](/media/header/google_frogs.jpg)
Übersicht
Dieses Projekt befasst sich mit folgender Frage: “Welche politischen Parteien stehen im Zentrum des öffentlichen Interesses?”. Dazu wollen wir uns anschauen, wie sich die Anzahl von Google-Suchanfragen bezogen auf 9 deutsche Parteien seit 2004 entwickelt hat und diese Entwicklung in einer Grafik darstellen. Hat sich das Interesse an den Grünen in Folge der Nuklearkatastrophe in Fukushima im Jahr 2011 gesteigert? Sinkt das Such-Interesse an der SPD parallel zu ihren Umfragwerten in den letzten Jahren? Wie groß ist das Interesse an einer Spartenpartei wie der Tierschutzpartei im Netz? Das sind Fragen, die wir mithilfe der auf Google Trends öffentlich zugänglich gemachten Daten über Suchanfragen in Deutschland untersuchen können.
Zielsetzung
In diesem ersten Projekt geht es um das Verarbeiten von Datensätzen und die anschließende Darstellung von Daten mit dem R-Paket ggplot2. Ziel ist es also, dass du dich damit auseinandersetzt, wie Daten gut in R eingepflegt werden können, wie sie aufbereitet werden müssen, um gut darstellbar zu sein und wie sie abschließend in Grafiken dargestellt werden können. Es geht schlussendlich darum, eine gute und übersichtliche Aufbereitung der Daten für verschiedene Kontexte zu haben.
Vorbereitung
Zunächst rufen wir in einem neuen Tab des Browsers Google Trends auf.
Auf der Seite befindet sich ein Suchfeld, wo du den ersten Begriff eingeben und dir eine Statistik dazu anschauen kannst (bitte gebe als Beispiel einmal Affe ein). Nun kannst du andere Begriffe mit dem Beispiel vergleichen (gebe in das Feld “+Vergleichen” Giraffe ein). Du kannst bis zu vier Begriffe vergleichen.
Die Skala ist bei jeder Statistik sehr wichtig und kann fehlinterpretiert werden. Daher ist es sehr wichtig, dass du dich mit der Skala dieses Datensatzes befasst. Über jeder Abbildung befindet sich ein , wo die Skala erklärt wird. Hier wird jeder Punkt im Bezug zum höchsten Punkt dargestellt. Als wir diese Seite erstellt haben, sah das Ergebnis der Suche unseres Beispiels so aus:
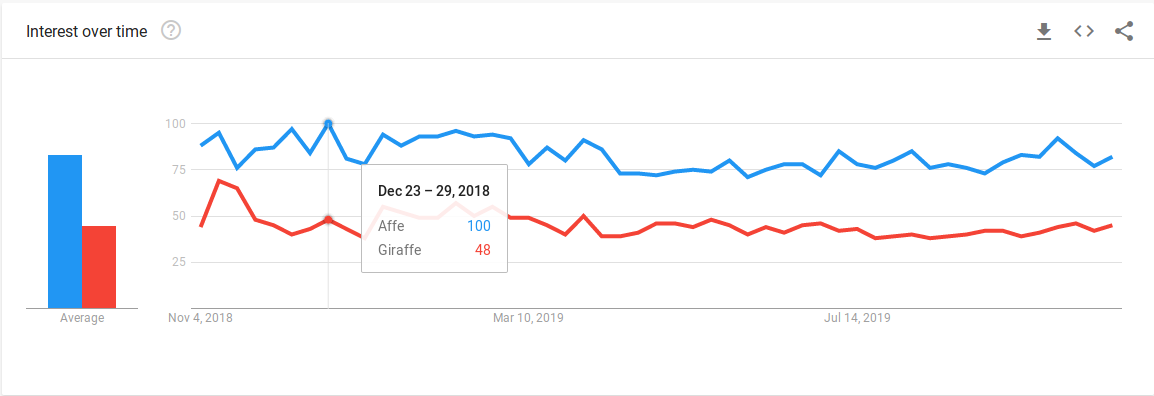
Das heißt also, dass bei uns der Suchbegriff Affe in der Woche vom 23. zum 29. Dezember den Maximalwert erreicht hat, und der Begriff Giraffe nur auf 48% dieser Menge von Suchanfragen gekommen ist. Je nach Bezugspunkt ändern sich also die Werte. Das ist sehr wichtig, wenn man verschiedene dieser Datensätze vergleichen will.
Die verschiedenen Datensätze kannst du über das Downloadzeichen oben rechts an jeder Abbildung herunterladen und in Excel öffnen. Speichere sie bitte immer in dem Ordner, in dem sich auch dein R-Skript befindet.
Zur grafischen Darstellung empfehlen wir, dass du mit ggplot2 arbeitest. Falls du noch nicht mit dem Paket gearbeitet hast oder eine Auffrischung haben möchtest, kannst du dir unseren Crash-Kurs dazu durchlesen. Einen deutschsprachigen Überblick über die Befehle von ggplot2 findest du in diesem PDF oder auf dieser Website der Allgemeinen Psychologie von der Uni Basel. Eine englischsprachige Einführung vom Autor und Erfinder von ggplot2 - Hadley Wickham - findest du in seinem Online-Buch “R for Data Science”.
