](/media/header/colouring_pencils_smoke.jpg)
Die Abbildungen, die wir im ersten Abschnitt erstellt haben, nutzen alle das in ggplot2 voreingestellte Design. Auch wenn es sicherlich einen theoretisch sehr gut fundierten Grund gibt, dass der Hintergrund der Abbildung in einem demotivierenden Grauton gehalten sein sollte, gibt es Designs, die man schöner finden kann. Im folgenden sehen wir uns an, wie man seine Abbildungen nach seinen eigenen Vorlieben anpasst.
Dazu benutzen wir wieder den aus Gapminder zusammengeführten Datensatz (mehr Details dazu im Beitrag zur Datenerstellung):
load(url('https://pandar.netlify.com/post/edu_exp.rda'))
Außerdem müssen wir zur Vorbereitung natürlich wieder ggplot2 laden:
library(ggplot2)
Nehmen wir einen einfachen Scatterplot, in dem wir den Zusammenhang zwischen Ausgaben für die Grundschulbildung (Primary) und dem tatsächlich erreichten Education Index (Index) darstellen. Dafür betrachten wir erst einmal nur die Daten aus 2013 (das Jahr mit den meisten zuverlässigen Angaben im Datensatz) und gruppieren die Länderergebnisse direkt nach ihrer Wirtschaftsleistung (Income):
edu_2013 <- subset(edu_exp, Year == 2013)
ggplot(edu_2013, aes(x = Primary, y = Index, color = Wealth)) +
geom_point()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
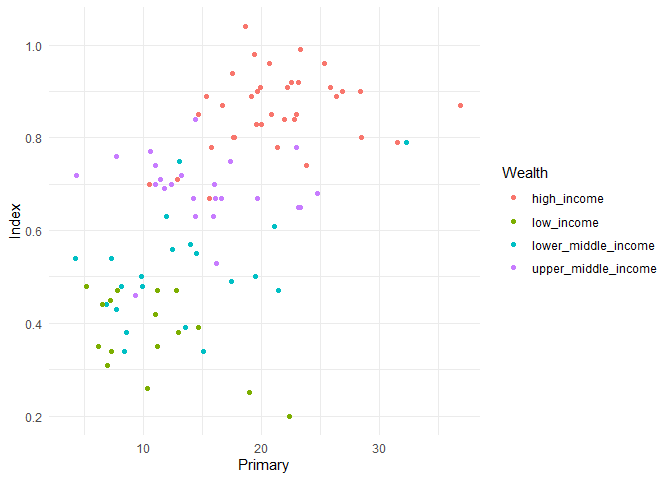
Das Ergebnis können wir in Dingen Ansehnlichkeit mal als “funktionabel” bezeichnen, aber es gibt Einiges, was hier verbessert werden kann, bzw. muss. Zum Glück ist genau dafür dieser Beitrag da.
Legende
Das erste offensichtliche Manko der Abbildung ist die Legende, die die Kategorisierung für “Wealth” erzeugt. Diese entsteht automatisch aus den einzigartigen Ausprägungen unserer Gruppierungsvariable:
unique(edu_2013$Wealth)
## [1] "low_income" "lower_middle_income" "upper_middle_income" "high_income"
Es gibt zwar fünf einzigartige Ausprägungen, aber eine davon ist leer. Außerdem können wir sehen, dass es sich bei dieser Variable um einen character-Vektor handelt, nicht um einen factor wie für nominal-skalierte Gruppenvariablen üblich. Das hat zur Folge, dass ggplot die Ausprägungen automatisch alphabetisch sortiert. Wie schon in der ggplot Einführung besprochen ist der Kerngedanke bei solchen Problemen, dass wir jetzt nicht an der Grafik herumbasteln, sondern stattdessen die zugrundeliegenden Daten so anpassen, dass sie am Ende eine adäquate Abbildung ermöglichen. Das heißt für uns, dass wir die Variable “Wealth” so umwandeln sollten, dass sie am Ende ordentlich sortierte und angemessen benannte Ausprägungen enthält.
edu_2013$Wealth <- factor(edu_2013$Wealth,
levels = c('high_income', 'upper_middle_income', 'lower_middle_income', 'low_income'),
labels = c('High', 'Upper Mid.', 'Lower Mid.', 'Low'))
Die Unwandlung in einen Faktor hat verschiedene Vorteile:
- Durch die Reihenfolge der
levelslegen wir die Sortierung der Ausprägungen fest.high_incomeist die Höchste,low_incomedie Niedrigste. - Alle Ausprägungen, die wir nicht explizit erwähnen, werden als fehlende Werte
NAkodiert. - Über
labelskönnen wir verständlichere Beschriftungen der Ausprägungen erzeugen.
