](/media/header/writing_math.jpg)
Tests für unabhängige Stichproben
Kernfragen dieser Lehreinheit über Gruppenvergleiche
- Wie fertige ich Deskriptivstatistiken (Grafiken, Kennwerte) zur Veranschaulichung des Unterschieds zwischen zwei Gruppen an?
- Was sind Voraussetzungen des t-Tests und wie prüfe ich sie?
- Wie führe ich einen t-Test in R durch?
- Wie berechne ich die Effektstärke Cohen’s d?
- Wie führe ich den Wilcoxon-Test (auch “Mann-Whitney-Test”, “U-Test”, “Mann-Whitney-U-Test”, “Wilcoxon-Rangsummentest”) in R durch?
Vorbereitende Schritte
Den Datensatz fb25 haben wir bereits über diesen Link heruntergeladen und können ihn über den lokalen Speicherort einladen oder Sie können Ihn direkt mittels des folgenden Befehls aus dem Internet in das Environment bekommen. In den vorherigen Tutorials und den dazugehörigen Aufgaben haben wir bereits Änderungen am Datensatz durchgeführt, die hier nochmal aufgeführt sind, um den Datensatz auf dem aktuellen Stand zu haben:
#### Was bisher geschah: ----
# Daten laden
load(url('https://pandar.netlify.app/daten/fb25.rda'))
# Nominalskalierte Variablen in Faktoren verwandeln
fb25$hand_factor <- factor(fb25$hand,
levels = 1:2,
labels = c("links", "rechts"))
fb25$fach <- factor(fb25$fach,
levels = 1:5,
labels = c('Allgemeine', 'Biologische', 'Entwicklung', 'Klinische', 'Diag./Meth.'))
fb25$ziel <- factor(fb25$ziel,
levels = 1:4,
labels = c("Wirtschaft", "Therapie", "Forschung", "Andere"))
fb25$wohnen <- factor(fb25$wohnen,
levels = 1:4,
labels = c("WG", "bei Eltern", "alleine", "sonstiges"))
# Rekodierung invertierter Items
fb25$mdbf4_r <- -1 * (fb25$mdbf4 - 5)
fb25$mdbf11_r <- -1 * (fb25$mdbf11 - 5)
fb25$mdbf3_r <- -1 * (fb25$mdbf3 - 5)
fb25$mdbf9_r <- -1 * (fb25$mdbf9 - 5)
# Berechnung von Skalenwerten
fb25$gs_pre <- fb25[, c('mdbf1', 'mdbf4_r',
'mdbf8', 'mdbf11_r')] |> rowMeans()
fb25$ru_pre <- fb25[, c("mdbf3_r", "mdbf6",
"mdbf9_r", "mdbf12")] |> rowMeans()
# z-Standardisierung
fb25$ru_pre_zstd <- scale(fb25$ru_pre, center = TRUE, scale = TRUE)
Erzeugung der Gruppierungsvariablen
Die Gruppierungsvariable in unserer Fragestellung sollte für die Nutzung der Funktionen in R als Faktor vorliegen. Bei uns soll es um das Interesse am Fach klinischer Psychologie (ja vs. nein) gehen. Die entsprechende (nominalskalierte) Variable liegt noch nicht im Datensatz vor, kann aber einfach erstellt werden, indem die nichtklinischen Interessen in eine Kategorie zusammengefasst werden. Dies erfolgt per logischer Abfrage (fb25$fach == "Klinische") und anschließender Transformation des Ergebnisses in eine Faktorvariable:
fb25$fach_klin <- factor(as.numeric(fb25$fach == "Klinische"),
levels = 0:1,
labels = c("nicht klinisch", "klinisch"))
Mit table können wir uns die Häufigkeiten in unserer neuen Variablen anschauen. 93 Befragte haben das größte Interesse für klinische Psychologie angegeben, 113 für andere Fächer.
table(fb25$fach_klin)
##
## nicht klinisch klinisch
## 113 93
Was erwartet Sie?
Nachdem wir uns zuletzt mit der Frage auseinandergesetzt haben, ob unsere Stichprobe aus einer Population mit bekanntem Mittelwert ($\mu_0$) stammt oder aus einer davon abweichenden Grundgesamtheit, fokussieren wir uns nun auf Unterschiede zwischen Stichproben aus zwei Gruppen. Hierbei muss zwischen unabhängigen und abhängigen Stichproben unterschieden werden - um den ersten Fall geht es uns hier, den Zweiten gucken wir uns in der nächsten Sitzung an.
In dieser Sitzung geht es uns um primär um zwei Vergleiche:
- Unterscheiden sich Studierende, die primäre an klinischen Inhalten interessiert sind in ihrer Lebenszufriedenheit von denen, die ihre Interessen eher in anderen Bereichen der Psychologie sehen? (t-Test und Cohen’s d für unabhängige Stichproben)
- Sind klinisch interessierte Studierende zu Beginn der allerersten Sitzung eines Statistik Kurs im Psychologiestudium im Mittel schlechter gelaunt, als Studierende mit anderen Interessenslagen? (Wilcoxon-Test für unabhängige Stichproben)
Außerdem finden Sie im Anhang auch noch eine weitere Frage:
- Haben Studierende mit Wohnort in Uninähe (Frankfurt) mit gleicher Wahrscheinlichkeit einen Nebenjob wie Studierende, deren Wohnort außerhalb von Frankfurt liegt? (Vierfelder-$\chi^2$-Test)
Mittelwertsvergleich
Wir wollen untersuchen, ob Studierende, die sich für die klinische Psychologie interessieren, im Mittel das gleiche Ausmaß an Lebenszufriedenheit aufweisen wie Studierende, deren Hauptinteresse in einem der vielen und spannenden anderen Bereiche der Psychologie liegt (zum Beispiel der Methodenlehre!). Hinsichtlich der Richtung der Hypothese können wir uns nicht genau festlegen, weil wir für beides hinreichend gute Argumente gefunden haben. Haben Personen, die sich für die klinische Psychologie interessieren eine stärkere Tendenz dazu, sich mit Problemen und Krankheiten zu befassen und sind deswegen weniger zufrieden mit ihrem Leben ($H_1: \mu_1 < \mu_2$)? Oder freuen sich Studierende, die sich für klinische Inhalte interessieren mehr darüber nun, im Psychologiestudium, dieser Faszination endlich stärker nachgehen zu können ($H_1: \mu_1 > \mu_2$)? Weil wir diese und sehr viele andere Möglichkeiten nicht ausreichend gut gegeneinander abwägen können, legen wir ein ungerichtetes Hypothesenpaar fest: $H_0 : \mu_1 = \mu_2$ und $H_1: \mu_1 \neq \mu_2$.