Um ggplot benutzen zu können, musst du dir das passende Paket (ggplot2) herunterladen und es in deine R-Sitzung laden:
install.packages('ggplot2')
library(ggplot2)
Jeder Abschnitt des folgenden Projekts ist unterteilt in eine Aufgabenstellung, ein paar Tipps, die weiterhelfen sollen, wenn dir die Ideen ausgehen, und eine mögliche Lösung für die Umsetzung der Aufgabenstellung. Super wäre es natürlich, wenn du so viel wie möglich alleine schaffst. Falls du jedoch nicht weiterkommen solltest, kannst du jederzeit im Internet nachschauen, dort gibt es die besten Hilfestellungen (beispielsweise auf Seiten wie stackoverflow.com). Auch wir müssen oftmals im Internet nach dem richtigen Code suchen. Falls du noch nichts oder nur sehr wenig mit R zu tun haben solltest (oder wenn du dich unsicher fühlst), kannst du jederzeit auf den pandaR-Seiten zur Lehre vorbeischauen. Dort gibt es neben vielen statistischen Themen auch ein übersichtliches R-Intro, welches dich in die Welt von R einführt.
Und jetzt kann es losgehen - viel Spaß beim Bearbeiten dieses Projekts.
Aufgaben
Aufgabe 1: Datensammlung
Im ersten Schritt müssen die richtigen Daten beschafft werden. Wie schon beschrieben, finden wir diese auf der Google Trends Seite. Wir werden neun Begriffe miteinander vergleichen. Dies bedeutet, dass wir sie nicht alle auf einmal herunterladen können, sondern in zwei verschiedenen Datensätzen. Dabei ist es wichtig, den Bezugspunkt zu beachten, weil die Skala, auf der die Daten ausgegeben werden, immer in Bezug zum meistgesuchten Begriff gesetzt wird. Hier geht es uns darum, die Suchanfragen von neun deutschen Parteien zu vergleichen: SPD, CDU, Bündnis 90/Die Grünen, Die Linke, AfD, FDP, MLPD, Die Tierschutzpartei und NPD. Wenn du möchtest, kannst du auch eigene Begriffe benutzen. Diese sollten jedoch vergleichbar sein (ein ähnliches Thema beinhalten) und es sollten auch neun Begriffe sein.
Bei jedem Vergleich solltest du die Einstellung Deutschland und 2004-heute wählen, um vergleichbare Ergebnisse zu erhalten. Wenn du eine Partei suchst, erscheint außerdem eine automatische Ergänzung mit der Unterschrift “Politische Partei”, die du nutzen solltest, um potentielle Zweideutigkeiten der Abkürzungen zu vermeiden.
Den Datensatz kannst du wie beschrieben herunterladen. Dann solltest du zwei .csv-Dateien haben, die du jeweils in R einlesen kannst.
Wenn du die Aufgabenstellung des ersten Teils bereits abgeschlossen haben solltest - mit und ohne Tipps -, kannst du nun dein Ergebnis mit der Lösung vergleichen. Natürlich gibt es in R in den meisten Fällen viele verschiedene Möglichkeiten, das gleiche Ergebnis zu erhalten. In diesem Fall ist der Weg jedoch nicht unbedingt das Ziel, denn uns geht es hauptsächlich darum, unsere Aufgabenstellung zu lösen - egal, wie wir das erreichen.
Lösung
Um 9 Parteien gleichzeitig abbilden zu können, ist es notwendig, zwei separate Anfragen bei Google Trends zu starten. In beiden sollte die Alternative für Deutschland als Referenzpartei enthalten sein, weil die Suchanfragen bezüglich der AfD um die Bundestagswahl 2017 herum das Maximum bilden und demzufolge den Referenzwert 100 setzen, an dem alle anderen Suchanfragen skaliert werden müssen. Mit dem Button erhältst du dann eine Datei mit dem Namen multiTimeline.csv. Wenn du beide Suchanfragen hintereinander durchführst, sollte die zweite Datei dann multiTimeline(1).csv heißen. Du kannst aber auch beiden Dateien beim Download beliebige Namen geben.
Bevor du die beiden Dateien in R einliest, kannst du ein bisschen Schreibarbeit sparen, wenn du erst den Arbeitsordner (working directory) festlegst. Idealerweise solltest du einen Ordner anlegen, in dem du alle relevanten Dateien für dieses Projekt speicherst.
setwd('...') # statt '...' einen Ordner-Pfad festlegen
Die beiden Datensätze können dann mit
a <- read.table('multiTimeline.csv', header = TRUE, sep= ',')
b <- read.table('multiTimeline(1).csv', header = TRUE, sep = ',')
eingelesen werden. Neben dem Dateinamen müssen hier das Argument header (der Datensatz enthält in der 1. Zeile die Variablennamen) und sep - das Trennzeichen zwischen Variablen - festgelegt werden.