Die neue Abbildung sieht jetzt folgendermaßen aus:
ggplot(edu_2013, aes(x = Primary, y = Index, color = Wealth)) +
geom_point()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
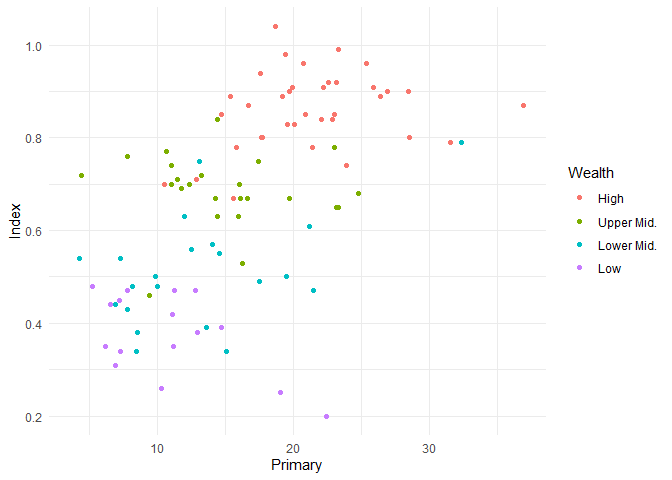
Dieses Vorgehen - Daten anpassen bzw. Umstrukturieren - sollten wir in der Logik, die ggplot leitet, immer post-hoc Anpassungen der Abbildungen vorziehen. Fehlende Werte erhalten per Voreinstellung immer eine gesonderte Farbe (meistens grau) zugewiesen, um zu verdeutlichen, dass dies nicht andere Informationen zum Rest sind, sondern eben keine. Wenn wir solche Fälle ausschließen wollen, können wir natürlich wieder mit subset arbeiten und den reduzierten Datensatz an ggplot weitergeben:
subset(edu_2013, !is.na(Wealth)) |>
ggplot(aes(x = Primary, y = Index, color = Wealth)) +
geom_point()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
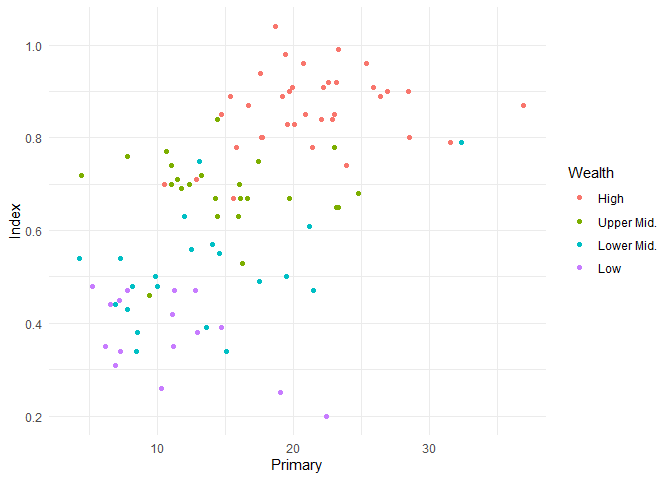
Beschriftung
Eine der wichtigsten Komponenten jeder Abbildung ist die Beschriftung. Nur wenn ausreichend gut gekennzeichnet ist, was wir darstellen, können wir darauf hoffen, dass die Information vermittelt wird, die wir vermitteln wollen. Zunächst ist es sinnvoll, die Achsen ordentlich zu beschriften. Per Voreinstellung werden hierzu die Namen der Variablen genutzt. Wir können also eine nützliche Beschriftung auch wieder dadurch erzwingen, dass wir die Variablen im Datensatz ordentlich benennen. Besonders wenn die Achsen aber Zusatzinformationen (wie z.B. “(in %)”) enthalten sollen, ist es aber unumgänglich die Benennung hinterher zu ergänzen. Darüber hinaus kann es sinnvoll sein, einer Grafik Titel und Untertitel zu geben.