Deskriptivstatistik
Im ersten Schritt wollen wir uns die Werte in den beiden Gruppen deskriptiv anschauen. Dazu können wir die Daten entweder visuell oder durch statistische Kennwerte aufbereiten. Mithilfe eines Boxplots lassen sich Unterschiede zwischen Gruppen gut grafisch darstellen. Die hier verwenderte Syntax fb25$lz ~ fb25$fach_klin nutzt die Formelnotation in R, welche Sie im Rahmen der Regression noch genauer kennenlernen werden. Links von der ~ (Tilde) steht die abhängige Variable (hier der Wert in der Lebenszufriedenheit), deren Mittelwertsunterschiede durch die unabhängige Variable (hier Interesse) rechts der ~ “erklärt” werden soll.
# Gruppierter Boxplot :
boxplot(fb25$lz ~ fb25$fach_klin,
xlab="Interesse", ylab="Lebenszufriedenheit",
las=1, cex.lab=1.5,
main="Lebenszufriedenheit je nach Interesse")
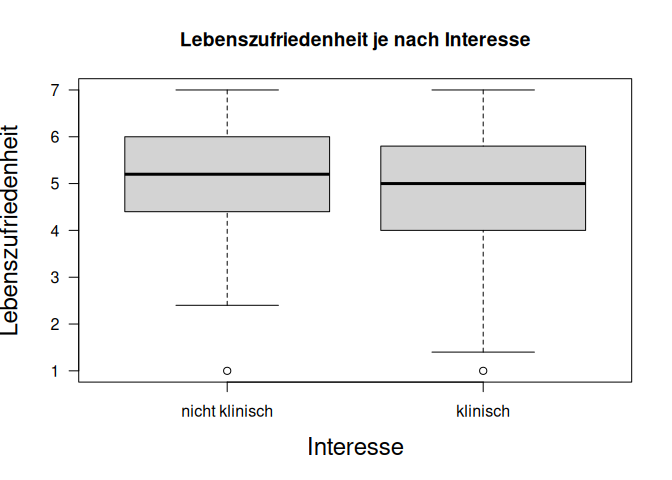
Die Werte in den Gruppen lassen sich auch durch Deskriptivstatistiken vergleichen, ein übliches Vorgehen ist die Darstellung der Verteilungskennwerte (Mittelwerte, Standardabweichungen u.a.) in den Gruppen. Diese lassen sich komfortabel über die Funktion describeBy() des psych-Pakets erzeugen. Das Paket muss installiert sein und mit library() geladen werden.
library(psych)
describeBy(x = fb25$lz, group = fb25$fach_klin) # beide Gruppen im Vergleich
##
## Descriptive statistics by group
## group: nicht klinisch
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 113 5.06 1.25 5.2 5.16 1.19 1 7 6 -0.72 0 0.12
## ---------------------------------------------------------
## group: klinisch
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 93 4.73 1.35 5 4.86 1.48 1 7 6 -0.78 -0.08 0.14
Wie bei der R-Funktion sd() gibt diese Funktion nicht die Stichprobenkennwerte $s$, sondern die Populationsschätzer $\hat{\sigma}$ aus. Daher berechnen wir die Stichproben-Standardabweichungen per Hand, indem wir die Ergebnisse der sd()-Funktion mit $\sqrt{(n_g-1)/n_g}$ multiplizieren. $n_g$ ist hierbei die jeweilige Gruppengröße.
# Werte in LZ für beide Gruppen, nur gültige Werte
lz_nichtKlin <- fb25$lz[fb25$fach_klin=="nicht klinisch"] |> na.omit()
lz_Klin <- fb25$lz[fb25$fach_klin=="klinisch"] |> na.omit()
# Gruppengrößen
n_nichtKlin <- length(lz_nichtKlin)
n_Klin <- length(lz_Klin)
# Stichproben-Standardabweichungen
sd_nichtKlin <- sd(lz_nichtKlin) * sqrt((n_nichtKlin-1) / n_nichtKlin)
sd_nichtKlin
## [1] 1.247799
sd_Klin <- sd(lz_Klin) * sqrt((n_Klin-1) / n_Klin)
sd_Klin
## [1] 1.342693
Voraussetzungen
Damit wir den Ergebnissen des t-Tests trauen können, müssen dessen Voraussetzungen erfüllt sein. Diese sind:
- zwei unabhängige Stichproben $\rightarrow$ ok
- die einzelnen Messwerte innerhalb der Gruppen sind voneinander unabhängig (Messwert einer Vpn hat keinen Einfluss auf den Messwert einer anderen) $\rightarrow$ ok
- das untersuchte Merkmal ist in den Grundgesamtheiten der beiden Gruppen normalverteilt $\rightarrow$ (ggf.) optische Prüfung
- Homoskedastizität: Varianzen der Variablen innerhalb der beiden Populationen sind gleich $\rightarrow$ Levene-Test
Wenn das Merkmal, das wir untersuchen, in der Population normalverteilt ist (Voraussetzung 3), können wir den $t$-Test nutzen. Allerdings haben wir in den meisten Fällen keine zusätzliche Information über die Verteilung in der Population als die, die wir aus unserer Stichprobe ziehen können. Daher ist es üblich, die Annahme optisch zu prüfen. Das werden wir im Folgenden auch tun, nur vorab der Zusatz, dass in vielen Studien aufgrund der Stichprobengröße auf die Prüfung der Normalverteilungsannahme verzichtet wird. In Fällen, in denen die Stichprobe ausreichend groß ist, folgt die Stichprobenkennwerteverteilung wegen des zentralen Grenzwertsatzes auch unabhängig von der Verteilung in der Population der $t$-Verteilung. Dabei ist es Auslegungssache was genau “ausreichend groß” bedeutet. Häufig wird die Daumenregel von $n > 30$ in jeder Gruppe genutzt. Bei solch kleinen Stichproben greift der Effekt allerdings nur dann, wenn das Merkmal zumindest symmetrisch verteilt ist. Andere Empfehlungen gehen besonders bei sehr schiefen Verteilungen in Richtung von $n > 80$ pro Gruppe.
Um die Verteilung optisch zu prüfen, haben wir zwei Möglichkeiten:
- Möglichkeit 1: die bei Normalverteilung erwartete Dichtefunktion über das Histogramm legen und so die Übereinstimmung beurteilen.
