 Created using DALL-E 2
Created using DALL-E 2Scatterplots und interaktiven Grafiken mit ggplot2
Im letzten Beitrag haben wir uns mit den Grundeigenschaften von ggplot2 befasst und uns dabei erstmal auf die Gestaltung von Balkendiagrammen konzentriert. Hier will ich das Ganze auf eine der typischen Abbildungen in den Sozialwissenschaften erweitern: den Scatterplot. Weil Printmedien aussterben gucken wir uns außerdem noch an, wie man Grafiken so erstellen kann, dass Leser:innen damit interagieren können, um mehr Informationen zu erhalten, die sich nicht auf einen Blick verpacken lassen.
Abschnitte in diesem Beitrag
- Kurze Beschreibung der Beispieldaten
- Erstellen von von Scatterplots mit verschiedenen Ästhetiken
- Faceting von Plots
- Erstellen und Anpassen von interaktiven Graphiken
Setup
Wie immer laden wir erstmal die benötigten Pakete und Daten:
# ggplot laden
library(ggplot2)
# Daten laden
load(url('https://pandar.netlify.app/daten/edu_exp.rda'))
# Datenaufbereitung
edu_exp$Wealth <- factor(edu_exp$Wealth, levels = c('low_income', 'lower_middle_income', 'upper_middle_income', 'high_income'),
labels = c('Low', 'Lower Mid', 'Upper Mid', 'High'))
edu_exp$Region <- factor(edu_exp$Region, levels = c('africa', 'americas', 'asia', 'europe'),
labels = c('Africa', 'Americas', 'Asia', 'Europe'))
Beispieldaten
Die Daten sind die selben wie auch im letzten Beitrag - eine Sammlung von verschiedenen Indikatoren zu Bildung und Bildungsausgaben in verschiedenen Ländern. Genauer sind die Variablen:
geo: Länderkürzel, das zur Identifikation der Länder über verschiedene Datenquellen hinweg genutzt wirdCountry: der Ländername im EnglischenWealth: Wohlstandseinschätzung des Landes, unterteilt in fünf GruppenRegion: Einteilung der Länder in die vier groben Regionenafrica,americas,asiaundeuropeYear: JahreszahlPopulation: BevölkerungExpectancy: Lebenserwartung eines Neugeborenen, sollten die Lebensumstände stabil bleiben.Income: Stetiger Wohlstandsindikator für das Land (GDP pro Person)Primary: Staatliche Ausgaben pro Schüler:in in der primären Bildung als Prozent desincome(GDP pro Person)Secondary: Staatliche Ausgaben pro Schüler:in in der sekundären Bildung als Prozent desincome(GDP pro Person)Tertiary: Staatliche Ausgaben pro Schüler:in oder Student:in in der tertiären Bildung als Prozent desincome(GDP pro Person)Index: Education Index des United Nations Development Programme
Der Index berechnet sich aus erwarteter ($EYS$) und tatsächlicher ($MYS$) Bildungsdauer einer Person in einem Land:
$$ Index = \frac{1}{2} \left( \frac{EYS}{18} + \frac{MYS}{15} \right) $$
Länder, in denen das Bildungssystem eine lange Ausbildungsdauer vorsieht (als Richtwert hier 18 Jahre) und in denen die Menschen auch tatsächlich lange Bildung erhalten (als Richtwert hier 15 Jahre), erzielen also die besten Werte.
Theme
Im letzten Beitrag hatten wir als letzten Punkt besprochen, wie wir Plots nach unserem (also eigentlich meinem) Geschmack angepasst hatten - dafür hatten wir vor allem Themes und Farbpaletten genutzt. Sie können sich eine Kombination aussuchen, die Ihnen gefällt - aber um diese Website in einem kohärenten Design zu halten und von der Corporate Design Abteilung meines Arbeitgebers keine unnötigen Emails zu erhalten, haben wir für pandaR ein spezifisches Theme und eine Farbpalette erstellt. Wir können diese direkt laden, indem wir das R-Skript ausführen, in dem sie definiert wurden:
# Laden des pandaR Themes
source('https://pandar.netlify.app/lehre/statistik-ii/pandar_theme.R')
In einem etwas älteren Beitrag ist auch detailliert beschrieben, wie Sie ihr eigenes Theme erstellen können und wie genau dieses zustande gekommen ist. Wenn Sie mit den pandaR Einstellungen arbeiten wollen, können Sie aber jederzeit einfach das Skript ausführen. Ein Theme kann auf jede Abbildung einzeln angewendet werden (in diesem Fall dann durch + theme_pandar()) oder wir können es global setzen:
theme_set(theme_pandar())
So wird es als Standardeinstellung für alle Abbildung in dieser Session von R genutzt.