Für unsere Abbildung wäre es sinnvoll, neben einem Titel auch eine aussagekräftigere Beschriftung der Achsen und der Legende vorzunehmen. Damit wir unsere Grafik in späteren Abschnitten wiederverwenden können, legen wir sie außerdem hier wieder erst in einem Objekt ab, anstatt sie direkt ausgeben zu lassen:
scatter <- ggplot(edu_2013, aes(x = Primary, y = Index, color = Wealth)) +
geom_point() +
labs(x = 'Spending on Primary Eduction',
y = 'UNDP Education Index',
color = 'Country Wealth\n(GDP per Capita)') +
ggtitle('Impact of Primary Education Investments', '(Data for 2013)')
scatter
## Warning: Removed 99 rows containing missing values (`geom_point()`).
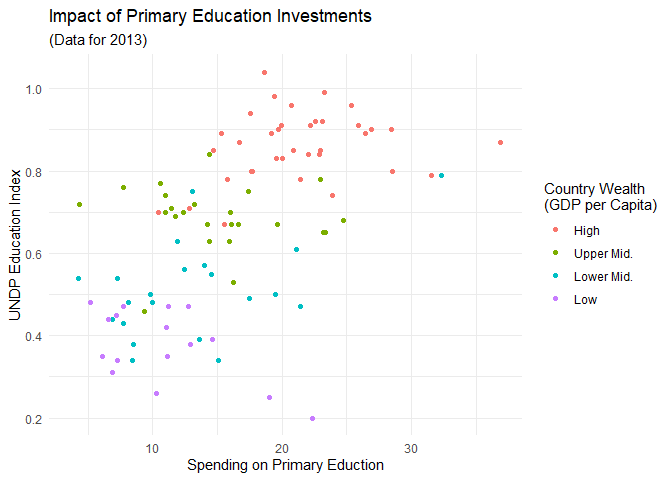
Die labs Funktion ermöglicht uns das Vergeben von Labels für die Variablen, die wir als Ästhetiken in aes() festgehalten haben. x ersetzt also den Variablennamen von Primary, der per Voreinstellung zur Beschriftung herangezogen wird. Das Gleiche gilt dann auch für y und color ersetzt den Titel der Legende. Um diesen Titel ein wenig hübscher zu gestalten, habe ich hier einen Zeilenumbruch mit \n eingefügt. Die ggtitle-Funktion nimmt zwei Argumente entgegen: den Titel und einen Untertitel.
Vorgefertigte Themes
In ggplot2 werden die Grundeigenschaften von Abbildungen in “Themes” zusammengefasst. Mit ?theme_test erhält man eine Auflistung aller Themes, die von ggplot2 direkt zur Verfügung gestellt werden. Diese 10 Themes sind erst einmal sehr konservative Einstellungen für die Eigenschaften von Grafiken. Sehen wir uns meinen persönlichen Favoriten, das sehr dezente theme_minimal() an:
scatter + theme_minimal()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
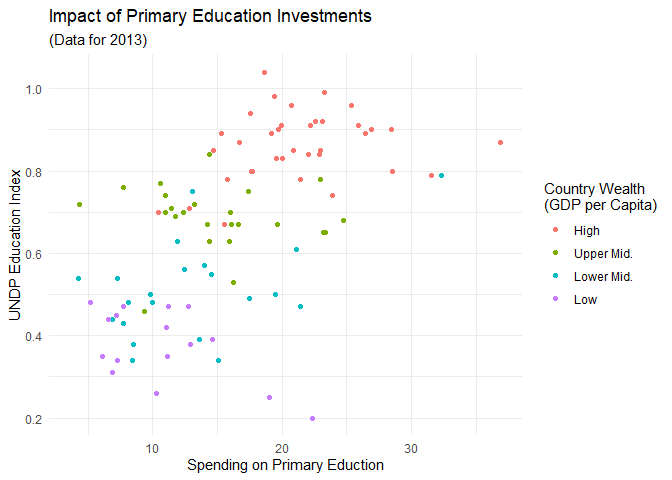
theme_grey) verändert sich hier, dass der Hintergrund jetzt nicht mehr grau ist und das Raster stattdessen in Hellgrau gehalten ist. An diesem Punkt wird erneut der Vorteil des Schichtsystems von ggplot deutlich: wir definieren Daten, Ästhetik und Geometrie und können dann optische Anpassungen über das Theme vornehmen, die von den diesen drei Komponenten unabhängig verändert werden können. Diese Art und Weise, wie von ggplot Abbildungen definiert werden, hat den Vorteil, dass alles was wir hier besprechen auch auf jeden anderen Abbildungstyp anwendbar ist (eine größere Auswahl verschiedener Plots haben wir im ggplotpourri zusammengestellt), weil wir einfach die geom_ Funktionen austauschen können. Die Eigenschaften der Abbildung hinsichtlich des Aussehens von Hintergrund usw. bleiben davon aber unberührt.
