The application of network thinking to psychometric questions has led to rapid developments in several subfields of psychology, most notably clinical psychology and psychiatry. To understand why the network approach has gained traction, it is helpful to first examine how psychologists traditionally conceptualize the relationship between symptoms and disorders.
Traditional View: Latent Variable Models
In Western medicine and much of clinical psychology, a disease model has typically been applied to psychopathology. This model assumes that an underlying disorder (latent variable) causes the observable symptoms. For instance, major depressive disorder (MDD) might be conceptualized as an unobserved pathogenic factor leading to symptoms such as insomnia, fatigue, excessive worrying, and concentration problems. Here, symptoms are viewed as passive indicators of a single latent construct, meaning they covary primarily because they reflect the same root cause.
Alternative View: Network Theory
By contrast, network theory (Borsboom & Cramer, 2013) proposes that symptoms are active, interacting components of a causal system. Rather than being mere indicators of an underlying disorder, symptoms directly influence one another. For example, insomnia can precipitate fatigue, which in turn can cause concentration difficulties, creating feedback loops that sustain the disorder. According to this approach, mental disorders emerge from the structure and dynamics of these symptom networks. Targeting the most influential (or “central”) symptoms may therefore disrupt maladaptive feedback loops and lead to widespread improvements in the symptom network.
Extra: Two example of network approaches
To illustrate how the network approach differs from traditional latent variable models, it is useful to consider two well-known domains in psychology: depression and intelligence.
Depression
In a traditional latent variable framework, depression is caused by a single underlying pathogenic factor (a latent variable). This factor is assumed to give rise to various depressive symptoms—such as insomnia, fatigue, excessive worrying, and concentration problems—and explains why these symptoms often co-occur. Treatment, from this perspective, aims at the common underlying cause, with the assumption that symptom relief will follow once the core latent factor is addressed.
In the network approach (Cramer et al., 2010), depression is seen as a dynamic network of causally interacting symptoms. For instance, insomnia can lead to fatigue, which might reduce motivation and exacerbate negative thinking, forming a self-reinforcing loop. Symptoms are conceptualized as the “nodes” of the network, and the edges represent causal (or at least direct) relationships between them. Alleviating a “key” symptom like insomnia can diminish fatigue, improve concentration, and potentially disrupt the entire network enough to reduce the severity of depression, without needing to invoke a single, latent disorder.
Intelligence
Spearman’s classic g-factor theory of intelligence suggests a single underlying general intelligence factor (g) that drives performance in diverse cognitive tasks (e.g., verbal reasoning, mathematical skills, and memory). The positive correlations between these tasks are interpreted as manifestations of one latent cognitive ability.
Van der Maas et al. (2006) challenge the g-factor theory by proposing that observed covariation among cognitive tasks arises from direct interactions among cognitive processes. For example, improvements in working memory may enhance problem-solving skills, which in turn can improve reasoning ability. Rather than a single underlying factor, intelligence emerges from the dynamic interplay of multiple cognitive processes. This approach highlights how specific cognitive skills can bolster one another, suggesting targeted interventions (e.g., strengthening working memory) may have cascading effects on other abilities in the network.
These two examples illustrate how the network perspective can be applied across psychological subfields. Instead of emphasizing an unobservable cause for observable outcomes, the network approach focuses on direct and dynamic interactions between measurable components (symptoms or cognitive processes).
Psychopathology as Complex Networks
Building on the network perspective, researchers have increasingly recognized that psychopathologies can be viewed as complex networks of interrelated symptoms. This reconceptualization addresses several long-standing critiques of latent variable models.
Critiques of Latent Variable Models
Recent work (e.g., Lange et al., 2020) highlights three assumptions of latent variable models that may be unrealistic when applied to mental disorders:
Common-Cause Assumption: Latent variable models assume that a single underlying cause (the disorder) predicts all associated symptoms. In major depressive disorder (MDD), for example, a single factor might be invoked to explain persistent sadness, loss of interest, and fatigue. However, research increasingly shows that these symptoms can stem from multiple, interacting causes (e.g., negative thinking patterns, hormonal imbalances, environmental stressors).
