](/media/header/splattered_paint.jpg)
Einleitung
Das Paket ggplot2 ist das umfangreichste und am weitesten verbreitete Paket zur Grafikerstellung in R. Seine Beliebtheit liegt vor allem an zwei Dingen: Es ist sehr eng mit der kommerziellen Seite von RStudio verwoben (Autor ist auch hier Hadley Wickham) und es folgt stringent einer “Grammatik der Grafikerstellung”. Aus dem zweiten Punkt leitet sich auch sein Name ab: das “gg” steht für “Grammar of Graphics” und geht auf das gleichnamige Buch von Leland Wilkinson zurück, in dem auf 700 kurzen Seiten eine grammatikalische Grundstruktur für das Erstellen von Grafiken zur Datendarstellung hergeleitet und detailliert erklärt wird.
Weil ggplot2 so beliebt ist, gibt es online tausende von Quellen mit Tutorials, Beispielen und innovativen Ansätzen zur Datenvisualisierung. Vom Autor des Pakets selbst gibt es ein Überblickswerk über Data-Science als e-Book, in dem sich auch ein Kapitel mit ggplot2 befasst. Wie wir noch besprechen werden ist es Teil des tidyverse und somit direkt in eine Umgebung aus verschiedenen Paketen für Datenmanagement und -darstellung integriert.
Beispieldaten
Wir benutzen für unsere Interaktion mit ggplot2 öffentlich zugängliche Daten aus verschiedenen Quellen, die dankenswerterweise von Gapminder zusammengetragen werden. Für diesen Abschnitt gucken wir uns dafür mal an, wie viel verschiedene Länder in die Bildung investieren - diese Daten stammen ursprünglich von der Weltbank.
Alle, die daran interessiert sind, wie diese Daten von Gapminder bezogen und für die Weitervewendung aufbereitet werden, können das Ganze im Beitrag zur Datenaufbereitung noch genauer nachlesen. Für alle, die das überspringen und endlich Bilder machen wollen, gibt es auch schon den <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:currentColor;overflow:visible;position:relative;"><path d="M288 32c0-17.7-14.3-32-32-32s-32 14.3-32 32V274.7l-73.4-73.4c-12.5-12.5-32.8-12.5-45.3 0s-12.5 32.8 0 45.3l128 128c12.5 12.5 32.8 12.5 45.3 0l128-128c12.5-12.5 12.5-32.8 0-45.3s-32.8-12.5-45.3 0L288 274.7V32zM64 352c-35.3 0-64 28.7-64 64v32c0 35.3 28.7 64 64 64H448c35.3 0 64-28.7 64-64V416c0-35.3-28.7-64-64-64H346.5l-45.3 45.3c-25 25-65.5 25-90.5 0L165.5 352H64zm368 56a24 24 0 1 1 0 48 24 24 0 1 1 0-48z"/></svg>{=html} fertigen Datesatz zum Download. Auch den kann man aber direkt in R laden, ohne erst die Datei herunterladen und speichern zu müssen:
load(url('https://pandar.netlify.com/post/edu_exp.rda'))
Eine kurze Erläuterung der Variablenbedeutungen:
geo: Länderkürzel, das zur Identifikation der Länder über verschiedene Datenquellen hinweg genutzt wirdCountry: der Ländername im EnglischenWealth: Wohlstandseinschätzung des Landes, unterteilt in fünf GruppenRegion: Einteilung der Länder in die vier groben Regionenafrica,americas,asiaundeuropeYear: JahreszahlPopulation: BevölkerungExpectancy: Lebenserwartung eines Neugeborenen, sollten die Lebensumstände stabil bleiben.Income: Stetiger Wohlstandsindikator für das Land (GDP pro Person)Primary: Staatliche Ausgaben pro Schüler*in in der primären Bildung als Prozent desincome(GDP pro Person)Secondary: Staatliche Ausgaben pro Schüler*in in der sekundären Bildung als Prozent desincome(GDP pro Person)Tertiary: Staatliche Ausgaben pro Schüler*in oder Student*in in der tertiären Bildung als Prozent desincome(GDP pro Person)Index: Education Index des United Nations Development Programme
Eine Ausprägung von 100 auf der Variable primary in Deutschland hieße also zum Beispiel, dass pro Schüler*in in der Grundschule das Äquivalent der Wirtschaftsleistung einer bzw. eines Deutschen ausgegeben würde. 50 hieße entsprechend, dass es die Hälfte dieser Wirtschaftsleistung in diese spezifische Schulausbildung investiert wird.