Über die von ggplot2 direkt mitgelieferten Themes hinaus gibt es beinahe unzählige weitere Pakete, in denen vordefinierte Themes enthalten sind. Eine beliebtesten Sammlungen findet sich im Paket ggthemes:
install.packages('ggthemes')
library(ggthemes)
Dieses Paket liefert (neben anderen optischen Erweiterungen) über 20 neue Themes, die häufig den Visualisierungen in kommerzieller Software oder in bestimmten Publikationen nachempfunden sind. In Anlehnung an den Theorieteil nutzen wir als allererstes natürlich das nach Tuftes “maximal Data, minimal Ink” Prinzip erstellte Theme:
scatter + theme_tufte()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
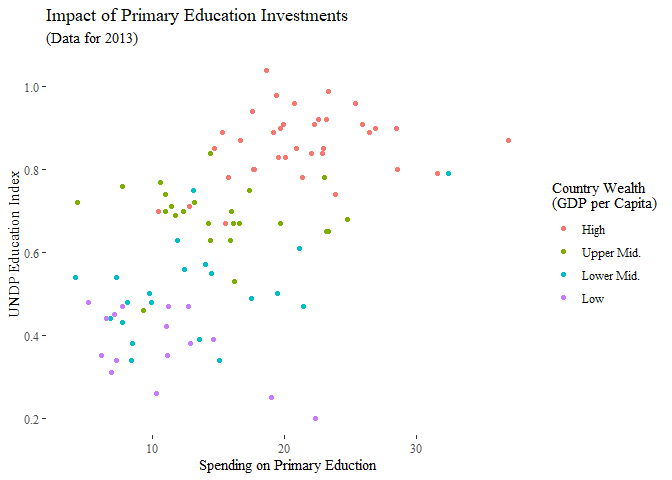
Aber es gibt natürlich auch etwas komplexer aussehende Themes, wie diesen Nachbau der Grundprinzipien von Abbildungen auf Nate Silvers Website fivethirtyeight:
scatter + theme_fivethirtyeight()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
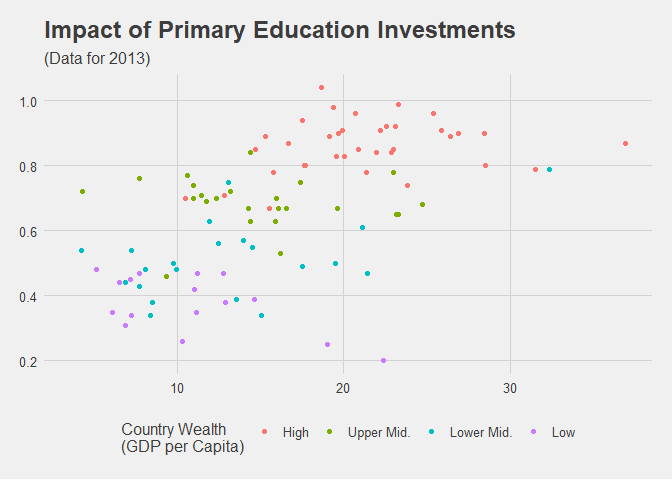
Die allermeisten Theme-Sammlungen und ggplot-Ergänzungs-Pakete werden nicht über CRAN vertrieben, sondern sind nur direkt über die GitHub-Repositorien ihrer Ersteller nutzbar. Das kann mitunter an Copyright-Problemen liegen (für CRAN-Pakete darf kein Inhalt genutzt werden, der unter Copyright steht) oder daran, dass es sich einfach um Spielereien handelt. Wer dennoch in den Genuss dieser Themes kommen möchte, benötigt das devtools Paket (ein Überblick und Installationshinweise finden sich hier). Dieses Paket liefert dann den install_github-Befehl, mit dem Pakete direkt aus den Repositorien installiert werden können. Ein paar Empfehlungen für den alltäglichen Gebrauch:
| Paket | Repository | Beschreibung |
|---|---|---|
ggtech | ricardo-bion/ggtech | Sammlung kommerzieller Themes (z.B. Google, Facebook, etsy, usw.) |
tvthemes | Ryo-N7/tvthemes | Sammlung von Themes, die an diverse Fernsehserien angelehnt sind (auch über CRAN verfügbar) |
bbplot | bbc/bbplot | Offizielles Theme der BBC |
xkcd | Nur über CRAN verfügbar | Plots im Stil der XKCD Comics |
Ein Paket, das hier noch besondere Erwähnung finden soll, ist ggthemr, dass bislang ebenfalls nur über ein GitHub-Repositorium installiert werden kann. Dieses Paket liefert neben vorgefertigten Themes auch diverse “convenience functions”, um die Personalisierung und Anwednung von Themes zu vereinfachen. Wie wir gleich sehen werden, kann da ein bisschen Abkürzung nicht schaden.