Assumption of Exchangeability: Traditional models often consider symptoms as interchangeable indicators of the same underlying construct. Clinical evidence, however, suggests that individual symptoms can play unique roles. For instance, in generalized anxiety disorder (GAD), excessive worrying may trigger insomnia, which then exacerbates fatigue and concentration problems. These symptoms are not simply redundant manifestations of a latent factor; they have distinct positions in the overall clinical picture.
Principle of Local Independence: Latent variable theory holds that once the latent variable is statistically controlled, symptoms should not significantly correlate with one another. Yet empirical data often reveal persistent correlations among symptoms even after adjusting for the latent variable. For instance, in MDD, fatigue and concentration difficulties frequently co-occur independently of overall depression severity, indicating that symptoms may have direct causal or interactive relationships.
Advantages of the Network Approach
In response to these critiques, the network approach conceptualizes mental disorders as complex networks of interacting symptoms. This reconceptualization involves several key insights:
Causal Interactions Between Symptoms: Symptoms may directly trigger or amplify one another, forming positive feedback loops that sustain a disorder. For example, insomnia → fatigue → concentration problems in depression.
Emergence of Symptom Co-Occurrence: Symptom co-occurrence arises from network structure. Instead of a single underlying factor forcing symptoms to cluster, groups of symptoms become interconnected through reciprocal influences. These emergent clusters of symptoms are often labeled as distinct mental disorders, such as depression or obsessive-compulsive disorder.
Symptom-Based Interventions: Identifying “central” or highly connected symptoms can suggest strategic intervention points. Treating or managing these symptoms may dampen the entire network, potentially yielding more efficient therapy outcomes.
Attractor States and Transitions: Drawing on dynamical systems theory, network models describe stable patterns of symptom activation (attractor states) and potential tipping points where small changes lead to major shifts in symptom severity. Understanding where an individual’s symptom network lies in this landscape can inform the intensity and timing of therapeutic interventions. This concept will be elaborated upon in the subsequent section on network metrics.
Extra: Comorbidity
Comorbidity refers to the co-occurrence of multiple diagnoses in a single individual. High comorbidity rates are common in psychiatric classification systems (e.g., the DSM), with some estimates suggesting that rates can approach 60% in particular populations (Gordon et al., 2016; Reale et al., 2017). For instance, anxiety often appears not only in generalized anxiety disorder but also in schizophrenia, bipolar disorder, and post-traumatic stress disorder. Such overlapping diagnoses can complicate clinical decision-making and lead to overlapping treatments.
Traditional Latent Variable Model Perspective
From the viewpoint of latent variable theory, comorbidity reflects shared underlying factors. Two distinct disorders could be explained by partially overlapping latent variables, which produce overlapping symptom profiles. While this approach can account for statistical correlations among disorders, it struggles to explain precisely how and why specific symptoms transition or link across diagnostic boundaries.
Network Approach Perspective
The network approach offers a more mechanistic explanation of comorbidity by focusing on bridge symptoms—symptoms that belong to or strongly connect two different diagnostic networks. When such bridge symptoms are activated in one network, they can trigger or exacerbate symptoms in another network, leading to comorbidity. For instance, if “excessive worrying” acts as a bridge symptom between GAD and depression, then heightened worry could intensify depressive symptoms, pulling the individual’s overall mental state toward a depressive factor. This explanation emphasizes direct symptom-to-symptom links as the drivers of comorbidity.
Advantages of the Network Approach Over Traditional Latent Variable Models
Direct Symptom Interactions: The network approach explicitly models how symptoms from different disorders can influence one another.
Identification of Bridge Symptoms: By locating highly connected or “bridge” nodes in a symptom network, clinicians can better understand how comorbidity arises and persists.
Dynamic Representation: Rather than treating underlying disease as static, the network approach acknowledges that symptom relationships can fluctuate over time, providing a richer account of how disorders wax and wane.
Clinical Implications: Targeted, symptom-focused treatments can more precisely disrupt the links that maintain or bridge disorders, potentially reducing comorbidity rates and improving patient outcomes.