Die ersten Zeilen der beiden Datensätze sollten dann so aussehen:
head(a)
## Monat Alternative.für.Deutschland...Deutschland.
## 1 2004-01 <1
## 2 2004-02 <1
## 3 2004-03 <1
## 4 2004-04 <1
## 5 2004-05 <1
## 6 2004-06 <1
## Sozialdemokratische.Partei.Deutschlands...Deutschland. Freie.Demokratische.Partei...Deutschland.
## 1 10 4
## 2 13 4
## 3 13 4
## 4 11 3
## 5 12 5
## 6 16 7
## Bündnis.90.Die.Grünen...Deutschland. Die.Linke...Deutschland.
## 1 4 <1
## 2 4 <1
## 3 4 1
## 4 3 <1
## 5 4 <1
## 6 8 <1
head(b)
## Monat Alternative.für.Deutschland...Deutschland. Partei.Mensch.Umwelt.Tierschutz...Deutschland.
## 1 2004-01 <1 0
## 2 2004-02 <1 0
## 3 2004-03 <1 <1
## 4 2004-04 <1 <1
## 5 2004-05 <1 <1
## 6 2004-06 <1 1
## Christlich.Demokratische.Union.Deutschlands...Deutschland.
## 1 8
## 2 10
## 3 9
## 4 9
## 5 11
## 6 14
## Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.
## 1 <1
## 2 <1
## 3 <1
## 4 <1
## 5 <1
## 6 <1
## Nationaldemokratische.Partei.Deutschlands...Deutschland.
## 1 2
## 2 2
## 3 2
## 4 2
## 5 3
## 6 4
Falls du Probleme mit dem Generieren der Datensätze hast, kannst du die beiden Dateien hier und hier herunterladen.
Aufgabe 2: Datenaufbereitung
Im Anschluss müssen wir beide Datensätze zusammenfügen, um sie in einer Abbildung darstellen zu können. Falls du den Befehl dafür nicht kennst, versuche ihn über die interne Hilfefunktion in R zu finden. Ansonsten kannst du es auch im Internet versuchen. Schaue dir den Datensatz anschließend ein wenig an, um ein Gefühl für Inhalt und Struktur der Daten zu bekommen. Dazu kannst du generelle Informationen (wie die Anzahl an Zeilen und Spalten) nutzen oder dir auch direkt die Rohdaten ansehen und durchscrollen. Wenn dir in diesem Schritt Dinge am Datensatz auffallen, die verändert werden sollten, veändere sie!
Falls du von alleine nicht weiterkommen solltest, kannst du dir die folgenden Tipps anschauen:
Wichtige Vorüberlegungen
Natürlich könntest du die beiden Datensätze direkt zusammenfügen, doch dann stößt man auf ein Problem. Sowohl das Datum als auch die Werte der Referenzkategorie (in unserem Fall die AfD) treten in beiden Datensätzen auf. Fügt man beide Datensätze nun zusammen, kämen beide Variablen doppelt und jeweils mit der gleichen Bezeichnung vor. Das heißt, dass du die Spalte “AfD” in einem der beiden Datensätze direkt löschen musst. Eine andere Möglichkeit wäre, dass du irgendwie dafür sorgst, dass sich die beiden Variablen in ihrem Namen unterscheiden, sodass sie im zusammengefügten Datensatz einmal gelöscht werden kann.
Datensätze zusammenführen
Nun kannst du dazu übergehen, die beiden Datensätze zusammenzuführen Dafür ist es am einfachsten, sie “aneinanderzuhängen” anstatt sie “zusammenzufügen”. Das kannst du mit dem cbind-Befehl in R erreichen. Schau dir diesen Befehl am besten in der R-Hilfefunktion an.
Falls du den Befehl nicht verstehst, folgt hier eine kurze Erklärung des Befehls:
Datensatz <- cbind("Datensatz_A","Datensatz_B")
Voraussetzung für das Funktionieren dieses Befehls in unserem Beispiel ist, dass die Anzahl der Zeilen beider Datensätze übereinstimmt. Als Output erhält man einen Datensatz, bei dem Datensatz_B “hinten” an Datensatz_A angehängt wurde.
Das Endergebnis sollte ein Datensatz mit 190 Zeilen und 10 Spalten sein.
Anpassung der Variablenart: Teil 1
Hier stellt sich die Frage: Liegen alle Daten in der Variablenart vor, die man benötigt? Die Variablenart jeder Variable (Spalte) lässt sich mit folgendem Befehl abfragen:
class(Variablenname)
Hier bekommt man also eine Angabe zum Typ der Variablen. Wie du im R Crash Kurs nachlesen kannst, sind Zahlen zum Beispiel als numeric (oder abgekürzt num) abgelegt. Im besonderen Fall, dass eine numerische Variable nur ganze Zahlen enthält, wird sie als integer (kurz: int) abgelegt. Es handelt sich aber nach wie vor um eine Zahl. Unser Ziel ist, dass alle Variablen im Typ int oder num vorliegen, sodass R diese auch als Zahlenwerte erkennt.
Überprüfe dafür jede Variable und überlege dir, welche Werte ein Problem darstellen. Falls du nicht weiterkommst, nutze Teil 2 des Tipps.
Anpassung der Variablenart: Teil 2
Im Rohdatensatz kann man erkennen, dass die “<1” weder integer noch numeric sind. Dadurch erkennt R all jene Variablen (Spalten), in denen “<1” mindestens ein Mal vorkommt, nicht als Zahlen. Deshalb müssen wir diese “<1” irgendwie durch “0” ersetzen.