Mithilfe von curve() zeichnen wir die Normalverteilung in das Histogramm. Hierbei bezeichnet x die x-Koordinate, mit dnorm() erhalten wir die Dichte der Normalverteilung. In diese Funktion müssen jeweils die empirischen Mittelwerte und Standardabweichungen übergeben werden - wir verwenden für die Standardabweichung der Einfachheit halber die geschätzte Populations-SD mit sd() (Dies wird auch in allen weiteren Tutorials ohne zusätzlichen Hinweis gemacht). Mit dem Argument add = T wird die Kurve dem bereits gezeichneten Histogramm hinzugefügt. Im Histogramm wird mit dem Argument probability = T die Darstellung der relativen Häufigkeiten gewählt, um empirische Werte und Verteilungsdichte gemeinsam sichtbar machen zu können.
- Möglichkeit 2: QQ-Plot (quantile-quantile): es wird die beobachtete Position eines Messwerts gegen diejenige Position, die unter Gültigkeit der Normalverteilung zu erwarten wäre, abgetragen. Bei Normalverteilung liegen die Punkte in etwa auf einer Geraden. Für den QQ-Plot verwenden wir die Funktion
qqPlot()aus dem Paketcar, dass ggf. noch installiert werden muss (install.packages("car")). DerqqPlot()-Befehl erzeugt uns den QQ-Plot samt Konfidenzband, um so eine leichtere Einschätzung hinsichtlich des Ausmaß der Abweichung von der Normalverteilung zu ermöglichen.
Der Befehl par(mfrow=c(1,2)) dient dazu, beide Grafiken nebeneinander darzustellen, mit dev.off() wird zur normalen Darstellung zurück gewechselt.
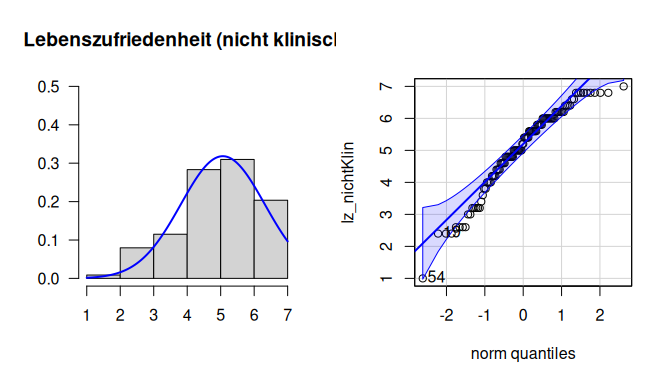
# Gruppe 1 (nichtKlinisch)
par(mfrow=c(1,2))
hist(lz_nichtKlin,
xlim=c(1,7), ylim=c(0,.5),
main="Lebenszufriedenheit (nicht klinisch)",
xlab="", ylab="",
las=1, probability=T)
curve(dnorm(x,
mean = mean(lz_nichtKlin),
sd = sd(lz_nichtKlin)),
col="blue", lwd=2, add=T)
qqPlot(lz_nichtKlin)
## [1] 54 19
dev.off()
## null device
## 1
Wir erkennen im Histogramm keine deutliche Abweichung von der Normalverteilung. Im QQ-Plot erkennen wir hingegen im oberen Bereich Abweichungen, die dadurch zustande kommen, dass Lebenszufriedenheit etwas linksschief verteilt ist.
Wir wiederholen die Befehle auch für die zweite Gruppe:
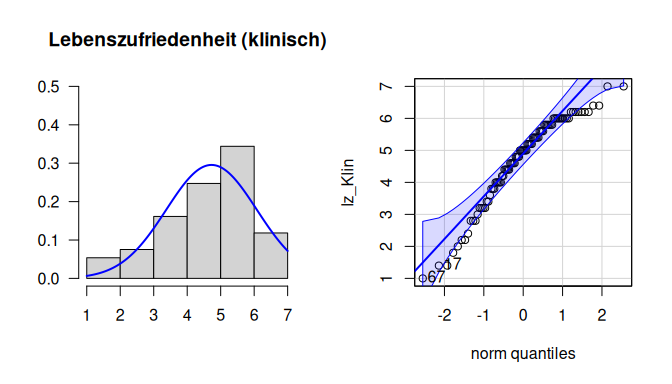
# Gruppe 2 (klinisch)
par(mfrow=c(1,2))
hist(lz_Klin,
xlim=c(1,7), ylim=c(0,.5),
main="Lebenszufriedenheit (klinisch)",
xlab="", ylab="", las=1, probability=T)
curve(dnorm(x,
mean = mean(lz_Klin, na.rm=T),
sd = sd(lz_Klin, na.rm=T)),
col="blue", lwd=2, add=T)
qqPlot(lz_Klin)
## [1] 67 17
dev.off()
## null device
## 1
In dieser Gruppe ist die Abweichung von der Normalverteilung noch etwas deutlicher. Aufgrund der Größe der Gruppen (beide $n > 80$) hindern uns diese Abweichungen nicht an der Durchführung des t-Tests.
Die vierte Annahme (Homoskedastizität - also die Varianzgleichheit in beiden Populationen) wird typischerweise mit einem inferenzstatistischen Verfahren geprüft, weil Varianzen meist weniger leicht optisch einzuschätzen sind. Wie in der Vorlesung besprochen, kann dafür der Levene-Test genutzt werden. Das Hypothesenpaar, das er prüft sieht so aus:
- $H_0$: $\sigma_1 = \sigma_2$ (Homoskedastizität ist gegeben)
- $H_1$: $\sigma_1 \neq \sigma_2$ (Homoskedastizität ist nicht gegeben)
Ein nicht-signifikantes Ergebnis (p > .05) deutet also darauf hin, dass wir nicht ausreichend Grundlage haben, um die Homoskedastizitätsannahme zu verwerfen. Auch die Funktion leveneTest() ist im car-Paket enthalten. Sie nimmt eine Formel entgegen, die die Punktzahl ihrer jeweiligen Gruppe zuweist. Links von der ~ (Tilde) steht die abhängige Variable (hier die Lebenszufriedenheit), deren Varianzunterschied durch die unabhängige Variable (hier Interesse) rechts der ~ erklärt werden soll. Wir merken uns also, dass die Gruppenzugehörigkeit rechts der ~ stehen muss.
leveneTest(fb25$lz ~ fb25$fach_klin)
## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 1 0.2793 0.5977
## 204
Das Testergebnis zeigt mit einem $p$-Wert von 0.598, dass die Nullhypothese beibehalten wird, wir also weiterhin von der Gültigkeit der Homoskedastizitätsannahme ausgehen können. Für den Fall, dass die Annahme nicht hält, gibt es die Welch-Korrektur für den $t$-Test - diese ist in der t.test()-Funktion die Voreinstellung!
Durchführung des $t$-Test
Zur Erinnerung - unsere Fragestellung für diesen Test war:
Unterscheiden sich Studierende, die primäre an klinischen Inhalten interessiert sind in ihrer Lebenszufriedenheit von denen, die ihre Interessen eher in anderen Bereichen der Psychologie sehen?