In sum, viewing psychological constructs—whether disorders or cognitive abilities—as dynamic, interconnected networks provides powerful insights into why symptoms co-occur, how they maintain or exacerbate one another, and where interventions might be most effectively applied. This perspective is likely to continue influencing clinical research, diagnostic criteria, and therapeutic strategies across multiple subfields in psychology.
Study
Eating disorder and Transdiagnostic Perspective
In the study “Transdiagnostic Vulnerability Factors in Eating Disorders: A Network Analysis” by Vervaet et al. (2021), the authors explore the complex nature of eating disorders (EDs) through a transdiagnostic lens. This perspective acknowledges the fluidity between different ED diagnoses and the common vulnerabilities that may underlie various manifestations of disordered eating behaviors.
Traditionally, eating disorders are classified into distinct categories:
Anorexia Nervosa (AN): Characterized by restrictive eating, an intense fear of gaining weight, and a distorted body image.
Bulimia Nervosa (BN): Involves cycles of binge eating followed by compensatory behaviors such as vomiting or excessive exercise.
Binge Eating Disorder (BED): Defined by recurrent episodes of eating large quantities of food without subsequent purging behaviors.
Other Specified Feeding and Eating Disorders (OSFED): A category that encompasses eating disorders that do not meet the specific criteria for AN, BN, or BED but still cause significant distress or impairment.
Although these classifications provide a structured framework for diagnosing eating disorders, distinguishing between them in clinical practice can be challenging. This difficulty arises because the symptoms often overlap significantly across different categories. For example, individuals with anorexia nervosa may also engage in binge-eating and purging behaviors, which are characteristic of bulimia nervosa. Similarly, both bulimia nervosa and binge eating disorder involve episodes of excessive food intake, differing primarily in the presence or absence of compensatory behaviors. This symptom similarity contributes to diagnostic ambiguity and increases the likelihood of diagnostic crossover, where patients shift from one eating disorder diagnosis to another over time. Such overlap highlights the need for a more nuanced understanding of eating disorders that goes beyond rigid categorical distinctions.
The transdiagnostic perspective highlights several key observations:
Diagnostic Crossover: Patients frequently transition between different ED diagnoses over time, suggesting shared underlying mechanisms.
Comorbidity: There is a high prevalence of co-occurring disorders, such as anxiety and depression, among individuals with EDs.
The primary goal of this perspective is to identify common vulnerabilities that contribute to individual symptoms across various EDs. By understanding these shared factors, interventions can be developed to target the root causes of disordered eating behaviors, rather than focusing solely on specific diagnostic categories.
Implications for Treatment
Adopting a transdiagnostic perspective has significant implications for the treatment of eating disorders:
Unified Treatment Approaches: Rather than developing separate treatments for each ED subtype, interventions can be designed to address common underlying vulnerabilities, potentially increasing their applicability and effectiveness.
Personalized Interventions: By identifying the most central symptoms or factors within an individual’s symptom network, treatments can be tailored to target these key areas, potentially leading to more efficient and effective outcomes.
Therefore, Vervaet et al. (2021) employed network analysis to examine the interconnectedness of ED symptoms and related psychological factors. This method allows for the visualization and analysis of complex relationships between symptoms, providing insights into which symptoms are most central or influential within the network.
Study design
The study utilized a substantial dataset and employed several instruments to assess a range of psychopathological constructs.
Sample: The study included a total of 2,302 patients diagnosed with eating disorders, assessed between 1998 and 2015.
The dataset utilized in this study is publicly available and can be accessed via the Open Science Framework (OSF). You can also find the dataset in the Moodle platform for this course.
# Loading the data from your working directoryload("eat.rda")
Assessment Tools
Eating Disorder Inventory (EDI): Initially, the Eating Disorder Inventory-II (EDI-II) was used, which was later updated to the Eating Disorder Inventory-3 (EDI-3). The Eating Disorder Inventory (EDI) is a widely utilized self-report measure designed to assess attitudes and behaviors related to eating, weight, and body image. The EDI-II, aligned with DSM-IV criteria, evaluates 11 subdimensions of symptoms. These subscales provide a comprehensive assessment of the symptoms associated with eating disorders.