Ziel ist also, dass im zusammengesetzten Datensatz, überall wo zuvor der Wert “<1” stand, eine Null steht. Um das zu erreichen, kannst du die Daten entweder hinterher bearbeiten oder diese Besonderheit direkt beim Einlesen mit read.table berücksichtigen. Dort kannst du mit einem Argument die Kodierung fehlender Werte festlegen. So gelangst du der Umwandlung von “<1” zu “0” einen Schritt näher.
Falls du ab hier nicht weiter weißt, nutze die Hilfefunktion in R oder suche online.
Wenn du fertig mit der Bearbeitung der Aufgabenstellung sein solltest, kannst du dein Ergebnis jetzt mit der Lösung vergleichen. Wie auch beim ersten Teil (und eigentlich immer bei R) gilt, dass es mehrere Wege zum gleichen Ziel geben kann:
Lösung
Bevor die beiden Datensätze zusammengeführt werden können, sollten zunächst doppelt vorkommende Spalten umbenannt werden, damit sie hinterher weniger Probleme machen. Um zu sehen, welche Namen in beiden auftauchen, können wir names benutzen:
names(a)
## [1] "Monat"
## [2] "Alternative.für.Deutschland...Deutschland."
## [3] "Sozialdemokratische.Partei.Deutschlands...Deutschland."
## [4] "Freie.Demokratische.Partei...Deutschland."
## [5] "Bündnis.90.Die.Grünen...Deutschland."
## [6] "Die.Linke...Deutschland."
names(b)
## [1] "Monat"
## [2] "Alternative.für.Deutschland...Deutschland."
## [3] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [4] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [5] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [6] "Nationaldemokratische.Partei.Deutschlands...Deutschland."
Hier sind also die ersten beiden Spalten doppelt. Wir können diese beiden einfach aus b entfernen:
b <- b[, -c(1, 2)]
names(b)
## [1] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [2] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [3] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [4] "Nationaldemokratische.Partei.Deutschlands...Deutschland."
Um beide zusammenzufügen, dann:
c <- cbind(a, b)
Das Problem dieses kombinierten Datensatzes ist, dass nicht alle Variablen numerisch sind. Das bewirkt, dass die Variablen nur sehr schwer in einer gemeinsamen Abbildung dargestellt werden können:
str(c)
## 'data.frame': 190 obs. of 10 variables:
## $ Monat : chr "2004-01" "2004-02" "2004-03" "2004-04" ...
## $ Alternative.für.Deutschland...Deutschland. : chr "<1" "<1" "<1" "<1" ...
## $ Sozialdemokratische.Partei.Deutschlands...Deutschland. : int 10 13 13 11 12 16 9 11 17 9 ...
## $ Freie.Demokratische.Partei...Deutschland. : int 4 4 4 3 5 7 3 3 8 4 ...
## $ Bündnis.90.Die.Grünen...Deutschland. : int 4 4 4 3 4 8 3 3 6 4 ...
## $ Die.Linke...Deutschland. : chr "<1" "<1" "1" "<1" ...
## $ Partei.Mensch.Umwelt.Tierschutz...Deutschland. : chr "0" "0" "<1" "<1" ...
## $ Christlich.Demokratische.Union.Deutschlands...Deutschland. : int 8 10 9 9 11 14 8 8 16 9 ...
## $ Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.: chr "<1" "<1" "<1" "<1" ...
## $ Nationaldemokratische.Partei.Deutschlands...Deutschland. : int 2 2 2 2 3 4 2 3 15 7 ...
Das kommt daher, dass der Wert <1 nicht als numerisch interpretiert wird, sondern als eine Beschriftung, sodass die Variable in R automatisch als factor erkannt und als nominalskaliert behandelt wird. Diese Werte müssen also alle ersetzt werden, um wieder mit numerischen Daten rechnen zu können.
Das ließe sich z.B. dadurch erreichen, dass wir in c alle Werte einzeln ersetzen. Dieses Vorgehen hat allerdings den Nachteil, dass es sehr viele einzelne Schritte benötigt, weswegen wir hier einen Trick anwenden: wir lesen die Daten als numerisch ein und tun dabei so, als wären <1 fehlende Werte. Das können wir durch das Argument na = im read.table-Befehl erreichen, den wir zum Einlesen der Daten genutzt haben:
# Daten einlesen
a <- read.table('multiTimeline.csv',header = T, sep= ',' , na = '<1')
b <- read.table('multiTimeline(1).csv', header = T , sep = ',' , na = '<1')
# Daten zusammenführen
b <- b[, -c(1, 2)]
c <- cbind(a, b)
# Struktur untersuchen
str(c)