Weil die Fragestellung ungerichtet ist, brauchen wir auch eine ungerichtete Hypothese. Konkret ist unsere Hypothese also eine ungerichtete Unterschiedshypothese. Inhaltlich lässt sich das Paar aus $H_0$ und $H_1$ so formulieren:
- $H_0$: Klinisch und nicht klinisch interessierte Studierende unterscheiden sich nicht in ihrer Lebenszufriedenheit.
- $H_1$: Klinisch und nicht klinisch interessierte Studierende unterscheiden sich in ihrere Lebenszufriedenheit.
Etwas formaler ausgedrückt:
- $H_0$: $\mu_\text{nicht klinisch} = \mu_\text{klinisch}$ bzw. $\mu_\text{nicht klinisch} - \mu_\text{klinisch} = 0$
- $H_1$: $\mu_\text{nicht klinisch} \ne \mu_\text{klinisch}$ bzw. $\mu_\text{nicht klinisch} - \mu_\text{klinisch} \ne 0$
Wie so häufig gehen wir von einem $\alpha$-Fehlerniveau von 5% aus.
Wir hatten im Rahmen des Einstichproben-t-Tests bereits die Funktion t.test() kennengelernt. Diese nutzen wir wieder. Wir übergeben dieser wieder die Formel, die wir bereits im Boxplot und im Levene-Test verwendet haben. Außerdem wählen wir einige Zusatzargumente, die dann zum Zweistichproben-t-Test für unabhängige Stichproben führen:
t.test(fb25$lz ~ fb25$fach_klin, # abhängige Variable ~ unabhängige Variable
#paired = FALSE, # Stichproben sind unabhängig (Default)
alternative = "two.sided", # zweiseitige Testung (Default)
var.equal = TRUE, # Homoskedastizität liegt vor (-> Levene-Test)
conf.level = .95) # alpha = .05 (Default)
##
## Two Sample t-test
##
## data: fb25$lz by fb25$fach_klin
## t = 1.8537, df = 204, p-value = 0.06522
## alternative hypothesis: true difference in means between group nicht klinisch and group klinisch is not equal to 0
## 95 percent confidence interval:
## -0.02142561 0.69509580
## sample estimates:
## mean in group nicht klinisch mean in group klinisch
## 5.063717 4.726882
Anhand der Ergebnisse können wir folgende Aussage treffen: Studierende, die sich für klinische Inhalte interessieren unterscheiden sich in ihrer Lebenszufriedenheit nicht bedeutsam von Studierenden, die sich primär für andere Inhalte interessieren ($t = 1.854, df = 204$, $p = 0.065$). In Fällen wie diesem ist es wichtig, sich nicht von dem kleinen $p$-Wert dazu verleiten zu lassen, Dinge wie “knapp” oder “marginal” in seine Interpretation aufzunehmen. Das NHST, welches wir hier betreiben, gibt eine klare Entscheidungsgrenze vor, welche wir vorab definiert haben. Wenn wir uns entscheiden, ein Alpha-Fehlerniveau von 5% festzulegen, müssen wir uns strikt daran halten.
Berechnung der Effektstärke Cohen’s $d$
Obwohl wir hier zunächst keinen statistisch bedeutsamen Unterschied entdeckt haben, wollen wir zur Eindordnung des Ergebnisses die Effektstärke ermitteln: Cohen’s $d$ gibt den standardisierten Mittelwertsunterschied zwischen zwei Gruppen an. “Standardisiert” bedeutet, dass wir uns nicht mehr auf der Originalmetrik befinden (hier auf der Skala von 1 bis 7), sondern mit Standardabweichungen arbeiten. Ein Wert von 1 zeigt also an, dass sich die Gruppenmittelwerte um eine Standardabweichung voneinander unterscheiden. Die Effektstärke berechnet sich wie folgt:
wobei
$$ \hat{\sigma}_{inn} = \sqrt{\frac{{\hat{\sigma}_1^2}\cdot(n_1-1) + {\hat{\sigma}^2_2}\cdot(n_2-1)} {(n_1-1) + (n_2-1)}} $$ Cohen (1988) hat folgende Konventionen zur Beurteilung der Effektstärke $d$ vorgeschlagen, die man heranziehen kann, um den Effekt “bei kompletter Ahnungslosigkeit” einschätzen zu können (wissen wir mehr über den Sachverhalt, so sollten Effektstärken lieber im Bezug zu anderen Studienergebnissen interpretiert werden):
| $d$ | Interpretation |
|---|---|
| ~ .2 | kleiner Effekt |
| ~ .5 | mittlerer Effekt |
| ~ .8 | großer Effekt |
Wir bestimmen Cohen’s $d$ mit der Funktion cohen.d() aus dem Paket effsize (dass ggf. installiert werden muss):
library("effsize")
d <- cohen.d(fb25$lz, fb25$fach_klin, na.rm=T)
d
##
## Cohen's d
##
## d estimate: 0.2595394 (small)
## 95 percent confidence interval:
## lower upper
## -0.01765777 0.53673656
Fällt der Wert für $d$ negativ aus, interpretieren wir den Betrag. Die Funktion cohen.d gibt uns zusätzlich zur Effektstärke auch ein Konfidenzintervall aus. Dass der Mittelwertsunterschied nicht signifikant ist sehen wir auch daran, dass das Konfidenzintervall für $d$ den Wert null einschließt.
Ergebnisinterpretation
Wir haben untersucht, ob sich klinisch und nicht klinisch interessierte Studierende im Wert Ihrer Lebeszufriedenheit unterscheiden. Tatsächlich findet sich deskriptiv ein nur geringer Unterschied: Nicht klinisch interessierte Studierende weisen einen durchschnittlichen Wert von 5.064 (SD = 1.248) auf, während klinisch interessierte Studierende einen Wert von 4.727 (SD = 1.343) aufweisen. Dies entspricht nach Cohens Konvention (1988) einem sehr kleinen Effekt ($d$= 0.26).
Zur Beantwortung der Fragestellung haben wir - nachdem wir sowohl die Normalverteilungsannahme als auch die Homoskedastizitätsannahme gepüft haben - einen $t$-Test durchgeführt. Der Gruppenunterschied ist nicht bedeutsam ($t_{df = 204} = 1.854$, $p = 0.065$) - wir behalten die Nullhypothese also bei. Klinisch und nicht klinisch interessierte Studierende unterscheiden sich im Testwert für Lebenszufriedenheit nicht bedeutsam.