Der Datensatz mit dem wir arbeiten sieht also so aus:
head(edu_exp)
## geo Country Wealth Region Year Population Expectancy Income Primary Secondary Tertiary
## 1 afg Afghanistan low_income asia 1997 17788819 50.7 NA NA NA NA
## 2 afg Afghanistan low_income asia 1998 18493132 50.0 NA NA NA NA
## 3 afg Afghanistan low_income asia 1999 19262847 50.8 NA NA NA NA
## 4 afg Afghanistan low_income asia 2000 19542982 51.0 NA NA NA NA
## 5 afg Afghanistan low_income asia 2001 19688632 51.1 NA NA NA NA
## 6 afg Afghanistan low_income asia 2002 21000256 51.6 344.2242 NA NA NA
## Index
## 1 0.18
## 2 0.19
## 3 0.20
## 4 0.20
## 5 0.21
## 6 0.22
ggplot2 Grundprinzipien
In ggplot2 werden immer Daten aus einem data.frame dargestellt. Das heißt, dass wir nicht, wie bei plot oder hist aus R selbst Vektoren oder Matrizen nutzen können. Daten müssen immer so aufbereitet sein, dass der grundlegende Datensatz sinnvoll benannte Variablen enthält und in dem Format vorliegt, in dem wir die Daten visualisieren wollen. Das hat zwar den Nachteil, dass wir Datensätze umbauen müssen, wenn wir Dinge anders darstellen wollen, aber hat auch den Vorteil, dass wir alle Kenntnisse über Datenmanagement im Allgemeinen auf den Umgang mit ggplot2 übertragen können.
Bevor wir loslegen können, muss natürlich ggplot2 installiert sein und geladen werden:
library(ggplot2)
Im Kern bestehen Abbildungen in der Grammatik von ggplot2 immer aus drei Komponenten:
- Daten, die angezeigt werden sollen
- Geometrie, die vorgibt welche Arten von Grafiken (Säulendiagramme, Punktediagramme, usw.) genutzt werden
- Ästhetik, die vorgibt, wie die Geometrie und Daten aufbereitet werden (z.B. Farben)
In den folgenden Abschnitten werden wir versuchen, diese drei Komponenten so zu nutzen, dass wir informative und eventuell auch ansehnliche Abbildungen generieren.
Schichten
In ggplot2 werden Grafiken nicht auf einmal mit einem Befehl erstellt, sondern bestehen aus verschiedenen Schichten. Diese Schichten werden meistens mit unterschiedlichen Befehlen erzeugt und dann so übereinandergelegt, dass sich am Ende eine Abbildung ergibt.
Die Grundschicht sind die Daten. Dafür haben wir im vorherigen Abschnitt edu_exp als Datensatz aufbereitet. Benutzen wir zunächst nur die Daten für Spanien um nicht direkt tausende von Datenpunkten auf einmal zu sehen. Ich habe Spanien ausgesucht, weil es bezüglich der Bildungs- und Arbeitsmarktsituation für junge Personen ein Land mit vielen “interssanten Konstellationen” ist.
esp <- subset(edu_exp, geo == 'esp')
ggplot(esp)

Was entsteht ist eine leere Fläche. Wie bereits beschrieben, besteht eine Abbildung in ggplot2 immer aus den drei Komponenten Daten, Geometrie und Ästhetik. Bisher haben wir nur eine festgelegt. Als erste Ästhetik sollten wir festlegen, welche Variablen auf x- und y-Achse dargestellt werden sollen. Nehmen wir naheliegenderweise die Zeit (x-Achse) und die Ausgaben für Grundschulbildung:
ggplot(esp, aes(x = Year, y = Primary))
Ästhetik wird in ggplot2 über den aes-Befehl erzeugt. Jetzt fehlt uns noch die geometrische Form, mit der die Daten abgebildet werden sollen. Für die Geometrie-Komponente stehen in ggplot2 sehr viele Funktionen zur Verfügung, die allesamt mit geom_ beginnen. Eine Übersicht über die Möglichkeiten findet sich z.B. hier. Naheliegende Möglichkeiten für den Zeitverlauf sind eine Linie (geom_line) und mehrere Punkte (geom_point). Neue Schichten werden in ihrer eigenen Funktion erzeugt und mit dem einfachen + zu einem bestehenden Plot hinzugefügt. Für ein Liniendiagramm sieht das Ganze also einfach so aus:
ggplot(esp, aes(x = Year, y = Primary)) +
geom_line()
