlich sollten wir bei diesen Effekten aber berücksichtigen, dass sie mit zum Teil dramatisch unterschiedlichem Abstand zur Intervention erhoben wurden. Darüber hinaus können wir erneut die Geschlechterverteilung berücksichtigen, um so beide von Danielsen et al. (2024) berücksichtigten Kovariaten im Modell zu haben. Schauen wir uns das Modell für die Untersuchung verschiedener Interventionsarten an:
# Gender-Balance Variable erstellen
game$genbal <- game$male - 50
# ML Meta-Regression
modML2 <- rma.mv(yi = es, V = v, data = game,
random = ~ 1 | study/effect,
mods = ~ 0 + tr_type + genbal + follow)
## Warning: 12 rows with NAs omitted from model fitting.
# Ergebnissdarstellung
summary(modML2)
## Model Results:
##
## estimate se zval pval ci.lb ci.ub
## tr_typebehavioral 0.4189 0.1909 2.1936 0.0283 0.0446 0.7931 *
## tr_typeprevention 0.3391 0.1276 2.6585 0.0078 0.0891 0.5891 **
## tr_typepsychotherapy 0.3138 0.2093 1.4994 0.1338 -0.0964 0.7240
## tr_typeother 0.3733 0.1779 2.0979 0.0359 0.0245 0.7220 *
## genbal 0.0090 0.0037 2.4374 0.0148 0.0018 0.0162 *
## follow 0.0019 0.0022 0.8462 0.3975 -0.0025 0.0062
##
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Die (ein wenig gekürzte) Modellzusammenfassung zeigt uns hier die Effekte der unterschiedlichen Interventionsarten bei Nullausprägung der beiden Kovariaten. Das bedeutet, dass z. B. 0.34 der vorhergesagte Effekt einer Prävention in einer Studie mit 50 % männlichen Teilnehmern (genbal = 0) ist, wenn wir die Untersuchung direkt im Anschluss an die Umsetzung durchführen (follow = 0).
Falls Sie sich an dieser Stelle fragen, warum die Ergebnisse von denen abweichen, die in Tabelle 2 (S. 7) von Danielsen et al. (2024) berichtet werden: Ich kann es Ihnen auch nicht sagen. Auch mit den im OSF bereitgestellten Analyseskripten war ich nicht in der Lage, die berichteten Werte zu reproduzieren.
Tests für mehrere Kovariaten und Moderatoren
Die Ergebnisse aus dem letzten Modell haben uns zwar gezeigt, dass alle Variablen im Modell (Interventionsart, Geschlechterverteilung und Messzeitpunkt) gemeinsam bedeutsam sind und dass jede der Interventionsarten an sich einen Effekt hat. Aber wir können per Omnibustest auch global testen, ob der eigentliche Moderator unter Kontrolle der Kovariaten einen bedeutsamen Effekt hat. Das Ergebnis mag am Ende zwar wenig überraschend sein, aber an sich ist es der korrekte Weg, die erste Forschungsfrage (“Sind bisherige Interventionen und Präventionen effektiv?”) mit einem inferenzstatistischen Test zu beantworten.
In metafor können wir den Omnibus-Test $Q_m$ dahingehend anpassen, dass er nur eine Auswahl der Koeffizienten gleichzeitig testet. Dafür können wir mit dem Argument btt (betas to test) auswählen, welche Parameter in den Test einbezogen werden sollen. Dafür können wir entweder die Zahlen der Parameter angeben, die wir testen möchten (in unserem Fall wären das 1:4), oder eine Benennung nutzen, nach der metafor selbst suchen soll (z. B. tr_type). Wichtig ist im letzteren Ansatz, dass dort dann alle Parameter eingeschlossen werden, in denen dieser Suchbegriff vorkommt.
Damit wir nicht das gesamte Modell erneut spezifizieren müssen, nutzen wir mal wieder update:
# Omnibus-Test der Interventionsarten
modML2b <- update(modML2, btt = 1:4)
## Warning: 12 rows with NAs omitted from model fitting.
# Ergebnissdarstellung
summary(modML2b)
## Test of Moderators (coefficients 1:4):
## QM(df = 4) = 10.2655, p-val = 0.0362
Getestet werden hier die Koeffizienten 1:4 (also die vier Interventionstypen) und das Ergebnis deutet darauf hin, dass es globale, statistisch bedeutsame Interventionseffekte gibt, wenn man auf die Geschlechterverteilung und den Messabstand als Kovariaten kontrolliert.
Publication Bias
Spätestens seit der Diskussion um die Replikationskrise ist deutlich geworden, in welchem Ausmaß die Ergebnisse der Forschungslandschaft durch das Verhalten von Autor*innen und Herausgeber*innen beeinflusst werden. Eine der Kategorien, die als Problemfeld identifiziert wurde, ist Publication Bias - also die Verzerrung des Gesamtbildes durch die selektive Veröffentlichung von bestimmten Ergebnissen.