Rangsummenvergleich
Wir widmen uns nun der 2. Fragestellung. Dazu prüfen wir, ob klinisch interessierte Studierende in der ersten Sitzung des Statistikseminars weniger gut gelaunt sind, als Studierende, die sich primär für andere Inhalte interessieren. Hierbei handelt es sich also um eine gerichtete Hypothese. Da die aktuelle Stimmung sehr häufig nicht der Normalverteilung folgt, entscheiden wir uns statt des t-Tests den weniger anfälligen Wilcoxon-Test zu verwenden.
Deskriptivstatistik
Wir beginnen damit uns, wie oben, erst einmal grafisch anzusehen, wie die gute Stimmung gs_pre in beiden Gruppen aussieht. Dafür beginnen wir dieses mal mit einem Boxplot:
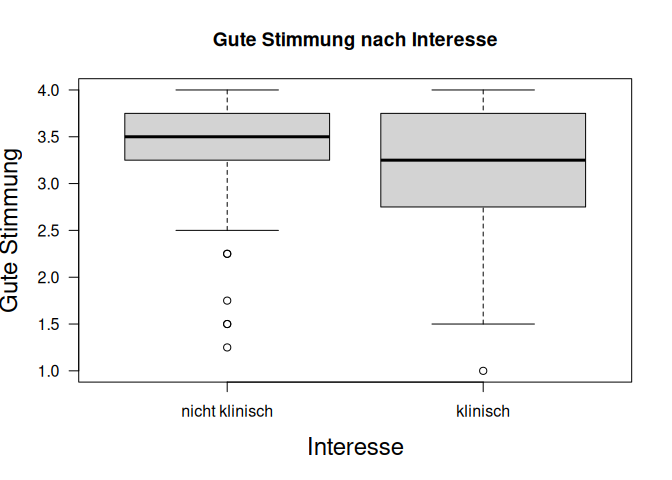
Hier können wir direkt (als dicke Linie eingezeichnet) die beiden Gruppenmediane sehen - diese unterscheiden sich nicht, in der Grafik liegen die Linien auf der gleichen Höhe. Die Verteilung der klinischen Gruppe liegt aber im unteren Bereich sichtlich niedriger, d.h. bezogen auf die unteren Quartile. Für mehr Details nutzen wir wieder die Deskriptivstatistik aus der describeBy Funktion:
describeBy(fb25$gs_pre, fb25$fach_klin) # beide Gruppen im Vergleich
##
## Descriptive statistics by group
## group: nicht klinisch
## vars n mean sd median trimmed mad min max range skew kurtosis
## X1 1 113 3.41 0.56 3.5 3.49 0.37 1.25 4 2.75 -1.56 3.03
## se
## X1 0.05
## ---------------------------------------------------------
## group: klinisch
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 93 3.2 0.67 3.25 3.28 0.74 1 4 3 -0.97 0.48 0.07
Wir sehen auch hier identische Mediane, aber einen höheren Mittelwert in der klinisch interessierten Gruppe im Vergleich zu den klinisch interessierten Studierenden. Die stärkere Streuung der klinischen Gruppe unterhalb des Medians wird in der größeren Mittleren absoluten Abweichung (mad, median absolute deviation) sichtbar.
Voraussetzungsprüfung
Wie schon der $t$-Test, hat auch der Wilcoxon-Test vier Voraussetzungen. Die ersten beiden bleiben gleich, nur die letzten beiden Unterscheiden sich leicht:
- zwei unabhängige Stichproben $\rightarrow$ ok
- die einzelnen Messwerte sind innerhalb der beiden Gruppen voneinander unabhängig (Messwert einer Vpn hat keinen Einfluss auf den Messwert einer anderen) $\rightarrow$ ok
- das untersuchte Merkmal ist stetig (mindestens singulär-ordinal skaliert)
- das Merkmal folgt in beiden Gruppen der gleichen Verteilung
Stetige Variablen haben theoretisch unendlich viele mögliche Ausprägungen. Dabei sind die Konsequenzen dieser Annahme jedoch nicht binär. Je mehr Ausprägungen eine Variable hat, desto besser funktioniert der Test. In unserem Fall ist die Variable gs_pre ein Skalenwert, der sich als der Mittelwert von vier Items mit jeweils vier Antwortkategorien ergibt. Insgesamt sind das also 13 mögliche Abstufungen. Wir beschließen an dieser Stelle, dass 13 nah genug an unendlich dran ist, um von einer stetigen Variable zu sprechen.
Für den Vergleich der Verteilungen in beiden Gruppen, schauen wir uns die Histogramme für die beiden Gruppen an:
# Gruppe 1 (nicht klinisch)
par(mfrow=c(1,2))
gs_nichtKlinisch <- fb25[(fb25$fach_klin=="nicht klinisch"), "gs_pre"] |> na.omit()
hist(gs_nichtKlinisch, xlim=c(1,4), ylim=c(0,.9), main="Gute Sitmmung (nicht klin.)", xlab="", ylab="", las=1, probability=T)
curve(dnorm(x, mean=mean(gs_nichtKlinisch, na.rm=T), sd=sd(gs_nichtKlinisch, na.rm=T)), col="blue", lwd=2, add=T)
gs_klinisch <- fb25[(fb25$fach_klin=="klinisch"), "gs_pre"] |> na.omit()
hist(gs_klinisch, xlim=c(1,4), ylim=c(0,.9), main="Gute Stimmung (klin.)", xlab="", ylab="", las=1, probability=T)
curve(dnorm(x, mean=mean(gs_klinisch, na.rm=T), sd=sd(gs_klinisch, na.rm=T)), col="blue", lwd=2, add=T)
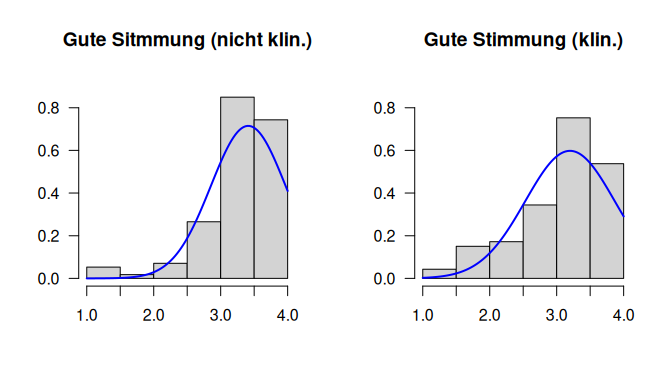
Wir sehen hier die vermutete Schiefe der Verteilung in beiden Gruppen. Diese fällt in der zweiten Gruppe schwächer aus, wodurch sich die Verteilungen sichtlich unterscheiden. Dieser Unterschied wird auch in der oben dargestellten mittleren absoluten Abweichung sichtbar. Es sei an dieser Stelle gesagt, dass unter diesen Voraussetzungen ein $t$-Test auch funktionieren würde, weil die beiden Verteilungen nicht dramatisch von der Normalität abweichen und die beiden Stichproben jeweils relativ groß sind. Dennoch nutzen wir im die Daten im Folgenden für den den Wilcoxon-Test nutzen, um den Vergleich der Rangsummen zu demonstrieren.