General Psychopathology: Symptoms of depression and anxiety were evaluated to understand their association with eating disorder symptoms.
Personality Traits: The Temperament and Character Inventory (TCI) was employed to assess various personality dimensions. The TCI is a comprehensive tool that measures traits such as novelty seeking, harm avoidance, reward dependence, and persistence, providing insights into the personality profiles of individuals with eating disorders.
Maladaptive Schemas: The Young Schema Questionnaire-Short Form 3 (YSQ-S3), was used to identify early maladaptive schemas. These schemas are deeply ingrained patterns of thought and behavior that are believed to contribute to the development and maintenance of psychological disorders, including eating disorders.
head(eat)# Display the first few rows of the 'eat' dataset
## # A tibble: 6 × 32## Dft Bul Bod Ine Per Dis Awa Fea Asm Imp Soc BDI Anx Res Nov Har ## <dbl+lbl> <dbl+> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>## 1 17 0 16 22 6 13 18 13 NA NA NA NA NA NA 16 23 ## 2 11 0 14 1 11 3 5 0 NA NA NA NA NA NA 17 2 ## 3 16 13 26 19 1 7 16 14 NA NA NA NA NA NA 17 27 ## 4 19 16 19 20 0 20 15 6 NA NA NA NA NA NA 27 20 ## 5 1 0 14 24 18 4 4 5 NA NA NA NA NA NA 14 19 ## 6 21 0 25 20 15 7 11 9 NA NA NA NA NA NA 11 27 ## # ℹ 16 more variables: Red <dbl+lbl>, Pes <dbl+lbl>, Sed <dbl+lbl>, Coa <dbl+lbl>, Set <dbl+lbl>,## # Dir <dbl+lbl>, Aut <dbl+lbl>, Lim <dbl+lbl>, Foc <dbl+lbl>, Inh <dbl+lbl>, Mis <dbl+lbl>,## # Sta <dbl+lbl>, Exp <dbl+lbl>, Cri <dbl+lbl>, Qua <dbl+lbl>, Pref <dbl+lbl>
Network Theory
We now turn to the methodological underpinnings of network analysis.
Network analysis in socialogy vs. psychology
Network analysis originated in sociology as a way to study the relationships between individuals or groups within a social system. In this sociological tradition:
Nodes (Vertices) typically represent people, organizations, or other social entities.
Edges (Links) depict observable interactions or relationships, such as friendships, communication patterns, or collaborative ties.
By mapping these connections, sociologists can visualize and analyze the structure of social networks—detecting, for instance, how strongly a community is connected or identifying key actors who serve as bridges between subgroups.
In psychological research, the same principles are adapted to examine interactions among psychological constructs rather than social entities. Here:
Nodes (Vertices) often represent symptoms, behaviors, or cognitive processes.
Edges (Links) depict how these nodes are interrelated—whether via statistical associations (e.g., correlations), partial correlations, or other metrics of connectivity.
A key distinction is that, while sociological networks rely on direct observations of relationships (e.g., who befriends whom), psychological networks frequently involve latent constructs, making edges less directly observable. Researchers estimate these edges using statistical methods such as partial correlation, co-occurrence frequencies, or regression-based techniques. In practice, this means psychologists often construct networks by analyzing data from clinical assessments, self-report questionnaires, or experimental measures to infer the underlying structure of symptom or cognitive networks.
Attributes of Network Edges
In both sociology and psychology, edges (or links) connect pairs of nodes and are fundamental to any network representation. However, the interpretation of these edges can be especially nuanced in psychological networks. Three attributes—weight, sign, and directionality—are particularly important.
Weight: Edges can be weighted, reflecting the strength of the association between nodes. A higher weight indicates a stronger relationship. For example, in a network of depressive symptoms, a strong association (high weight) might be found between insomnia and fatigue.