Scatterplots
Bei den Balkendiagrammen, mit denen wir uns bisher beschäftigt hatten, handelt es sich um univariate Datendarstellung - in den meisten Fällen nutzen wir sie, um mehr Informationen über eine spezifische Variable darzustellen. Im letzten Beitrag hatten wir das noch um eine zweite Dimension (Farbe) erweitert und mit einem gruppierten Balkendiagramm so eine bivariate Abbildung gestaltet. Für beide Variablen ist es in so einer Darstellung aber nötig, dass sie höchstens ordinalskaliert sind bzw. nur wenige mögliche Ausprägungen haben.
Für die Darstellung von mindestens zwei intervallskalierten Variablen ist der Scatterplot das verbreiteste Werkzeug. Im letzten Semester hatten wir diese schon im Beitrag zu Korrelationen gesehen. Die waren damals allerdings nicht sonderlich hübsch - das ändern wir jetzt mit ggplot2.
Einfacher Scatterplot
Wie schon im letzten Beitrag schränken wir unsere Daten zunächst auf das Jahr 2014 ein:
edu_2014 <- subset(edu_exp, Year == 2014)
Zunächst interessiert uns der Zusammenhang zwischen der Bildungsinvestition in die Primärbildung (also z.B. Grundschulen) und dem tatsächlichen Bildungsindex, wie er vom UNDP genutzt wird. Deksriptivstatistische Informationen zu den Variablen können wir mit der Funktion describe() aus dem Paket psych erhalten:
psych::describe(edu_2014[, c('Primary', 'Index')])
## vars n mean sd median trimmed
## Primary 1 90 16.37 6.57 15.26 16.03
## Index 2 192 0.65 0.18 0.68 0.66
## mad min max range skew kurtosis
## Primary 6.89 3.48 36.54 33.06 0.49 -0.09
## Index 0.21 0.21 1.05 0.84 -0.28 -0.77
## se
## Primary 0.69
## Index 0.01
Wie wir sehen, liegen für die Investitionen in die Primärbildung nur Werte aus 90 Ländern vor, was unsere Abbildung positiv ausgedrückt zumindest übersichtlicher macht. Wir können diese Datenpunkte im Datensatz lassen und ggplot2 würde sie jedes Mal, wenn wir eine Abbildung erstellen, mit einer Warnmeldung automatisch entfernen. Allerdings wirkt sich das z.B. auf die Skalierung unserer Ästhetiken aus - z.B. würde bei der Bevölkerungszahl (die benutzen wir gleich) die Skalierung anhand das Maximums (China) festgelegt. Im