## 'data.frame': 190 obs. of 10 variables:
## $ Monat : chr "2004-01" "2004-02" "2004-03" "2004-04" ...
## $ Alternative.für.Deutschland...Deutschland. : int NA NA NA NA NA NA NA NA NA NA ...
## $ Sozialdemokratische.Partei.Deutschlands...Deutschland. : int 10 13 13 11 12 16 9 11 17 9 ...
## $ Freie.Demokratische.Partei...Deutschland. : int 4 4 4 3 5 7 3 3 8 4 ...
## $ Bündnis.90.Die.Grünen...Deutschland. : int 4 4 4 3 4 8 3 3 6 4 ...
## $ Die.Linke...Deutschland. : int NA NA 1 NA NA NA NA NA NA NA ...
## $ Partei.Mensch.Umwelt.Tierschutz...Deutschland. : int 0 0 NA NA NA 1 NA 0 NA NA ...
## $ Christlich.Demokratische.Union.Deutschlands...Deutschland. : int 8 10 9 9 11 14 8 8 16 9 ...
## $ Marxistisch.Leninistische.Partei.Deutschlands...Deutschland.: int NA NA NA NA NA NA NA NA 1 NA ...
## $ Nationaldemokratische.Partei.Deutschlands...Deutschland. : int 2 2 2 2 3 4 2 3 15 7 ...
Jetzt sind alle Variablen außer Monat als integer (also eine Sonderform numerischer Variablen) abgespeichert. Das heißt, wir müssen nun lediglich die mit NA als fehlend markierten Beobachtungen durch 0 ersetzen:
c[is.na(c)] <- 0
Im letzten Schritt zur Datenaufbereitung vergeben wir noch etwas kürzere Namen für die Spalten:
names(c)
## [1] "Monat"
## [2] "Alternative.für.Deutschland...Deutschland."
## [3] "Sozialdemokratische.Partei.Deutschlands...Deutschland."
## [4] "Freie.Demokratische.Partei...Deutschland."
## [5] "Bündnis.90.Die.Grünen...Deutschland."
## [6] "Die.Linke...Deutschland."
## [7] "Partei.Mensch.Umwelt.Tierschutz...Deutschland."
## [8] "Christlich.Demokratische.Union.Deutschlands...Deutschland."
## [9] "Marxistisch.Leninistische.Partei.Deutschlands...Deutschland."
## [10] "Nationaldemokratische.Partei.Deutschlands...Deutschland."
names(c) <- c('Monat', 'AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD')
Aufgabe 3: Abbildungen erstellen
Zu guter Letzt fehlt noch das eigentliche Diagramm. Denk daran, dass du zunächst einen Befehl brauchst, der den Hintergrund erstellt und mit ‘+’ immer neue Ebenen hinzufügen kannst - wenn du es noch nicht getan hast, kannst du dafür auf unserem ggplot Crash-Kurs nachschauen. Gestalte das Diagramm so, dass es für jeden verständlich ist. Hierfür benötigst du unter Anderem
- verschiedene Farben,
- eine eingängige Achsenbeschriftung,
- einen aussagekräftigen Titel und
- eine Legende.
Es gibt noch viele weitere Dinge, mit denen du dein Diagramm verschönern kannst. Lass deiner Fantasie freien Lauf…
Falls du von alleine nicht weiterkommen solltest, kannst du dir den folgenden Tipp anschauen:
Umstrukturierung der Daten
Das Ziel der Umformung ist, dass eine Zeile des Datensatzes aus Datum, Partei und Prozentzahl besteht. Dadurch erhält man einen Datensatz aus 1710 Zeilen und 3 Spalten.
Dafür kann man den reshape-Befehl benutzen:
langer_Datensatz <- reshape(Datensatz, varying = ...,
v.names = ..., timevar = ...,
idvar = ..., times = ...,
direction = "long")
varying: Vektor mit den Spaltenbezeichnungen im vorhandenen Datensatz.v.names: gemessene Größe (Werte), die von mehreren Spalten in eine Spalte übertragen werden sollen.timevar: Bezeichnung für die Variable, die alle Spaltennamen enthält.times: Die vorherigen Variablennamen (Spaltennamen), die nun Werte einer durch timevar bezeichneten Variable sind.idvar: Name der Variable, die die einzelnen Messwerte einer Gruppe (Spalte) auseinanderhält.direction: Bezeichnung des neuen Formats. Kann entweder “wide” oder “long” sein. Wir brauchen das “long”-Format.
Nutzung von `ggplot`
Wenn das Paket geladen ist, kann als Grundbefehl ggplot genutzt werden. Dieser kann zunächst die unterste Ebene der Abbildung (die Daten) als Argument entgegennehmen:
ggplot(data = Datensatz)
Weil wir daran interessiert sind, bestimmte Variablen abzubilden, können wir diese in der Abbildung “mappen” oder abbilden:
ggplot(data = Datensatz, mapping = aes(x = ..., y = ..., group = ...))
Diese “Aesthetics” dienen dazu, zu definieren, wie die Variablen im Diagramm dargestellt werden. Dafür können wir festlegen, welche Variable auf der x-Achse und welche auf der y-Achse dargestellt wird. Zusätzlich können wir über group auch noch eine Gruppierung der $(x, y)$-Kombinationen festlegen und diese zum Beispiel später benutzen, um unterschiedlichen Daten unterschiedliche Farben zu geben, damit diese Gruppen optisch leichter voneinander unterscheiden werden können.
Zusätzlich zu dieser Basis muss noch durch ein geom festgelegt werden, wie die Daten anzeigt werden sollen, die wir abbilden. Weil es sich um Zeitverläufe handelt, bietet sich ein Liniendiagramm an. Für die Farbe der Linien können wir die Gruppierungsvariable direkt wieder benutzen!
geom_line(aes(colour = ...))