Wenn uns ein Theme so gefällt, dass wir dieses für alle Plots benutzen wollen, können wir es mit theme_set() als neue Voreinstellung definieren. Wie gesagt, mag ich den minimalistischen Stil von theme_minimal(), weil er wenig von den Daten ablenkt:
theme_set(theme_minimal())
Dieser Befehl sollte allerdings mit Vorsicht genossen werden, weil er globale Einstellungen in R verändert ohne davor zu warnen, dass eventuell vorherige Einstellungen verloren gehen. Zur Sicherheit können wir mit
theme_set(theme_grey())
jederzeit zurück in die ursprünglichen Voreinstellungen.
Elemente Anpassen
Themes definieren eine vielzahl von Eigenschaften, die aber natürlich auch alle manuell verändert werden können. Dazu gibt es in ggplot2 die theme() Funktion, die unglaublich viele Argumente entgegennimmt (eine vollständige Übersicht lässt sich mit ?theme aufrufen oder findet sich online im Reference-Sheet des Tidyverse).
Etwas, dass mir an diesem Plot misfällt ist die linksbündige Ausrichtung und kleine Schriftgröße des Titels. Um diese anzupassen muss ich zunächst das korrekte Argument für theme identifizieren. Die Hilfe (?theme) verrät, dass es ein Argument plot.title gibt, das Ergebnisse einer Funktion namens element_text() entgegen nimmt. Generell folgt die Anpassung von Theme-Elementen der Struktur: theme(element.name = element_function(...)) wobei wir in ... unsere Anpassungen vornehmen können. Im wesentlichen gibt es vier solcher Elemente-Funktionen:
| Funktion | Bezug |
|---|---|
element_text() | Elemente, die Schrift enthalten, z.B. Titel und Labels |
element_line() | Linien, z.B. die x-Achse |
element_rect() | Rechtecke, z.B. der Plot-Hintergrund (in der Voreinstellung grau) |
element_blank() | Nichts. Kann genutzt werden, um Dinge zu entfernen |
Natürlich gibt es eine Ausnahme zu dieser generellen Regel: unit() kann genutzt werden, um Dinge wie die Abstände der Markierungen auf den Achsen zu verändern. Um den Titel anzupassen, müssen wir an element_text() unsere gewünschten Optionen übermitteln. Die Argmumente, die wir benutzen können, sind relativ überischtlich:
args(element_text)
## function (family = NULL, face = NULL, colour = NULL, size = NULL,
## hjust = NULL, vjust = NULL, angle = NULL, lineheight = NULL,
## color = NULL, margin = NULL, debug = NULL, inherit.blank = FALSE)
## NULL
Für uns sind hier also size zur Anpassung der Schriftgröße und hjust zur Anpassung der horizontalen Ausrichtung von Relevanz. size nimmt Schriftgrößen im gewohnten Punkte-System entgegen, hjust die relative Position zwischen 0 (ganz links) und 1 (ganz rechts).
scatter +
theme(plot.title = element_text(size = 18, hjust = .5))
## Warning: Removed 99 rows containing missing values (`geom_point()`).
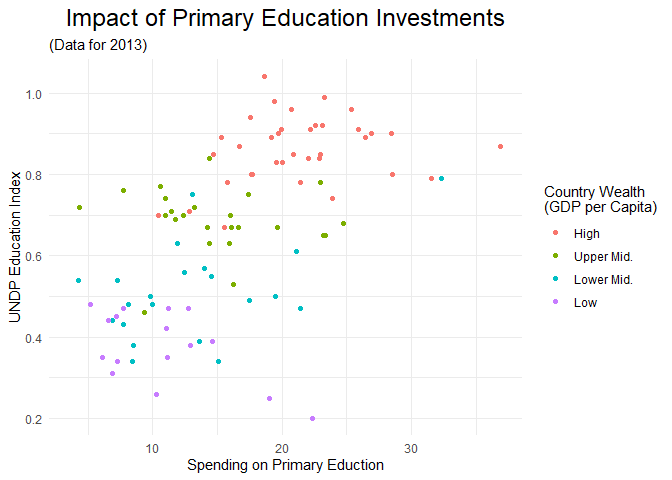
Das hat leider nur die Eigenschaften des Titels, nicht aber die des Untertitels verändert. ?theme verrät aber relativ schnell, dass wir dafür das Argument plot.subtitle brauchen:
scatter +
theme(plot.title = element_text(size = 18, hjust = .5),
plot.subtitle = element_text(hjust = .5))