Sign: Edges can have a positive or negative sign, indicating the direction of the relationship. A positive edge signifies that as one symptom increases, the connected symptom also increases, while a negative edge indicates an inverse relationship. For instance, increased anxiety might be positively associated with restlessness but negatively associated with concentration.
Directionality: Edges can be directed or undirected. Directed edges imply a causal or directional influence from one node to another, suggesting that changes in one symptom may lead to changes in another. Undirected edges indicate a bidirectional or non-specific association, where the direction of influence is not specified.
Understanding these edge attributes is crucial for interpreting psychological networks, as they offer valuable information about the structure and dynamics of psychological phenomena. By analyzing these networks, researchers can identify central symptoms that may play a pivotal role in the maintenance of a disorder, as well as peripheral symptoms that may be less influential. This knowledge can inform targeted interventions, where therapeutic efforts are focused on modifying central symptoms to induce broader changes within the network.
Adjacency Matrix
In network analysis, particularly within the context of psychological research, the adjacency matrix is a fundamental tool used to represent the structure of a network. This matrix is a square array (with an equal number of rows and columns) where each element indicates the presence and nature of a connection between pairs of nodes, which in psychological networks often represent symptoms or psychological constructs.
An adjacency matrix, denoted as A, is structured as follows:
Dimensions: The matrix is of size n × n, where n is the number of nodes in the network.
Elements (Aij): Each element represents the relationship between node i and node j.
Weighted Networks: In weighted networks, Aij holds the weight of the edge connecting nodes i and j, reflecting the strength of their association.
Unweighted Networks: In unweighted networks, Aij is typically 1 if an edge exists between nodes i and j, and 0 otherwise.
Sign of Edges: Edges can have positive or negative weights, indicating the direction of the relationship.
Directionality: In directed networks, Aij ≠ Aji. In undirected networks, Aij = Aji.
Diagonal Elements: Typically, the diagonal elements (Aii) are set to 0, indicating no self-loops. But in longitudinal temporal networks (discussed in the next chapter), diagonal elements represent autocorrelation.
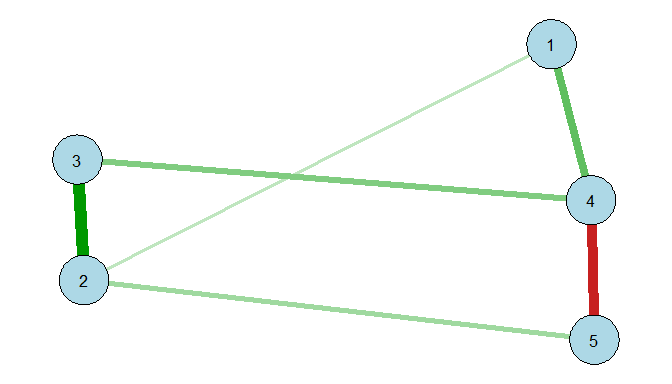
Weighted Undirected Network Graph
Consider a weighted but undirected network with five nodes, $v_1$ to $v_5$. The adjacency matrix A is represented as:
In this matrix:
The element $A_{12} = 0.2$ indicates a positive association with a weight of 0.2 between nodes $v_1$ and $v_2$.
$A_{45} = -0.7$ signifies a negative association between nodes $v_4$ and $v_5$.
The symmetry of the matrix suggests that the network is undirected.
In R, one might visualize this matrix with the qgraph package::
library(qgraph)# Define an adjacency matrixadj<-matrix(c(0,0.2,0,0.5,0,0.2,0,0.8,0,0.3,0,0.8,0,0.4,0,0.5,0,0.4,0,-0.7,0,0.3,0,-0.7,0),nrow=5,byrow=TRUE)# Plot the graphqgraph(adj,layout="spring",labels=1:5,color="lightblue")
Unweighted Directed Network
Now consider a unweighted but directed network with five nodes, $v_1$ to $v_5$. Unlike undirected networks where relationships are mutual, directed networks allow for one-way connections, meaning node i can influence node j without node j necessarily influencing node i.
The adjacency matrix A for an unweighted directed network can be represented as:
](/media/header/global_network.jpg)