Wenn du fertig mit der Bearbeitung der Aufgabenstellung sein solltest, kannst du dein Ergebnis jetzt mit der Lösung vergleichen. Wie auch bei den ersten Teilen (und eigentlich immer bei R) gilt, dass es mehrere Wege zum gleichen Ziel geben kann:
Lösung
Zunächst müssen wir das Paket `ggplot2` laden:
library(ggplot2)
Wie bei den Tipps oder auch bei der Kurzeinführung in ggplot2 besprochen, erwartet der ggplot-Befehl einen Datensatz mit Variablen, die wir auf x- und y-Achse darstellen wollen und eventuell eine Gruppierungsvariable. Die x-Achse ist in unserem Fall sehr einfach: es ist die Zeit. Das Problem stellt die y-Achse dar: hierfür haben wir zur Zeit nicht 1 sondern 9 Variablen. Darüber hinaus sind diese 9 Variablen eine Mischung aus unserer y-Achse und der Gruppierungsvariable! Was wir benötigen, um eine klare Abbildung in ggplot2 zu erzeugen, ist ein Datensatz, der die drei “klassischen” Variablen enthält (x, y, Gruppe). Dafür können wir den reshape-Befehl nutzen:
c_long <- reshape(c, # Ausgansdaten
varying = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
# alle Variablen, die hinterher eine einzige Variable sein sollen
v.names = 'Prozent', # Name der neuen Variable
idvar = 'Monat', # Variable, die über alle Parteien gleich bleibt
timevar = 'Partei', # Name der Variable, die verschiedene Gruppen unterscheidet
times = c('AfD', 'SPD', 'FDP', 'DieGrüne', 'DieLinke', 'Tierschutzpartei', 'CDU', 'MLPD', 'NPD'),
# Kodierung der Parteien auf dieser Gruppierungsvariable
direction = 'long') # Richtung der Umwandlung
Hier wird der Datensatz ins long-Format übertragen - er hat hinterher mehr Zeilen (ist also länger) als vorher. Das Gegenteil wäre das wide-Format, in dem ein Datensatz mehr Spalten bekommt (also breiter wird) als zuvor.
Mit diesem Datensatz können wir in ggplot2 direkt ein Liniendiagramm erzeugen:
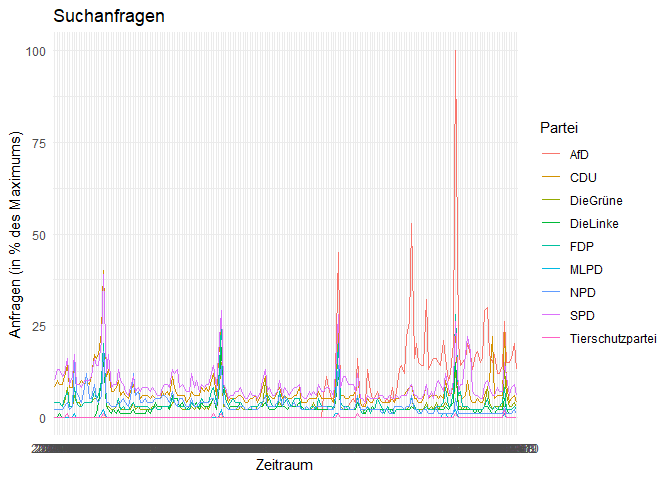
ggplot(data = c_long, aes(x = Monat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift
Aufgabe 4: Verfeinerung der Abbildung
Beim Anblick des Diagramms wirst du erkennen, dass R die Monate nicht richtig darstellen kann. Es gibt Möglichkeiten, diese Spalte zu formatieren, sodass R sie als Datum erkennt und nicht als Faktor. Die Variable Monat sollte nach dieser Umformung die Klasse POSIXct haben.
Die meisten Parteien werden immer mit einer spezifischen Farbe dargestellt. Um die Grafik schnell verständlich zu machen, kann jeder Partei ihre “typische” Farbe zugewiesen werden.
Eine weitere Möglichkeit, den Graphen zu verbessern, ist das Verhältnis zwischen dem höchsten Wert und den niedrigeren Werten durch Transformation der Variable zu verringern oder extreme (z.B. sehr hohe) Werte aus der Grafik auszuschließen. Das kann man machen, um Unterschiede zwischen den nicht so häufig gesuchten Parteien zu finden.
Falls du von alleine nicht weiterkommen solltest, kannst du dir den folgenden Tipp anschauen:
In diesem Tipp geht es darum, eine “richtige” Datumsvariable zu erstellen. Die Überführung der Datumsvariable im Datensatz in eine solche Datumsvariable, die auch von R intern als Datum repäsentiert wird, erfordert einige Schritte, von denen ein paar nicht ganz intuitiv sind.
Schritt 1 anzeigen
Um die Daten in eine neue Klasse überführen zu können, müssen sie zunächst als character vorliegen. Erstelle dafür eine zweite Datumsvariable, in der das der Fall ist.
Schritt 2 anzeigen
Unser Ziel ist, dass R diese neu erstellte Variable als Datum erkennt. Dafür gibt es in R eine Klasse mit dem Namen POSIXct. Für die Umwandlung character zu POSIXct oder POSIXlt gibt es einen bestimmten Befehl. Such diesen im Internet und schau dir dann die Hilfefunktion in R dazu an.