## Warning: Removed 99 rows containing missing values (`geom_point()`).
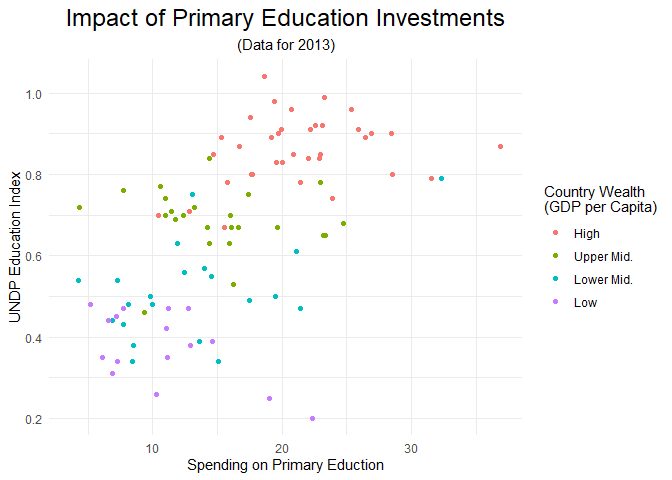
Auf diese Art und Weise können wir extrem detailliert beliebige Eigenschaften unserer Abbildungen ändern. Zum Beispiel können wir uns die x- und y-Achse noch als deutliche Linien einzeichnen lassen:
scatter +
theme(plot.title = element_text(size = 18, hjust = .5),
plot.subtitle = element_text(hjust = .5),
axis.line = element_line(color = 'black'))
## Warning: Removed 99 rows containing missing values (`geom_point()`).
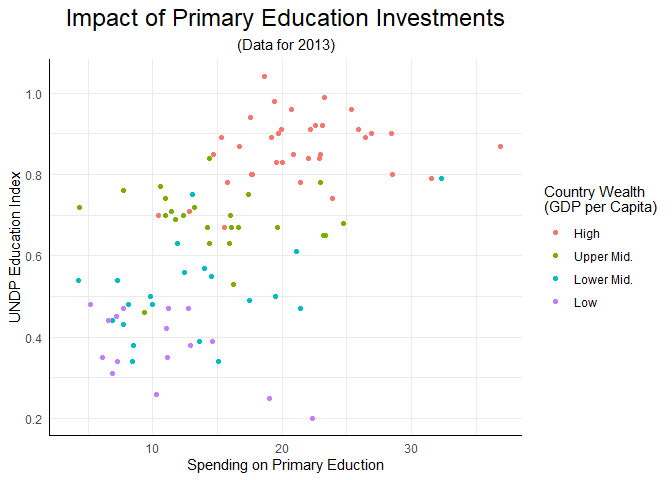
Eigene Themes
Anstatt diese Anpassungen bei jedem Plot händisch vorzunehmen, macht es Sinn, unsere Vorlieben auch irgendwie festzuhalten. Wir hatten schon gesehen, dass man mit theme_set() die Eigenschaften global festlegen kann. An dieser festgelegten Theme können wir “Updates” vornehmen, mit der vortrefflich benannten theme_update() Funktion:
theme_update(plot.title = element_text(size = 18, hjust = .5),
plot.subtitle = element_text(hjust = .5),
axis.line = element_line(color = 'black'))
So können wir uns jetzt bei allen Plots diese Anpassungen ersparen:
scatter
## Warning: Removed 99 rows containing missing values (`geom_point()`).
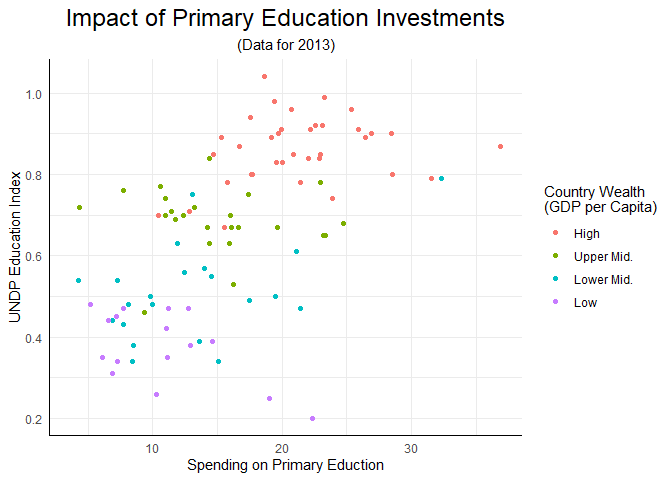
Die aktuell eingestellten Eigenschaften des Themes können wir mit theme_get() abrufen - aber Vorsicht, die Ausgabe kann etwas unübersichtlich und überwältigend wirken!