## Warning: Removed 3 rows containing missing values (`geom_line()`).

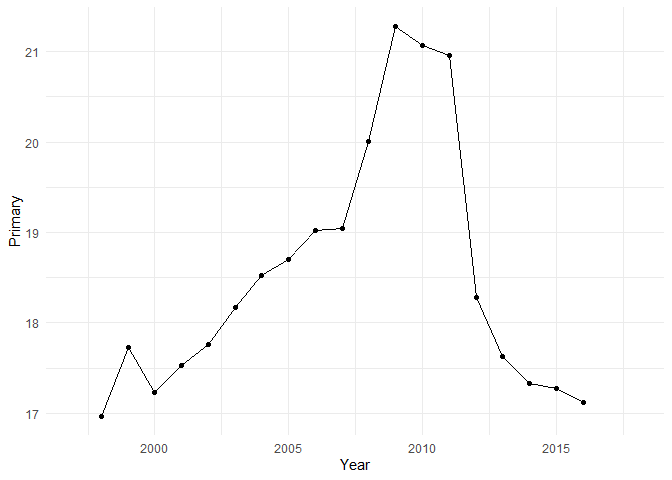
Der immense Vorteil des Schichtens besteht darin, dass wir gleichzeitig mehrere Visualisierungsformen nutzen können. Das Prinizp bleibt das gleiche wie vorher: wir fügen Schichten mit dem + hinzu. Wir können also Punkte und Linien direkt miteinander kombinieren:
ggplot(esp, aes(x = Year, y = Primary)) +
geom_line() +
geom_point()
## Warning: Removed 3 rows containing missing values (`geom_line()`).
## Warning: Removed 3 rows containing missing values (`geom_point()`).
Plots als Objekte
Einer der Vorteile, die sich durch das Schichten der Abbildungen ergibt ist, dass wir Teile der Abbildung als Objekte definieren können und sie in verschiedenen Varianten wieder benutzen können. Das hilft besonders dann, wenn wir unterschiedliche Geometrie in einer gemeinsamen Abbildung darstellen wollen oder z.B. erst einmal eine Abbildung definieren wollen, bevor wir Feinheiten adjustieren.
basic <- ggplot(esp, aes(x = Year, y = Primary))
In basic wird jetzt die Anleitung für die Erstellung der Grafik gespeichert. Erstellt wird die Grafik aber erst, wenn wir das Objekt aufrufen. Dabei können wir das Objekt auch mit beliebigen anderen Komponenten über + kombinieren:
basic + geom_point()
## Warning: Removed 3 rows containing missing values (`geom_point()`).
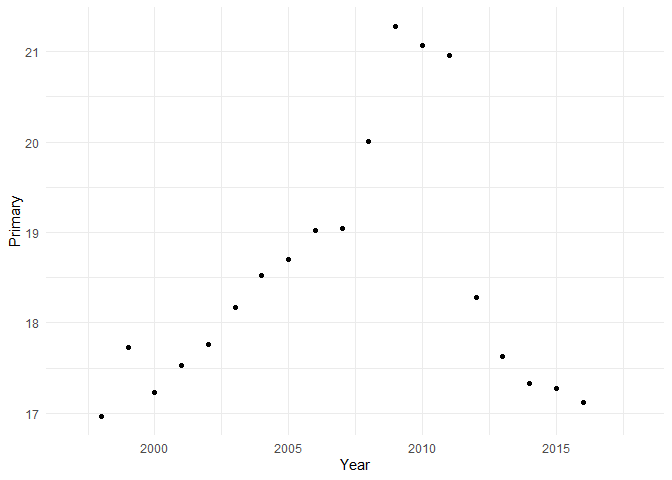
Damit die Beispiele im weiteren Verlauf auch selbstständig funktionieren, wird unten immer der gesamte Plot aufgeschrieben. Aber für eigene Übungen oder Notizen ist es durchaus praktischer mit dieser Objekt Funktionalität zu arbeiten, um so zu umgehen, dass man immer wieder die gleichen Abschnitte aufschreiben muss.