Datensatz haben wir aber keine Informationen auf Primary von China und Indien, sodass die Skala gar nicht bis in die Milliarden gehen muss, sondern wir mit einer eingeschränkten Skala zufrieden wären. Um die Skalierung an Daten, die gar nicht genutzt werden zu verhindern, können wir - wie im letzten Beitrag betont - die Daten anpassen, bevor wir Abbildungen erstellen:
edu_2014 <- subset(edu_2014, !is.na(Primary) & !is.na(Index))
Wie im letzten Beitrag detailliert besprochen, bauen wir eine ggplot2-Abbildung aus drei Schichten: Daten, Ästhetik und Geometrie. Unsere Daten sind die gerade reduzierten Fälle für das Jahr 2014. Die “Ästhetik” ist die Projektion unserer Variablen auf eine optische Eigenschaft des Plots - in unserem Fall also Primary als x- und Index als y-Variable. Die Geometrie hat sich gegenüber den letzten Abbildungen auch verändert: statt Balken (geom_bar) wollen wir jetzt Punkte (geom_point) darstellen:
ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point()
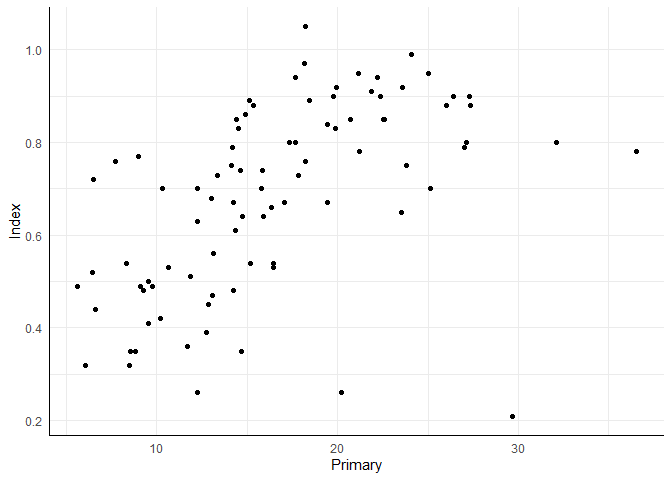
ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region)) +
scale_color_pandar()
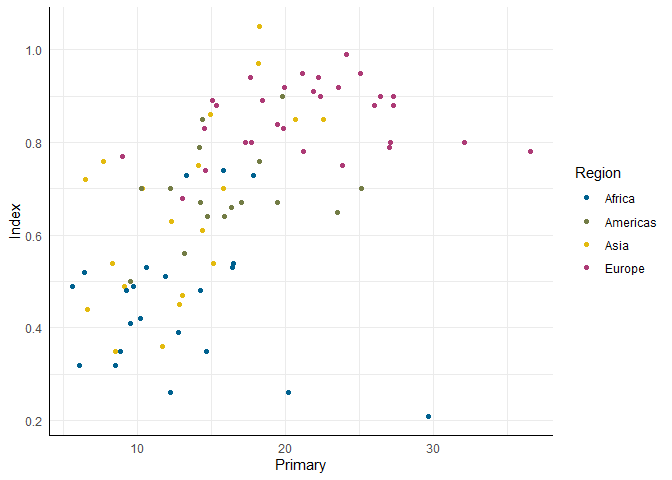
pch) nutzen, um die kategorialer Wohlstandseinschätzung der Länder darzustellen. Was auch sehr beliebt ist, ist die Größe der Punkte zu nutzen, um das “Gewicht” eines Datenpunkts darzustellen. In unserem Fall wäre z.B. die Bevölkerungszahl eines Landes relevant, weil jeder Punkt unterschiedlich viele Personen repräsentiert. Damit die Zahlen nicht exorbitant groß werden, skalieren wir sie noch in Millionen um:
edu_2014$Population <- edu_2014$Population / 1e6
# Scatterplot mit nominaler Farbästhetik und intervallskalierter Punktgröße
ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar()
Wenn uns die Benennung einer Ästhetik nicht gefällt (per Voreinstellung einfach der Variablenname), können wir in der dazugehörigen Skala (scale_...) das name-Argument benutzen, um etwas deskriptiveres auszusuchen. In diesem Fall wollen wir hinzufügen, dass die Bevölkerungszahl in Millionen zu verstehen ist. Das \n steht für “new line” und fügt einfach einen Zeilenumbruch ein.