Um unsere Einstellungen wiederverwendbar zu machen und nicht immer nur für die aktuelle R-Sitzung festzulegen, können wir auch ein eigenes Theme erstellen. Dazu hilft es, sich vor Augen zu führen, dass auch die vorgefertigen Themes nur Funktionen sind, die die Argumente in theme() auf bestimmte Werte einstellen. Das heißt, wir könnten eine Funktion definieren, die für jedes dieser Argumente Werte angibt. Glücklicherweise können wir uns aber auch hier den Schreibaufwand abkürzen, indem wir eines der schon fertigen Themes nehmen und unsere spezifischen Anpassungen darauf anwenden:
theme_pandar <- function() {
theme_minimal() %+replace%
theme(plot.title = element_text(size = 18, hjust = .5),
plot.subtitle = element_text(hjust = .5),
axis.line = element_line(color = 'black'))
}
Hier ist der ggplot-interne %+replace% Befehl der Clou, der diese Anwendung von der oben dargestellten Anpassung einer Theme für einen konkreten Plot unterscheidet, weil dadurch nicht hinterher weitere Anpassungen vorgenommen werden, sondern stattdessen die Eigenschaften im Theme direkt ersetzt werden. Wenn wir uns jetzt mit theme_pandar() die gesamte Theme aufrufen, sehen wir - wie vorhin bei theme_get() die gesamten Einstellungen, die durch die Theme vorgenommen werden.
Diese Funktionsdefinition können wir jetzt in ein Skript oder eigenes Paket verpacken, um uns die selbst-definierte Theme z.B. via source() immer zugänglich zu machen. Außerdem können wir dieses Skript immer beim R-Start automatisch laufen lassen, um unser Theme immer zur Verfügung zu haben (mehr dazu z.B. in der Anleitung zum Paket startup).
Um noch einmal den Vergleich zu haben, hier der Scatterplot mit dem voreingestellten Theme theme_grey():
scatter + theme_grey()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
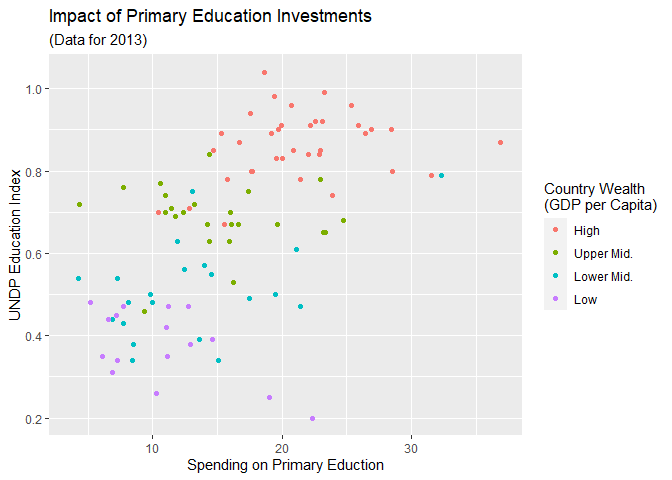
Und mit unseren Anpassungen im eigenen Theme:
scatter + theme_pandar()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
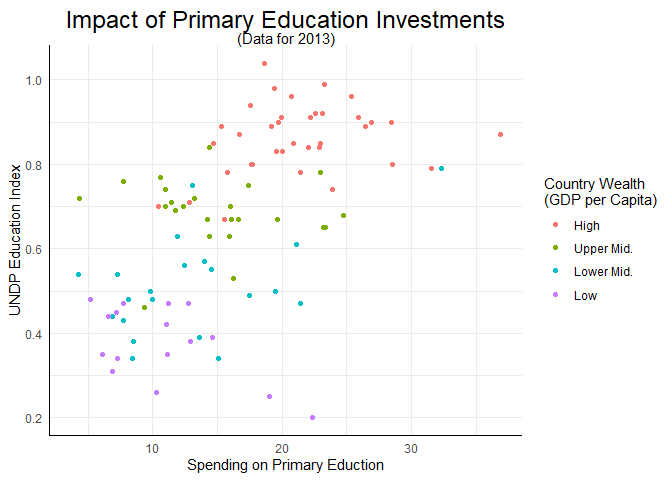
Um unser Theme für den Rest der Inhalte global als den Standard festzulegen, können wir wieder mit theme_set() arbeiten:
theme_set(theme_pandar())
Farben
Bisher haben wir gesehen, wie die “Rahmenbedingungen” der Grafik mit unserem Theme angepasst werden können - also wie Titel und Hintergrund aussehen geändert werden oder wir festlegen welche Achsen wie beschriftet werden. Was dabei bisher konstant war, war die Farbgebung, die aufgrund der Gruppierungsvariable Wealth zustande kommt. Damit ist jetzt Schluss.