Farben und Ästhetik
Oben hatte ich schon erwähnt, dass Ästhetik die dritte Komponente ist und als Beispiel Farbe genannt. Das stimmt nicht immer: die Farbe der Darstellung muss nicht zwingend eine Ästhetik sein. Gucken wir uns zunächst an, wie es aussieht, wenn wir die Farbe der Darstellung ändern wollen:
ggplot(esp, aes(x = Year, y = Primary)) +
geom_point(color = 'blue')
## Warning: Removed 3 rows containing missing values (`geom_point()`).
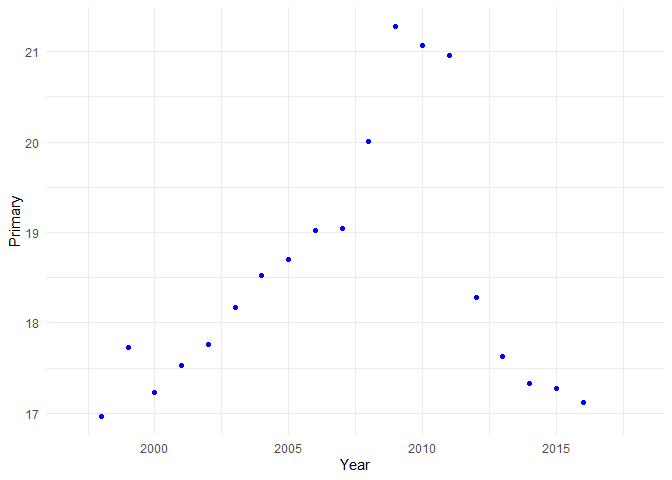
Alle Punkte haben die Farbe geändert. Eine Ästhetik im Sinne der ggplot-Grammatik ist aber immer abhängig von den Daten. Die globale Vergabe von Farbe ist also keine Ästhetik. Sie ist es nur, wenn wir sie von Ausprägungen der Daten abhängig machen. Das funktioniert z.B. so:
ggplot(esp, aes(x = Year, y = Primary)) +
geom_point(aes(color = Primary))
## Warning: Removed 3 rows containing missing values (`geom_point()`).

Über den Befehl aes definieren wir eine Ästhetik und sagen ggplot, dass die Farbe der Punkte von der Ausprägung auf der Variable Primary abhängen soll. Die Farbe kann aber natürlich auch von jeder anderen Variable im Datensatz abhängen. Wie das aussehen kann gucken wir uns im kommenden Abschnitt an.
Gruppierte Abbildungen
Im letzten Abschnitt hatten wir die Daten auf Spanien reduziert. In diesem Abschnitt wollen wir gleichzeitig mehrere Länder betrachten können. Dafür müssen wir wieder zunächst die Daten auswählen, die relevant sind. Wir beschränken uns in diesem Fall auf die fünf bevölkerungsreichsten Länder Europas, für die ausreichend viele Datenpunkte vorliegen: das Vereinigte Königreich, Frankreich, Italien, Spanien und Polen.
sel <- subset(edu_exp, geo %in% c('gbr', 'fra', 'ita', 'esp', 'pol'))
Wenn wir jetzt mit dem gleichen Vorgehen wie oben die Abbildung erstellen, wird es etwas chaotischer, weil unklar ist, welche Punkte sich auf welches Land beziehen:
ggplot(sel, aes(x = Year, y = Primary)) +
geom_point()
## Warning: Removed 23 rows containing missing values (`geom_point()`).

Um das zu umgehen, können wir natürlich die Ästhetik der Farben benutzen:
ggplot(sel, aes(x = Year, y = Primary)) +
geom_point(aes(color = Country))