Schritt 3 anzeigen
Falls du den Befehl aus Schritt 2 nicht finden solltest, sieht der benötigt Befehl so aus: strptime(x, format = ""). x ist in diesem Fall die Variable, die umgewandelt werden soll und das format übermittelt R, wie die Daten momentan aussehen. Der Befehl funktioniert so jedoch noch nicht. Woran könnte das liegen? Schau dafür in die R-Hilfe zum Argument format.
Schritt 4 anzeigen
Das Problem liegt in den vorliegenden Daten. R kann diese Umwandlung nur mit einem character vornehmen, der mindestens Jahr, Monat und Tag enthält. Diese werden in der Hilfe von strptime je nach Formatierung unterschiedlich bezeichnet - z.B. wird %d für den Tag (01 - 31), %m für den Monat (01 - 12) und %y für das Jahr (00-99) genutzt. Unseren Daten fehlt der Tag! Um die Umwandlung vornehmen zu können, muss man also die Daten modifizieren. Schau dir dafür mal den Befehl paste0 in der R-Hilfefunktion und im Internet an.
Schritt 5 anzeigen
paste0 “klebt” die Argumente, die der Funktion gegeben werden aneinander. Die 0 bedeutet dabei, dass sie durch nichts getrennt werden sollen. Z.B. könnten wir den Befehl benutzen um einen beliebigen Satz zu schreiben:
paste0('Ich will', ' Kuchen.')
## [1] "Ich will Kuchen."
In paste0 können aber auch Variablen genutzt werden, um jeder Beobachtung etwas hinzuzufügen. In unserem Fall müssen wir uns also einfach nur irgendeinen Tag im Monat aussuchen und diesen an unsere Datumsvariable anheften.
Danach sollte auch die Umwandlung in die Datumsklasse funktionieren.
Schritt 6 anzeigen
Ist die Variable ein POSIXct? Überprüf das mit dem Befehl class(Variable). Sofern das nicht der Fall sein sollte, schau im Internet nach einer Lösung für das Problem.
Ergebnis:
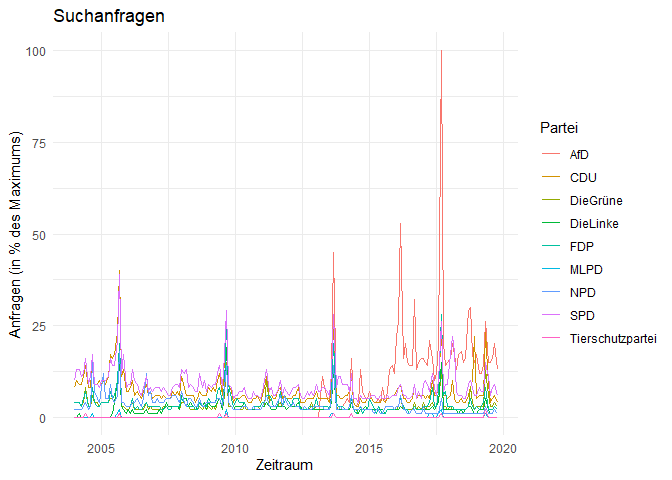
Kopiere den Befehl reshape- und den ggplot-Befehl und ersetze jeweils die alte Monatsvariable (Variablentyp: factor) durch die neue Monatsvariable (Variablentyp: POSIXct). Jetzt sollte die Graphik auf der x-Achse nur noch mit den 4 Jahreszahlen 2005, 2010, 2015 und 2020 beschriftet sein.
Wenn du fertig mit der Bearbeitung der Aufgabenstellung sein solltest, kannst du dein Ergebnis jetzt mit der Lösung vergleichen. Wie auch bei den ersten Teilen (und eigentlich immer bei R) gilt, dass es mehrere Wege zum gleichen Ziel geben kann:
Lösung
Die Abbildung aus Schritt 1 ist noch nicht sonderlich schön. Das erste offensichtliche Manko ist, dass es unmöglich ist, die Zeit an der x-Achse abzulesen. Um diesen Zustand zu beheben, muss die Zeit in eine “echte” Zeitvariable im POSIXct-Format umgewandelt werden:
class(c_long$Monat)
## [1] "character"
Für die Umwandlung ins POSIXct-Format gibt es eine Funktion namens strptime. Diese funktioniert allerdings wesentlich besser, wenn die Ausgangsvariable eine character-Variable ist. Also müssen wir die Zeit erst in eine Text-Variable umwandeln (dafür erstellen wir vorsichtshalber eine neue Variable):
c_long$nMonat <- as.character(c_long$Monat)
Aus der Hilfe zu strptime wird ersichtlich, dass immer mindestens Tag, Monat und Jahr in Zeitvariablen erwartet werden. Daher müssen wir der neuen Text-Variable noch einen Tag hinzufügen. Der genaue Tag macht dabei keinen Unterschied (weil unsere Daten ja nur monatlich sind) - wir nehmen einfach den 1. jeden Monats:
c_long$nMonat <- paste0(c_long$nMonat, '-01')
head(c_long$nMonat)
## [1] "2004-01-01" "2004-02-01" "2004-03-01" "2004-04-01" "2004-05-01" "2004-06-01"
So hat die neue nMonat-Variable ein typisches Zeitformat: Jahr-Monat-Tag. Dieses Format erkennt strptime leider nicht automatisch, also müssen wir via format-Argument ansagen, wie unsere Daten aussehen:
c_long$nMonat <- strptime(c_long$nMonat,
format="%Y-%m-%d") # Format des Datums
Aus der Hilfe von strptime sehen wir, dass %Y Jahre (mit Jahrhunderten), %m Monate (in Zahlen) und %d Tage sind. Die Variable wird nur folgendermaßen klassifiziert.