Inferenzstatistik mit dem Wilcoxon-Test
Zur Erinnerung, hier die Fragestellung, die wir untersuchen wollten:
Sind klinisch interessierte Studierende zu Beginn der allerersten Sitzung eines Statistik Kurs im Psychologiestudium im Mittel schlechter gelaunt, als Studierende mit anderen Interessenslagen?
Wir müssen aus dieser Fragestellung also eine gerichtete Hypothese ableiten:
- $H_0$: Nicht klinisch interessierte Studierende erreichen sind im Mittel schlechter oder genauso gut gelaunt wie klinisch interessierte Studierende.
- $H_1$: Nicht klinisch interessierte Studierende erreichen sind im Mittel besser gelaunt als klinisch interessierte Studierende.
Wieder etwas formaler ausgedrückt:
- $H_0$: $\eta_\text{nicht klinisch} \leq \eta_\text{klinisch}$ bzw. $\eta_\text{nicht klinisch} - \eta_\text{klinisch} \leq 0$
- $H_1$: $\eta_\text{nicht klinisch} \gt \eta_\text{klinisch}$ bzw. $\eta_\text{nicht klinisch} - \eta_\text{klinisch} \gt 0$
Wie so häufig, nehmen wir auch hier ein $\alpha$-Fehlerniveau von 5% an.
Die Funktion wilcox.test() nimmt im Grunde die gleichen Argumente entgegen wie die Funktion t.test(). Damit wir die gerichtete Hypothese in die richtige Richtung aufstellen können, müssen wir wissen, welches das erste Level des Faktors ist:
levels(fb25$fach_klin) # wichtig zu wissen: die erste der beiden Faktorstufen ist "nicht klinisch"
## [1] "nicht klinisch" "klinisch"
Da die erste Faktorstufe “nicht klinisch” ist, wissen wir, dass die gerichtete Hypothese “>” lauten muss. In R wird mit dem Argument alternative immer Bezug genommen auf die Formulierung der Alternativhypothese. In unseren Fall ist diese, dass die erste Gruppe (nicht klinisch) höhere Werte hat als die zweite Gruppe (klinisch), also müssen wir alternative = 'greater' angeben:
wilcox.test(fb25$gs_pre ~ fb25$fach_klin, # abhängige Variable ~ unabhängige Variable
#paired = FALSE, # Stichproben sind unabhängig (Default)
alternative = "greater", # einseitige Testung
conf.level = .95) # alpha = .05
##
## Wilcoxon rank sum test with continuity correction
##
## data: fb25$gs_pre by fb25$fach_klin
## W = 6253, p-value = 0.008689
## alternative hypothesis: true location shift is greater than 0
Per Voreinstellung wird in R der exakte $p$-Wert bestimmt, wenn die Stichprobe insgesamt weniger als 50 Personen umfasst und keine Rangbindungen vorliegen. Bei größeren Stichproben folgt die Rangsumme aufgrund des zentralen Grenzwertsatzes ausreichend gut der Normalverteilung und es wird ein $z$-Test der Rangsumme durchgeführt. Weil die Rangsumme allerdings nur ganze Zahlen annehmen kann ist diese Approximation ein wenig ungenau (insbesondere dann, wenn die Stichprobe noch relativ klein ist). Per Voreinstellung wird daher in R eine Kontinuitätskorrektur durchgeführt (mit dem Argument correct = TRUE), sodass Sie nicht den gleichen Wert erhalten, den Sie bekommen, wenn Sie den Test händisch durchführen würden. Wenn Sie diese Korrektur ausschalten (correct = FALSE) erhalten Sie den gleichen Wert.
Ergebnisinterpretation
Wir haben untersucht, ob nicht klinisch interessierte Studierende höhere Werte in der aktuellen Stimmung erreichen als klinisch interessierte Studierende. Deskriptiv sind Unterschiede sichtbar, auch wenn sich beide Gruppen im Median nicht unterscheiden ($Md_\text{nicht klinisch}$ = 3.5 und $Md_\text{klinisch}$ = 3.25). Die Mittelwerte ($M_\text{nicht klinisch}$ = 3.41 und $M_\text{klinisch}$ = 3.2) und die unteren Quantile ($Q_\text{1 nicht klinisch}$ = 3.25 und $Q_\text{1 klinisch}$ = 2.75) weisen in die erwartete Richtung. Zur Überprüfung der Hypothese wurde ein Wilcoxon-Test durchgeführt. Der Gruppenunterschied ist demnach statistisch bedeutsam ($W = 6253$, $p = 0.009$). Somit wird die Nullhypothese verworfen: Nicht klinisch interessierte Studierende erreichen zu Beginn ihres ersten Statistik Seminars höheren Werte in der aktuellen guten Stimmung als klinisch interessierte Studierende.
In diesem Beitrag haben wir gesehen, wie wir die zentrale Tendenz (Mittelwert oder Rangsummen) bei zwei unabhängigen Stichproben untersuchen können. Im nächsten Beitrag sehen wir dann, wie das Ganze funktioniert, wenn wir zwei Gruppen betrachten, zwischen denen eine Abhängigkeit besteht (z.B. weil wir wiederholt die gleichen Personen untersucht haben). Im Anhang finden Sie außerdem noch einen Test, mit dem Sie untersuchen können, ob sich die Häufigkeitsverteilungen in zwei unabhängigen Stichproben unterscheiden. Dieser Test bietet also die Möglichkeit auch nominalskalierte abhängige Variablen über zwei Gruppen zu vergleichen.
Appendix
Vierfelder-$\chi^2$-Test
Gehen wir nun zur 3. Fragestellung über. Wir verwenden wieder den Datensatz fb25.
Zusätzlich zur Gruppenvariable ist in diesem Beispiel auch die abhängige Variable nominalskaliert. Um Fragen wie diese zu beantworten, werden daher die Populationswahrscheinlichkeiten (job: ja [ja] vs. nein [nein]) zwischen den beiden Gruppen (ort: Frankfurt [FFM] vs. außerhalb [anderer]) miteinander verglichen. Diese Prüfung erfolgt mithilfe des $\chi^2$-Tests.