# Anpassung der Benennung einer Ästhetik
ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar() + scale_size_continuous(name = 'Population\n(in Mio)')
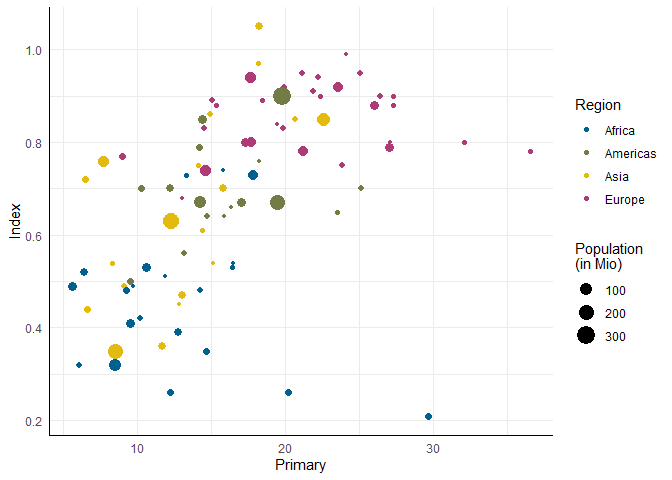
In der neuen Abbildung lassen sich einige Datenpunkte schon ziemlich leicht direkt identifizieren: der große (viele Leute) grüne (Amerikas) Punkt mit hohem Bildungsindex ist vermutlich die USA.
Faceting
Sehr viele Datenpunkte in der gleichen Abbildung darzustellen, kann mitunter sehr unübersichtlich werden. Z.B. könnten wir neben unserer Abbildung für 2014 auch noch Informationen über andere Jahre darstellen und müssten dafür neben Primary (x), Index (y), Region (Farbe) und Population (Größe) für Year auch noch eine fünfte Dimension aufnehmen. Probieren wir es erstmal aus, bevor wir uns entscheiden, dass es keine gute Idee war: zunächst erstellen wir einen Datensatz mit Informationen aus 1999, 2004, 2009 und 2014, um die Entwicklung der Ausgaben und Bildungsindizes in 5-Jahres-Abständen betrachten zu können.
# Datensatz mit mehreren Jahren
edu_sel <- subset(edu_exp, Year %in% c(1999, 2004, 2009, 2014))
edu_sel$Year <- as.factor(edu_sel$Year)
# Datenreduktion auf Zeilen, bei denen sowohl Primary als auch Index vorhanden sind
edu_sel <- subset(edu_sel, !is.na(Primary) & !is.na(Index))
# Population reskalieren
edu_sel$Population <- edu_sel$Population / 1e6
Beim Versuch, das alles in einer Abbildung darzustellen, wird es etwas chaotisch. Hier werden die verschiedenen Jahre über die Ästhetik der Punkt-Form (pch für Pointcharacter) “kenntlich” gemacht:
ggplot(edu_sel, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population, pch = Year)) +
scale_color_pandar() + scale_size_continuous(name = 'Population\n(in Mio)')
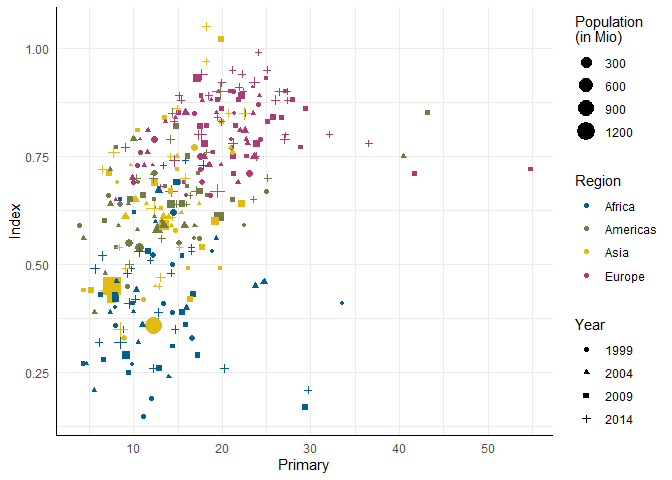
Eine Möglichkeit, in diesem Fall Übersichtlichkeit zu bewahren, ist das sogenannte Faceting. Dabei wird eine Abbildung anhand von Ausprägungen auf einer oder mehr Variablen in verschiedene Abbildungen unterteilt.