class(c$nMonat)
## [1] "NULL"
Das ist zwar leider nicht die richtige Klasse, aber das Problem lässt sich schnell beheben:
c_long$nMonat <- as.POSIXct(c_long$nMonat)
Wenn wir jetzt die Abbildung erneut erstellen, sieht die x-Achse schon viel besser aus:
ggplot(data = c_long, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift
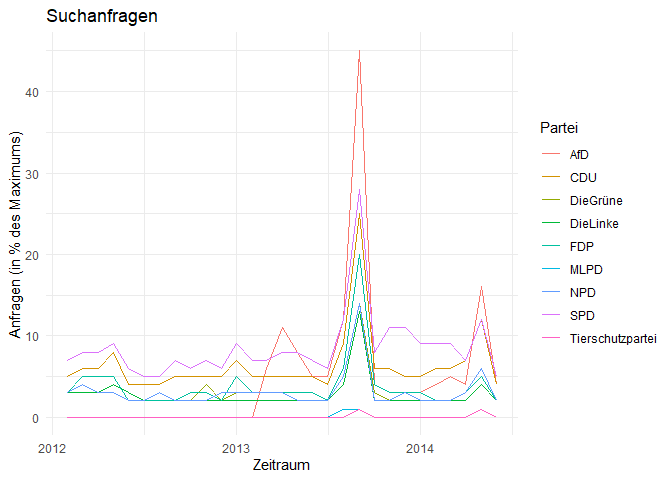
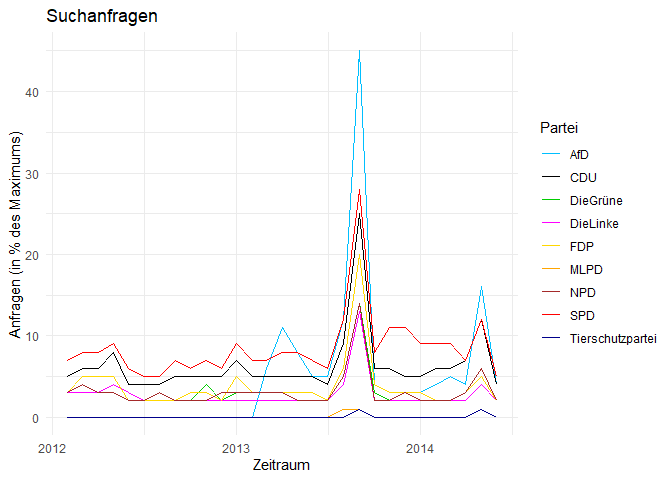
Um bestimmte Abschnitte näher unter die Lupe zu nehmen, können wir jetzt Anhand der Zeitvariable spezifische Auswahlen treffen. Wenn wir uns z.B. den Zeitraum um die Bundestagswahl von 2013 näher angucken möchten, können wir uns auf die Jahre zwischen 2012 und 2014 konzentrieren:
wahl_2013 <- subset(c_long, subset = (nMonat < '2014-07-01' & nMonat > '2012-01-01'))
ggplot(data = wahl_2013, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') # Überschrift
Ein weiteres Manko bei diesen Abbildungen sind die verwirrenden Farben. In Deutschland gibt es ein relativ konsistent genutzes Schema, nach dem die politische Parteien durch bestimmte Farben dargestellt werden. Wir können dieses Schema auch in unserer Abbildungen nutzen, wenn wir die Farben per Hand vergeben und dann mit scale_color_manual in unseren Plot aufnehmen:
farben <- c('AfD' = 'deepskyblue', 'CDU' = 'black', 'DieGrüne' = 'green3',
'DieLinke' = 'magenta', 'FDP' = 'gold', 'MLPD' = 'orange',
'NPD' = 'brown', 'SPD' = 'red', 'Tierschutzpartei' = 'darkblue')
ggplot(data = wahl_2013, aes(x = nMonat, y = Prozent, group = Partei)) +
geom_line(aes(colour = Partei)) + # Liniendiagramm
xlab('Zeitraum') + # Beschriftung x-Achse
ylab('Anfragen (in % des Maximums)') + # Beschriftung y-Achse
ggtitle('Suchanfragen') + # Überschrift
scale_color_manual(values = farben)
Herzlichen Glückwunsch! Wenn du es bis hierhin geschafft hast, hast du erfolgreich das Projekt zu den Google Trends abgeschlossen (oder einfach sehr viel Text und R-Code gelesen). Falls dieses Projekt dir Lust nach mehr Projekten gemacht hat, kannst du dich unter dem Reiter Projekte auf pandaR weiter austoben.