Datenaufbereitung
Zunächst müssen wir den ort und den job als Faktor abspeichern und entsprechende Labels vergeben. Damit wir hier keine Probleme bekommen, müssen wir zunächst prüfen, ob die Variablen ein factor sind:
is.factor(fb25$ort)
## [1] FALSE
is.factor(fb25$job)
## [1] FALSE
Dies ist bei beiden nicht der Fall, weswegen wir hier die Variable als Faktor ablegen können. Wir verwenden die Labels, die wir oben bereits in Klammern geschrieben haben.
# Achtung, nur einmal durchführen (ansonsten Datensatz neu einladen und Code erneut durchlaufen lassen!)
fb25$ort <- factor(fb25$ort, levels=c(1,2), labels=c("FFM", "anderer"))
fb25$job <- factor(fb25$job, levels=c(1,2), labels=c("nein", "ja"))
Deskriptivstatistik und Voraussetzungsprüfung
Wir beginnen wieder damit, uns Deskriptivstatistiken anzusehen und die Voraussetzungen des $\chi^2$-Tests zu prüfen. Diese sind
- Die einzelnen Beobachtungen sind voneinander unabhängig $\rightarrow$ ok (durch das Studiendesign anzunehmen)
- Jede Person lässt sich eindeutig einer Kategorie bzw. Merkmalskombination zuordnen $\rightarrow$ ok (durch das Studiendesign anzunehmen)
- Zellbesetzung für alle $n_{ij}$ > 5 $\rightarrow$ Prüfung anhand von Häufigkeitstabelle
Weil es sich beim $\chi^2$-Test um einen parametrischen Test handelt, folgt die Teststastistik genau genommen erst bei ausreichend großen Stichproben tatsächlich der behaupteten Verteilung. Für den Vierfelder-Test reicht es eigentlich schon aus, dass jede Zelle mit mindestens 5 Fällen besetzt ist:
tab <- table(fb25$ort, fb25$job)
tab
##
## nein ja
## FFM 78 46
## anderer 55 24
Hier sollten uns aus einer zu geringen Häufigkeit in einer Zelle der Häufigkeitstabelle also keine Probleme entstehen.
Durchführung des $\chi^2$-Tests
Hypothesenpaar (inhaltlich):
- $H_0$: Studierende mit Wohnort in Uninähe haben mit gleicher Wahrscheinlichkeit einen Nebenjob wie Studierende, deren Wohnort außerhalb von Frankfurt liegt.
- $H_1$: Studierende mit Wohnort in Uninähe haben mit einer höheren oder niedrigeren Wahrscheinlichkeit einen Nebenjob als Studierende, deren Wohnort außerhalb von Frankfurt liegt.
Hypothesenpaar (statistisch):
- $H_0$: $\pi_{ij} = \pi_{i\bullet} \cdot \pi_{\bullet j}$
- $H_1$: $\pi_{ij} \neq \pi_{i\bullet} \cdot \pi_{\bullet j}$
wobei $\pi_{ij}$ die Wahrscheinlichkeit, in Zelle $ij$ zu landen, ist. Betrachten wir die Häufigkeitstabelle, dann entspricht dies der Wahrscheinlichkeit der Ausprägung der $i$-ten Zeile (Variable: Wohnortnähe) und der $j$-ten Spalte (Variable: Nebenjob). $\pi_{i\bullet}$ beschreibt die Wahrscheinlichkeit, die Ausprägung der $i$-ten Zeile (Variable: Wohnortnähe) zu haben. $\pi_{\bullet j}$ beschreibt die Wahrscheinlichkeit, die Ausprägung der der $j$-ten Spalte (Variable: Nebenjob) zu haben. Die beiden betrachteten Variablen sind voneinander unabhängig, wenn die Wahrscheinlichkeit für das Auftreten von Y (Nebenjob) nicht davon abhängt, welches X (Wohnort) vorliegt. Ist dies der Fall, lässt sich die Wahrscheinlichkeit für das Auftreten der Kombination der Merkmalsausprägungen in das Produkt der Einzelwahrscheinlichkeiten zerlegen. Bspw. sollte sich die Wahrscheinlichkeit in Frankfurt zu wohnen und keinen Nebenjob zu haben, ausdrücken lassen (gleich sein) mit der Wahrscheinlichkeit in Frankfurt zu wohnen multipliziert mit der Wahrscheinlichkeit keinen Nebenjob zu haben: $\pi_\text{FFM,nein}=\pi_{\text{FFM},\bullet}\cdot\pi_{\bullet,\text{nein}}$ (unter $H_0$).
Für jede Zelle lassen sich die unter Gültigkeit der Nullhypothese erwarteten Häufigkeiten $e_{ij}$ bestimmen (hier sind $n_{i\bullet}$ und $n_{\bullet j}$ die absoluten Häufigkeiten), die zu den Wahrscheinlichkeiten aus dem Hypothesenpaar gehören:
$$e_{ij} = \frac{n_{i\bullet} \cdot n_{\bullet j}}{n}$$
$n_{i\bullet}$ und $n_{\bullet j}$ lassen sich über die Randsummen bestimmen (sie symbolisieren eigentlich: $n_{i\bullet}=n\hat{\pi}_{i\bullet}$, mit $n$ als Stichprobengröße). Diese hängen wir unseren Daten an. Anschließend erstellen wir einen neuen Datensatz und fügen alle erwarteten Häufigkeiten dort ein.
tab_mar <- addmargins(tab) # Randsummen zu Tabelle hinzufügen
tab_mar
##
## nein ja Sum
## FFM 78 46 124
## anderer 55 24 79
## Sum 133 70 203
expected <- data.frame(nein=c((tab_mar[1,3]*tab_mar[3,1])/tab_mar[3,3],
(tab_mar[2,3]*tab_mar[3,1])/tab_mar[3,3]),
ja=c((tab_mar[1,3]*tab_mar[3,2])/tab_mar[3,3],
(tab_mar[2,3]*tab_mar[3,2])/tab_mar[3,3]))
expected
## nein ja
## 1 81.24138 42.75862
## 2 51.75862 27.24138
Bspw. für die Kombination (FFM, nein) ergibt sich eine erwartete Häufigkeit von 81.24, welcher eine beobachtete Häufigkeit von 78 gegenüber steht. Mit dem $\chi^2$-Test können wir nun bestimmen, ob diese Unterschiede statistisch bedeutsam groß sind.