Funnel Plot
Der bekannteste Ansatz, um zu prüfen, ob die Studienlage durch Publicationbias verzerrt sein könnte, ist der Funnel Plot. Die Grundidee ist dabei denkbar simpel. Wenn wir davon ausgehen, dass Studien mit kleinen Stichproben und nicht signifikanten Ergebnissen häufiger nicht veröffentlicht werden als andere Studien, können wir einfach die Effektstärke auf der $x$- und den Standardfehler auf der $y$-Achse abbilden. Sollten wir mit unserer Vermutung recht haben, sollte sich ein asymmetrisches Bild ergeben, bei dem unten (großer Standardhfehler) links (kleine bis negative Effekt) Punkte fehlen. In etwa so:
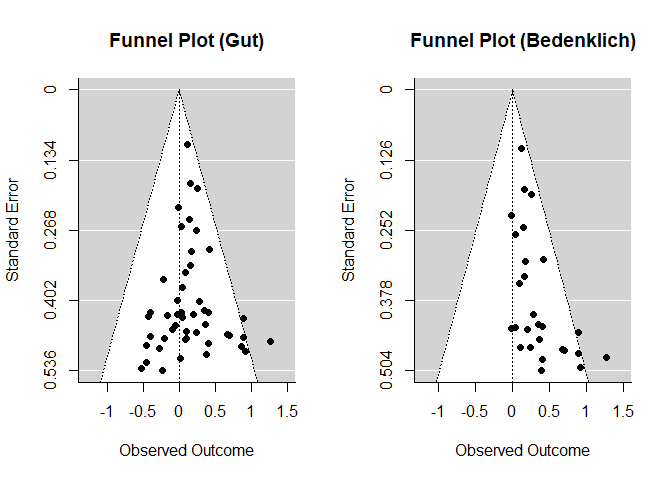
In der linken Grafik haben wir das erwartete Bild: Die Punkte streuen um einen gemeinsamen Effekt (entlang der $x$-Achse), wobei diese Streuung geringer wird, je kleiner der Standardfehler (also je größer die Stichprobe) der einzelnen Studie ist. In der rechten Grafik ergibt sich hingegen die Systematik, dass die Punkte der Studien mit größerem Standardfehler systematisch in eine Richtung streuen – nämlich in die, die für einen Effekt spricht.
Leider ist das Ganze nicht immer so eindeutig wie in diesem Beispiel, weswegen der “contour-enhanced” Funnel Plot empfohlen wird. Abbildung 6 von Danielsen et al. (2024) zeigt einen solchen Plot, den wir auch mit der metafor-Funktion funnel erstellen können:
# Funnel Plot
funnel(modML, # Modell mit unbedingten Effekten
refline = 0, # Ort der Referenzlinie
level = c(90, 95, 99), # Konfidenzintervalle
shade=c("white", "gray55", "gray75"), # Färbung der verschiendenn Bereiche
back = FALSE) # Hintergrundfarbe
abline(v = coef(modML)[1], lty = 2) # Geschätzter Interventionseffekt
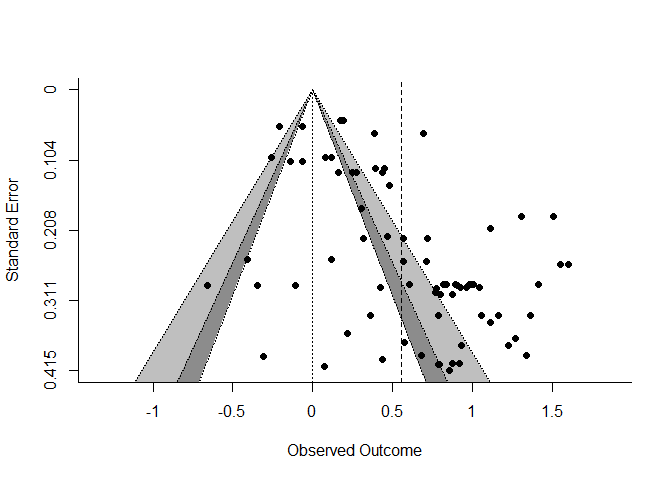
Gegenüber der klassischen Darstellung im Beispiel hat diese Art der Aufbereitung den Vorteil, dass es leichter fallen soll, optisch Publication Bias zu identifizieren. Wenn wir davon ausgehen, dass nicht signifikante Ergebnisse nicht veröffentlicht werden, sollte der weiße Bereich in der Mitte nahezu leer sein – dort wären Studien, deren Effekt auf dem $\alpha$-Fehlerniveau von 0.1 nicht bedeutsam geworden wäre. Ein Indikator für die Bedenklichkeit der Effekte wäre es, wenn besonders im hellgrauen Bereich sehr viele Studien zu finden wären. Das würde bedeuten, dass vor allem Studien veröffentlicht werden, die gerade so statistisch bedeutsam geworden sind.