ggplot(edu_sel, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar() + scale_size_continuous(name = 'Population\n(in Mio)') +
facet_wrap(~ Year)
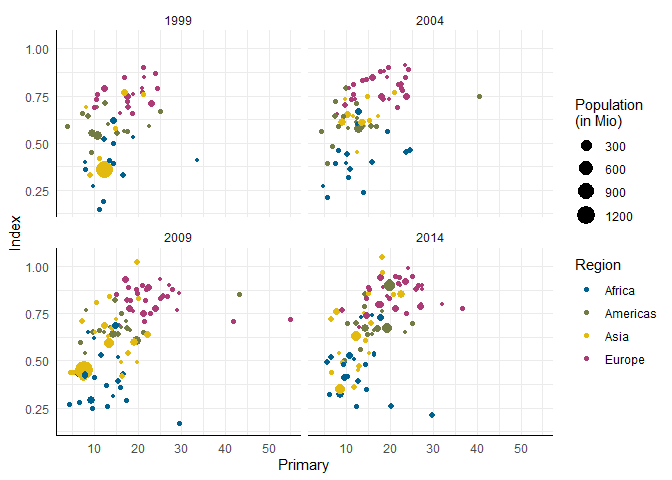
In facet_wrap wird wieder mit der R-Gleichungsnotation gearbeitet: hier wird der Plot anhand der unabhängigen Variablen hinter der Tilde in Gruppen eingeteilt. Das gibt auch wieder die Möglichkeit mit + mehrere Variablen zu definieren, die zum Faceting benutzt werden sollen. Wenn Sie Gruppen anhand von zwei Variablen bilden, bietet es sich außerdem an, facet_grid zu benutzen.
Per Voreinstellung wird beim Faceting eine gemeinsame Skalierung der x- und y-Achsen für alle Teilabbildungen festgelegt. Das kann mit dem Argument scales in der facet_wrap-Funktion umgangen werden. Bei ?facet_wrap finden Sie dafür genauere Informationen.
Interaktive Grafiken mit plotly
Die bisherigen Abbildungen haben alle eins gemeinsam: sie sind statisch. Das ist super, wenn wir unsere Ergebnisse irgendwo drucken möchten, aber die meisten modernen Darstellungsformen bieten einen gewissen Mehrwert durch Interaktivität der Inhalte. Nehmen wir als Beispiel nochmal unsere Abbildung für das Jahr 2014:
static <- ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar() + scale_size_continuous(name = 'Population\n(in Mio)')
Wir legen Sie hier zunächst in einem Objekt ab, statt sie einfach direkt ausgeben zu lassen, weil wir dieses Objekt direkt benutzen können, um eine interaktive Grafik daraus zu machen. Dafür brauchen wir aber zuerst noch das Paket plotly, dass wir zunächst installieren müssen:
if (!requireNamespace("plotly", quietly = TRUE)) {
install.packages("plotly")
}
Anschließend können wir es mit der library()-Funktion laden:
library(plotly)
## Warning: Paket 'plotly' wurde unter R Version
## 4.3.2 erstellt
##
## Attache Paket: 'plotly'
## Das folgende Objekt ist maskiert 'package:ggplot2':
##
## last_plot
## Das folgende Objekt ist maskiert 'package:stats':
##
## filter
## Das folgende Objekt ist maskiert 'package:graphics':
##
## layout
Plotly ist ein kommerzieller Anbieter für Datenvisualisierung in jedweder Form. Weil ich hier nicht mehr Werbung für kommerzielle Plattformen machen will, als zwingend erfoderlich, bedanke mich einfach für das gratis Paket und wir arbeiten damit weiter.
In plotly kann man über die Funktion plot_ly() interaktive Plots erstellen. Aber anstatt uns zu zwingen etwas komplett neues lernen zu müssen, erlaubt uns das Paket auch, mit ggplot() erstellte Grafiken in interaktive Grafiken zu übersetzen! Dafür gibt es die Funktion ggplotly():
ggplotly(static)
Wenn sie mit dem Cursor über einen Datenpunkt hovern, erhalten Sie genauere Informationen über diesen spezifischen Datenpunkt (die sogenannte “Hoverinfo”). Im aktuellen Fall sind das die genauen Ausprägungen der vier Variablen, die im Plot auch verarbeitet sind. Außerdem kann man mit dem Cursor einen Bereich im Plot markieren um in diesen herein zu zoomen. Die dritte Möglichkeit, mit dem Datenfenster zu interagieren, stellt die Legende dar. Hier kann man durch einfachen Klick die Datenpunkte der gewählten Gruppen aus- und einblenden.