Um die Prüfgröße $\chi^2$ zu berechnen, können wir folgende Formel nutzen: $$\chi^2 = \sum_{i=1}^{2}{ \sum_{j=1}^{2}{ \frac{(n_{ij}-e_{ij})^2} {e_{ij}}}}$$
chi_quadrat_Wert <- (tab[1,1]-expected[1,1])^2/expected[1,1]+
(tab[1,2]-expected[1,2])^2/expected[1,2]+
(tab[2,1]-expected[2,1])^2/expected[2,1]+
(tab[2,2]-expected[2,2])^2/expected[2,2]
chi_quadrat_Wert
## [1] 0.9637167
Die Freiheitsgrade berechnen sich aus der Anzahl der untersuchten Kategorien: $df = (p - 1) \cdot (k - 1)$. Hier, im Fall des Vierfelder-$\chi^2$-Tests also mit $df = 1$, wobei
- p: Anzahl Kategorien Variable “ort” = 2
- k: Anzahl Kategorien Variable “job” = 2
Zur Bestimmung des kritischen Wertes und des $p$-Wertes ziehen wir die jeweiligen Funktionen der $\chi^2$ -Verteilung heran:
qchisq(.95, 1) # kritischer Wert
## [1] 3.841459
pchisq(chi_quadrat_Wert, 1, lower.tail = FALSE) # p-Wert
## [1] 0.3262522
Insgesamt ergibt sich damit.
- df = 1
- $\chi^2_{krit}$ = 3.84
- $\chi^2_{emp}$ = 0.964
- $\chi^2_{emp} < \chi^2_{krit}$ $\rightarrow H_0$ wird beibehalten
- $p$ = 0.326
- $p$-Wert > $\alpha$-Fehlerniveau $\rightarrow H_0$ wird beibehalten
Daraus lässt sich zusammenfassen: Die Wohnnähe zur Uni hängt nicht damit zusammen, ob ein Nebenjob ausgeübt wird $\chi^2$(df=1)=0.964, $p$ = 0.326.
Im Normalfall übernimmt die Funktion chisq.test() die Arbeit für uns, wenn wir ihr einfach eine 4-Feldertabelle übergeben. Als Argumente brauchen wir hauptsächlich das Objekt mit den Häufigkeiten. Weiterhin müssen wir das Argument correct mit FALSE angeben. Ansonsten würde standardmäßig die Kontinuitätskorrektur nach Yates durchgeführt werden. Diese ist als Alternative gedacht, wenn nicht der $\chi^2$-Verteilung gefolgt wird. Ein Indiz dafür sind bspw. sehr kleine Zahlen in manchen Kombinationen der Faktoren. Da wir hier in jeder Zelle einen größeren Wert hatten, brauchen wir diese Korrektur nicht.
chisq.test(tab, # Kreuztabelle
correct=F) # keine Kontinuinitätskorrektur nach Yates
##
## Pearson's Chi-squared test
##
## data: tab
## X-squared = 0.96372, df = 1, p-value = 0.3263
Das Ergebnis unterscheidet sich natürlich nicht zu unserer händischen Berechnung. Die Wohnnähe zur Uni hängt nicht damit zusammen, ob ein Nebenjob ausgeübt wird.
Effektstärken
Auch für den $\chi^2$-Test gibt es die Möglichkeit zur Einordnung der Effektstärke - in diesem Fall sind es sogar zwei verschiedene Varianten:
Yules Q
Dieses berechnet sich als
$$Q=\frac{n_{11}n_{22}-n_{12}n_{21}}{n_{11}n_{22}+n_{12}n_{21}},$$
welches einen Wertebereich von [-1,1] aufweist und analog zur Korrelation interpretiert werden kann. 1 steht in diesem Fall für einen perfekten positiven Zusammenhang (dazu in der entsprechenden Sitzung mehr).
In R sieht das so aus:
effekt_YulesQ <- (tab[1,1]*tab[2,2]-tab[1,2]*tab[2,1])/
(tab[1,1]*tab[2,2]+tab[1,2]*tab[2,1])
effekt_YulesQ
## [1] -0.1494775
Phi ($\phi$)
Auch kann man $\phi$ bestimmen:
$$\phi = \frac{n_{11}n_{22}-n_{12}n_{21}}{\sqrt{(n_{11}+n_{12})(n_{11}+n_{21})(n_{12}+n_{22})(n_{21}+n_{22})}}$$ welches einen Wertebereich von [-1,1] aufweist und analog zur Korrelation interpretiert werden kann. 1 steht in diesem Fall für einen perfekten positiven Zusammenhang (dazu in der entsprechenden Sitzung mehr).
In R sieht das so aus:
effekt_phi <- (tab[1,1]*tab[2,2]-tab[1,2]*tab[2,1])/
sqrt((tab[1,1]+tab[1,2])*(tab[1,1]+tab[2,1])*(tab[1,2]+tab[2,2])*(tab[2,1]+tab[2,2]))
effekt_phi
## [1] -0.06890118
Das Ganze lässt sich auch mit dem psych und der darin enthaltenen Funktion phi() umsetzen:
# alternativ mit psych Paket
library(psych)
phi(tab, digits = 8)
## [1] -0.06890118
Yule(tab)
## [1] -0.1494775
# Äquivalentes Ergebnis mittels Pearson-Korrelation (kommt in den nächsten Sitzungen)
# (dichotome Variablen)
ort_num <- as.numeric(fb25$ort)
job_num <- as.numeric(fb25$job)
cor(ort_num, job_num, use="pairwise")
## [1] -0.06890118
Cohen (1988) hat folgende Konventionen zur Beurteilung der Effektstärke $\phi$ vorgeschlagen, die man heranziehen kann, um den Effekt “bei kompletter Ahnungslosigkeit” einschätzen zu können (wissen wir mehr über den Sachverhalt, so sollten Effektstärken lieber im Bezug zu anderen Studienergebnissen interpretiert werden):
| phi | Interpretation |
|---|---|
| ~ .1 | kleiner Effekt |
| ~ .3 | mittlerer Effekt |
| ~ .5 | großer Effekt |
Der Wert für den Zusammenhang der beiden Variablen ist also bei völliger Ahnungslosigkeit als klein einzuschätzen.
Ergebnisinterpretation
Es wurde untersucht, ob Studierende mit Wohnort in Uninähe (also in Frankfurt) mit gleicher Wahrscheinlichkeit einen Nebenjob haben wie Studierende, deren Wohnort außerhalb von Frankfurt liegt. Zur Beantwortung der Fragestellung wurde ein Vierfelder-Chi-Quadrat-Test für unabhängige Stichproben berechnet. Der Zusammenhang zwischen Wohnort und Nebenjob ist nicht signifikant ($\chi^2$(1) = 0.964, p = 0.326), somit wird die Nullhypothese beibehalten. Der Effekt ist von vernachlässigbarer Stärke ($\phi$ = -0.069). Studierende mit Wohnort in Uninähe haben mit gleicher Wahrscheinlichkeit einen Nebenjob wie Studierende, deren Wohnort außerhalb von Frankfurt liegt.