## Warning: Removed 23 rows containing missing values (`geom_point()`).
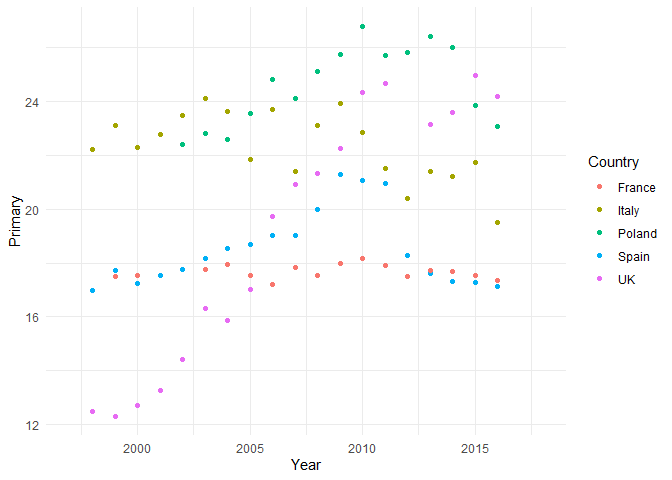
Wie Sie sehen ergibt sich automatisch eine Legende auf der rechten Seite, die jedem Land eine Farbe zuweist. Wir können auch hier wieder eine Kombination aus Punkten und Linien nutzen:
ggplot(sel, aes(x = Year, y = Primary)) +
geom_point(aes(color = Country)) +
geom_line(aes(color = Country))
## Warning: Removed 23 rows containing missing values (`geom_point()`).
## Warning: Removed 20 rows containing missing values (`geom_line()`).

Das Problem ist hier, dass wir die Ästhetik für jede Geomtrie wiederholen müssen. Stattdessen können wir in ggplot auch allgemein eine Gruppierung vornehmen, die für alle Geometrien übernommen wird:
ggplot(sel, aes(x = Year, y = Primary, color = Country)) +
geom_point() + geom_line()
Mehrere Variablen
Bisher haben wir auf der x-Achse nur die Zeit und auf der y-Achse nur die Ausgaben für die Grundschulbildung betrachtet. Durch das Schicht-System können wir auf unsere bisherigen Abbildungen aber auch zusätzliche Variablen - oder sogar komplett andere Datensätze - abbilden. Wenn wir uns z.B. gleichzeitig die Ausgaben für Primäre, Sekundäre und Tertiäre Bildung in Spanien angucken wollen, können wir wie folgt vorgehen:
ggplot(esp, aes(x = Year)) +
geom_line(aes(y = Primary), color = 'red') +
geom_line(aes(y = Secondary), color = 'green') +
geom_line(aes(y = Tertiary), color = 'blue')
## Warning: Removed 3 rows containing missing values (`geom_line()`).
## Removed 3 rows containing missing values (`geom_line()`).
## Removed 3 rows containing missing values (`geom_line()`).

Achtung: Wenn mehrere Variablen im gleichen Diagramm abgebildet werden, sollten Sie einen sinnvollen Achsentitel wählen. Hier wird per Voreinstellung der Name der ersten Variable für die Beschriftung der y-Achse gewählt. Weiter unten wird erklärt, wie die Achsenbeschriftung geändert werden kann.