Egger’s Test und PET-PEESE
Die optische Prüfung des Funnel Plots ist gegebenenfalls ein wenig zu subjektiv. Daher haben sich verschiedene Verfahren entwickelt, um zu prüfen, ob Publication Bias vorliegen könnte. Eine altbewährte Methode ist das sogenannte Trim-and-Fill, das allerdings in den vergangenen Jahren ein wenig aus der Mode geraten ist. Stattdessen werden meist regressionsbasierte Verfahren angewendet, in denen der Standardfehler als Prädiktor für den Effekt genutzt wird, um zu testen, ob die aufgedeckten Effekte lediglich durch übermäßig berichtete Effekte kleiner Stichproben zustande kommen. Diese sind in metafor unter der Funktion regtest zusammengefasst. Der bekannteste Test ist der Egger’s Test, welcher die Asymmetrie des Funnel Plots testet:
# Egger's Test + PET
regtest(es, v, data = game)
##
## Regression Test for Funnel Plot Asymmetry
##
## Model: mixed-effects meta-regression model
## Predictor: standard error
##
## Test for Funnel Plot Asymmetry: z = 4.4409, p < .0001
## Limit Estimate (as sei -> 0): b = 0.0734 (CI: -0.1639, 0.3107)
Wir sehen hier direkt eine Indikation dafür, dass die Ergebnisse der Studien asymmetrisch verteilt sind und zumindest irgendeine Form der Verzerrung vorliegen könnte. (Ob es sich dabei um Publication Bias handelt, ist damit nicht gesagt.) Das Limit Estimate gibt an, welcher Effekt bei einer Studie mit unendlicher Stichprobengröße erwartet wird und kann als Schätzer des “wahren” Effekts $\theta$ angesehen werden. Dieser Schätzer wird PET (precision-effect test) genannt und soll vor dem übermäßigen Einfluss kleiner Studien schützen. Sollte er von 0 verschieden sein (anders als hier), wird stattdessen der PEESE (precision-effect estimate with standard error) empfohlen, welcher statt des Standardfehlers als Prädiktor die Stichprobenvariabilität nutzt und somit kleine Stichproben noch stärker bestraft:
# PEESE
regtest(es, v, data = game, predictor = "vi")
##
## Regression Test for Funnel Plot Asymmetry
##
## Model: mixed-effects meta-regression model
## Predictor: sampling variance
##
## Test for Funnel Plot Asymmetry: z = 3.8248, p = 0.0001
## Limit Estimate (as vi -> 0): b = 0.2908 (CI: 0.1164, 0.4652)
Da in diesem Fall kein bedeutsamer PET-Effekt festgestellt wurde, würden wir im PET-PEESE-Prinzip davon ausgehen, dass die gefundenen Effekte wahrscheinlich nicht zuverlässig sind und durch die übermäßig berichteten signifikanten Ergebnisse kleiner Studien entstanden sind. Allerdings sei an dieser Stelle erwähnt, dass dieses Vorgehen anfällig ist, wenn wir wenige Studien in unsere Meta-Analyse einschließen oder die Effekte sehr heterogen sind. Aus diesem Grund wird häufig empfohlen, statt PET-PEESE die im folgenden Abschnitt geschilderten Ansätze zu nutzen. Aber da PET-PEESE insbesondere in klinischen Meta-Analysen immer häufiger zum Einsatz kommt, sollten Sie sich bewusst sein, dass es existiert und welche Bedeutung die Ergebnisse haben.
Abschluss
In diesem Beitrag sollte eine kurze Einführung in die Meta-Analyse von Interventionseffekten gegeben werden. Wir haben an der Meta-Analyse von Danielsen et al. (2024) gesehen, wie die statistischen Analyseschritte funktionieren (auch wenn wir nicht in allen Belangen in der Lage waren, die Ergebnisse zu reproduzieren). Bezüglich der ursprünglichen Fragestellung konnten aber auch wir feststellen, dass es sowohl generell als auch über die unterschiedlichen Ansätze hinweg variable Interventionseffekte zu geben scheint. Allerdings wird die aktuelle Forschungslandschaft zum Thema möglicherweise von den Ergebnissen aus kleineren Studien dominiert, was sie nicht uneingeschränkt zuverlässig erscheinen lässt.
Literatur
Danielsen, P. A., Mentzoni, R. A. & Lag, T. (2024). Treatment Effects of Therapeutic Interventions for Gaming Disorder: A Systematic Review and Meta-Analysis. Addictive Behaviors 149, 107887. https://doi.org/10.1016/j.addbeh.2023.107887.
Pustejovsky, J. E., & Tipton, E. (2022). Meta-analysis with robust variance estimation: Expanding the range of working models. Prevention Science, 23(3), 425–438. https://doi.org/10.1007/s11121-021-01246-3
Wölfling, K., Müller, K. W., Dreier, M., Ruckes, C., Deuster, O., Batra, A., Mann, K. et al. (2019). Efficacy of Short-Term Treatment of Internet and Computer Game Addiction: A Randomized Clinical Trial. JAMA Psychiatry 76(10), 1018 – 1025. https://doi.org/10.1001/jamapsychiatry.2019.1676.