Über diese Möglichkeiten hinaus bietet Plotly oben rechts einige Navigationsbuttons an. Von links nach rechts:
- Die Abbildung mit aktuellen Einstellungen als .png speichern.
- Das oben beschriebene Verhalten, mit dem man in bestimmte Bereiche des Plots hereinzoomen kann. Die Voreinstellung.
- Das Zoom-Verhalten ausschalten und stattdessen in den Pan-Modus wechseln.
- In den Box-Select Modus wechseln, um rechteckige Regionen von Datenpunkten auszuwählen.
- In den Lasso-Select Modus wechseln, um chaotische Regionen von Datenpunkten auszuwählen.
- Zoom in.
- Zoom out.
- Automatische Skalierung von x und y wählen.
- Auf die ursprüngliche Skalierung von x und y zurück setzen.
- “Spike lines” anzeigen, die dabei helfen, den Datenpunkt auf x und y zu verorten.
- Die Hoverinfo des nächstgelegenen Datenpunkts anzeigen. Die Voreinstellung.
- Die Hoverinfos von, auf der x-Achse naheliegenden Datenpunkten anzeigen.
Wie man sieht, sind das per Voreinstellung ziemlich viele Optionen, die bei weitem nicht immer alle nötig oder sinnvoll sind. Aber besonders zu Beginn können sie dabei helfen, die Daten genauer unter die Lupe zu nehmen.
Doppelte Legenden entfernen
In der Abbildung fallen direkt (nach dem kurzen Innehalten über die Wunder moderner Technik) zwei Probleme auf: Plotly scheint nicht sonderlich gut mit doppelten Legenden umzugehen und die Informationen, die wir bekommen, wenn wir mit dem Cursor einen Punkt markieren sind weder schön noch informativ.
Für Ersteres bleibt uns leider (nach meinem aktuellen Kenntnisstand) nur übrig, die Legende als Ganzes zu entfernen. Später können wir die Populationszahl in der Hoverinfo aber wieder hinzufügen. Weil die Legende im ursprünglichen ggplot enthalten war, müssen wir sie dort auch wieder entfernen. Leider müssen wir hierfür auf noch eine Funktion von ggplot2 zurückgreifen:
static <- ggplot(edu_2014, aes(x = Primary, y = Index)) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar() + guides(size = 'none')
In guides können wir die Legenden aller Ästhetiken ansprechen, die in der Abbildung genutzt werden. Mit size = 'none' legen wir fest, dass die Legende für die Ästhetik size nicht vorhanden sein soll.
Hoverinfo anpassen
Die Voreinstellung, in der Hoverinfo die vier bereits in der Abbildung dargestellten Variablen genauer anzugeben ist zwar intuitiv, aber in den meisten Fällen wollen wir dadurch ja zusätzliche Information gewinnen. Sehen wir uns zuerst an, wie man generell anpassen kann, was in der Hoverinfo erscheint.
Die ggplotly-Funktion, die wir nutzen, um unseren ggplot in eine interaktive Grafik zu überführen, nimmt das Argument tooltip entgegen. Die Hilfe unter ?ggplotly gibt dabei folgende Auskunft:
tooltip | a character vector specifying which aesthetic mappings to show in the tooltip. The default, “all”, means show all the aesthetic mappings (including the unofficial “text” aesthetic). The order of variables here will also control the order they appear. For example, use tooltip = c("y", "x", "colour") if you want y first, x second, and colour last. |
Dieses Argument erlaubt uns also die angezeigte Hoverinfo auszuwählen, indem wir die Ästhetiken auswählen, die angezeigt werden sollen. Hier ist es wichtig auf die Unterscheidung zwischen Ästhetiken und den zugrundliegenden Variablen zu achten! Wir können der Hilfe zufolge in unserem Fall also z.B.