Diese Vorgehensweise ist zwar möglich aber nicht wirklich im Sinne des Erfinders. Eigentlich will ggplot2 von uns, dass wir solche Untscheidungen über Gruppierung der Daten erzeugen. Dafür müssten wir unsere Daten ins long-Format übertragen, sodass wir statt dieser “breiten” Struktur:
| geo | Year | Primary | Secondary | Tertiary |
|---|---|---|---|---|
| esp | 1998 | 16.97009 | 23.87749 | 19.62106 |
| esp | 1999 | 17.73268 | 24.05752 | 19.38165 |
| … | … | … | … | … |
diese “lange” Struktur erhalten:
| geo | Year | Type | Expense |
|---|---|---|---|
| esp | 1998 | Primary | 16.97009 |
| esp | 1998 | Secondary | 23.87749 |
| esp | 1998 | Tertiary | 19.62106 |
| esp | 1999 | Primary | 17.73268 |
| esp | 1999 | Secondary | 24.05752 |
| esp | 1999 | Tertiary | 19.38165 |
| … | … | … | … |
In diesem Format angekommen, haben wir dann wieder die Möglichkeit mit Gruppierungen anhand der neuen Type Variable so zu verfahren, wie wir es oben schon gesehen haben. Um eine solche Umstellung vorzunehmen, können wir den reshape Befehl nutzen:
sel_long <- reshape(sel, direction = 'long',
varying = c('Primary', 'Secondary', 'Tertiary'),
v.names = 'Expense',
timevar = 'Type',
times = c('Primary', 'Secondary', 'Tertiary'))
Der entstandene Datensatz hat jetzt das von ggplot2 so geliebte lange Datenformat:
head(sel_long)
## geo Country Wealth Region Year Population Expectancy Income Index Type Expense
## 1.Primary esp Spain high_income europe 1997 40180050 78.7 21117.02 0.68 Primary NA
## 2.Primary esp Spain high_income europe 1998 40362357 79.0 21953.67 0.69 Primary 16.97009
## 3.Primary esp Spain high_income europe 1999 40542232 79.1 22846.72 0.69 Primary 17.73268
## 4.Primary esp Spain high_income europe 2000 40741651 79.3 23937.97 0.70 Primary 17.22694
## 5.Primary esp Spain high_income europe 2001 40966450 79.5 24707.37 0.71 Primary 17.52693
## 6.Primary esp Spain high_income europe 2002 41477655 79.6 25026.09 0.72 Primary 17.76286
## id
## 1.Primary 1
## 2.Primary 2
## 3.Primary 3
## 4.Primary 4
## 5.Primary 5
## 6.Primary 6
Damit können wir jetzt die drei verschiedenen Variablen als gruppierte Beobachtungen darstellen und das gleiche Schema wie schon oben benutzen. Dafür wählen wir aber Spanien aus unserem Langen Datensatz aus und geben nur diese Daten mit der Pipe |> an ggplot weiter:
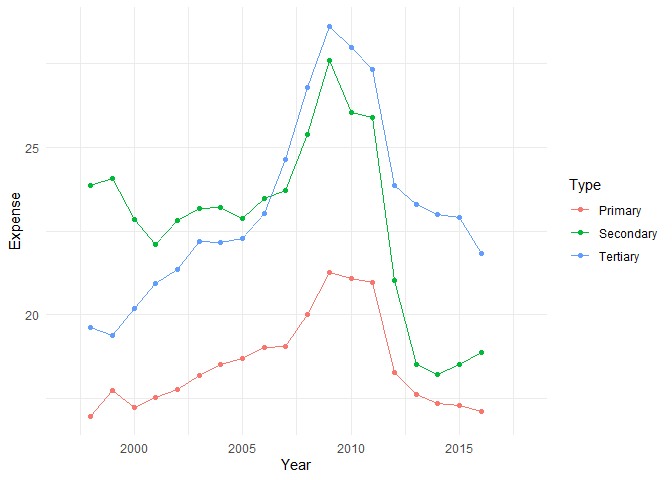
subset(sel_long, geo == 'esp') |>
ggplot(aes(x = Year, y = Expense, color = Type)) +
geom_line() + geom_point()
## Warning: Removed 9 rows containing missing values (`geom_line()`).
## Warning: Removed 9 rows containing missing values (`geom_point()`).
Faceting
Wenn wir die Kombination aus allen Bildungsniveaus und unseren fünf Ländern in der gleichen Abbildung darstellen wollen, könnte das ein wenig unübersichtlich werden. Eine Möglichkeit, Übersichtlichkeit zu bewahren ist das sogenannte Faceting. Dabei wird eine Abbildung anhand von Ausprägungen auf einer oder mehr Variablen in verschiedene Abbildungen unterteilt. Für unseren Fall können wir uns in einer Abbildung z.B. eine Facet für jedes Bildungsniveau anzeigen lassen:
ggplot(sel_long, aes(x = Year, y = Expense, color = Country)) +
geom_point() + geom_line() +
facet_wrap(~ Type)
## Warning: Removed 65 rows containing missing values (`geom_point()`).
## Warning: Removed 20 rows containing missing values (`geom_line()`).
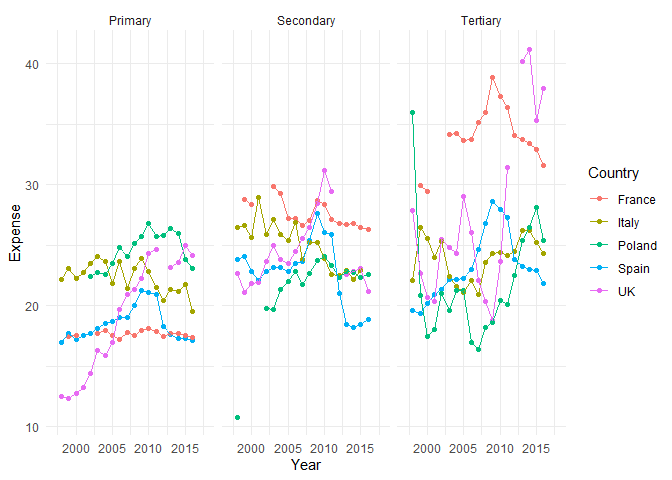
In facet_wrap wird mit der R Gleichungsnotation gearbeitet: hier wird der Plot anhand der unabhängigen Variablen hinter der Tilde in Gruppen eingeteilt. Das gibt auch wieder die Möglichkeit mit + mehrere Variablen zu definieren, die zum Faceting benutzt werden sollen. Wenn wir Gruppen anhand von zwei Variablen bilden bietet es sich außerdem an facet_grid zu benutzen. Ein solcher Grid wäre z.B. die gleichzeitige Einteilung nach Typ und Land:
ggplot(sel_long, aes(x = Year, y = Expense, color = Country)) +
geom_point() + geom_line() +
facet_grid(Type ~ Country)
## Warning: Removed 65 rows containing missing values (`geom_point()`).
## Warning: Removed 20 rows containing missing values (`geom_line()`).
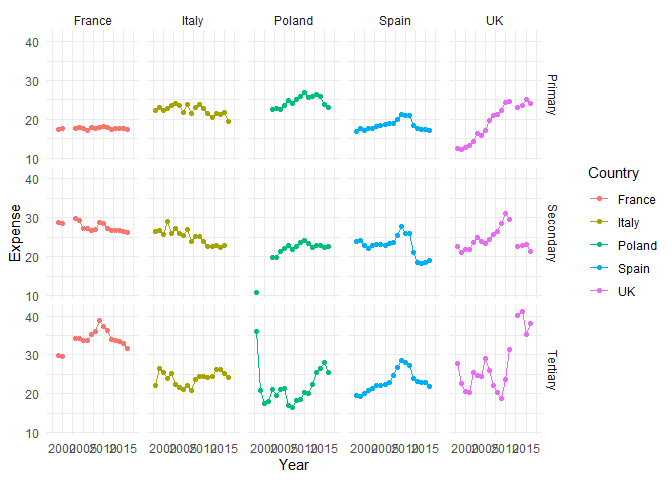
Hier unterteilt die Variable vor der Tilde die Facets in Zeilen, die Variable nach der Tilde in Spalten. Per Voreinstellung wird beim Faceting eine gemeinsame Skalierung der x- und y-Achsen für alle Teilabbildungen festgelegt. Das kann mit dem Argument scales in der facet_wrap Funktion umgangen werden:
ggplot(sel_long, aes(x = Year, y = Expense, color = Country)) +
geom_point() + geom_line() +
facet_grid(Type ~ Country, scales = 'free')
## Warning: Removed 65 rows containing missing values (`geom_point()`).
## Warning: Removed 20 rows containing missing values (`geom_line()`).

Während das zwar schöner aussieht sei aber dazu gesagt, dass wir hier die Interpretierbarkeit der Grafik dahingehend einschränken, dass Abbildungen in unterschiedlichen Zeilen nicht mehr direkt miteinander verglichen werden können.
Damit haben wir alle grundlegenden Funktionalitäten von ggplot2 am Beispiel eines Punkte bzw. Liniendiagramms besprochen. Leider würden so alle Abbildungen immer gleich aussehen, weswegen wir im Abschnitt zum Anpassen von Abbildungen genau besprechen werden, wie man ggplots nach eigenem Geschmack gestalten kann. Wer sich auch gerne mal die Erstellung von Balkendiagrammen, Boxplots, Violinplots oder sogar… Tortendiagrammen ansehen will wird im Abschnitt zur anderen Plot-Typen fündig.