ggplotly(static,
tooltip = c('colour', 'size', 'x', 'y'))
nutzen, um im Tooltip erste Informationen zur farbgebenden Variable (Wealth), dann zur Größenvariable (Population), dann zur x-Achse (Primary) und dann zur y-Achse (Index) anzeigen zu lassen. Leider werden wir hier von der Hilfe angelogen. Es ist ein seit 7 Jahren bekannter Bug, dass diese Sortierung nicht für die Übersetzung von ggplots funktioniert (wenn wir in Plotlys eigener Sprache schreiben würden, würde es funktionieren).
Der generell akzeptierte Workaround für all diese Probleme ist bereits im Hilfetext versteckt: “(including the unofficial “text” aesthetic)”. Für unsere Hoverinfos können wir also eine Ästhetik namens text nutzen, um nicht bereits im Plot enthaltene Informationen in gewünschter Reihenfolge anzeigen zu lassen. Dazu müssen wir leider unseren gesamten Plot mit der Zusatzästhetik neu generieren. Aber wenn wir schon dabei sind, können wir direkt alle neuen Informationen in die Hoverinfo einfügen, die wir so haben wollen.
Die neue Ästhetik text kann genau das enthalten, was sie verspricht: Text. Damit wir für jeden Datenpunkt eine eigene Beschriftung bekommen müssen wir also Text erzeugen, der von den Daten abhängt. Zum Glück bietet uns R mit paste eine relativ komfortable Weise, um massenweise Text zu erstellen. Z.B. könnten wir als Label für Spanien haben wollen:
## Spain
## Region: Europe
## Population (in mio): 46.46
(Die Kategorie von Wealth wird durch die Färbung ausgegeben und Primary und Index sind bereits in der Position des Punktes kodiert, sodass wir diese aus der Hoverinfo raus lassen können.) paste() klebt Textbausteine und Variablenausprägungen in einen character Vektor zusammen. Für die oben dargestellte Kombination benötigen wir also:
paste(Country,
'</br></br>Region:', Region,
'</br>Population (in mio):', round(tmp$Population, 2))
für unsere text-Ästhetik. So werden für jede Zeile unseres Datensatzes die Ausprägungen der drei aufgeführten Variablen mit den dazwischenstehenden Textbausteinen verbunden. Dieses Vorgehen hat den Vorteil, dass wir hier auch Variablen verarbeiten können, also nicht nur angezeigte oder rohe Informationen anzeigen können. Häufig bietet es sich z.B. an mit round() zu arbeiten, um die Anzeige übersichtlich zu halten. Die </br> in unserer Ästhetik sind einfache Zeilenumbrüche (breaks) in HTML, die Sprache in die unser Plot für die Anzeige übersetzt wird, bevor er vom Browser angezeigt werden kann.
Der finale Plot kann also so erstellt werden:
static <- ggplot(edu_2014, aes(x = Primary, y = Index,
text = paste(Country,
'</br></br>Region:', Region,
'</br>Population (in mio):', round(Population, 2)))) +
geom_point(aes(color = Region, size = Population)) +
scale_color_pandar() + guides(size = 'none')
So erstellen wir jetzt also den neuen ggplot. In dessen Anzeige hat sich überhaupt nichts geändert, weil text keine offizielle Ästhetik von ggplot ist. Wie wir es schon im letzten Abschnitt besprochen hatten, können wir mit dem tooltip-Argument jetzt noch angeben, welche Ästhetiken ggplotly in der Hoverinfo präsentieren soll. Per Voreinstellung würden hier alle ("all") angezeigt werden. Wie schon erwähnt sind x, y und Farbe ja eigentlich in den Achsenbeschriftungen und der Legende schon deutlich dargestellt, sodass wir die Informationen nicht noch einmal zusätzlich brauchen. Deswegen nutzen wir hier nur die Informationen, die wir in der text-Ästhetik abgelegt hatten. Als neue Grafik, mit neuer Hoverinfo ergibt sich dann:
ggplotly(static,
tooltip = 'text')