In ggplot2 wird die Vergabe von Farben in der Ästhetik anhand von zwei Dingen unterschieden: der Geometrie und dem Skalenniveau der Variable, die die Färbung vorgibt. In der Einführung in ggplot haben wir die Unterschiede bezüglich des Skalenniveaus schon gesehen: Kontinuierliche Variablen (Variablen, die in R als numeric definiert sind) werden anhand eines Blau-Farbverlaufs dargestellt, diskrete Variablen (Variablen, die in R als factor definiert sind) anhand eines vordefinierten Schemas unterschiedlicher Farben. Dieses Schema ist das Brewer Farbschema, welches usprünglich für Kartendarstellungen entwickelt wurde. Das Ganze können wir uns natürlich auch an unserem aktuellen Beispiel noch einmal verdeutlichen, wenn wir statt der Gruppeneinteilung des Wohlstands die zugrundeliegende, stetige Variable Wealth zur Färbung verwenden. Leider ist der Wohlstand bei Ländern, wie auch bei Individuen, sehr schief verteilt, sodass eine Logarithmierung des Income eine bessere Differenzierung erlaubt:
ggplot(edu_2013, aes(x = Primary, y = Index, color = log(Income))) +
geom_point()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
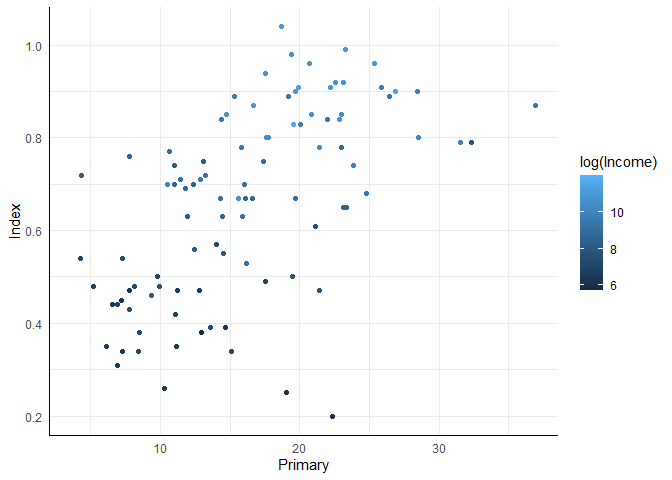
Bezüglich Geometrie wird bei der Färbung zwischen fill und color unterschieden - also ob eine Geometrie mit einer Farbe gefüllt wird oder ihr Rand mit dieser Farbe gezeichnet wird. In den bisherigen Abbildungen haben wir noch kein Beispiel gehabt, in dem etwas gefüllt werden könnte, aber im ggplotpourri haben wir dafür ein paar Beispiele dargestellt.
Kehren wir aber erst einmal zu unserem bisherigen Beispiel zurück: Nehmen wir an, dass wir unsere Abbildung irgendwo drucken möchten - Farbdruck ist wahnsinnig teuer. Um mit Grautönen zu arbeiten, können wir z.B. scale_color_grey benutzen:
scatter + scale_color_grey()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
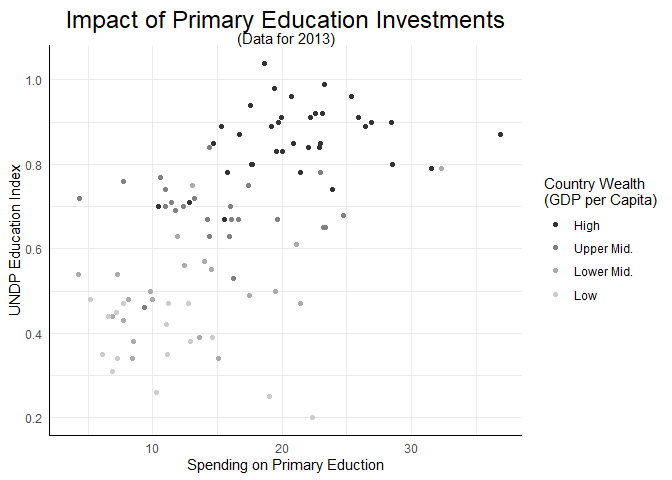
Das oben erwähnte Paket ggthemes enthält auch weitere Farbpaletten, die wir nutzen können, um unseren Plot nach unseren Vorlieben zu gestalten. Wichtig ist beispielsweise, dass es eine Palette namens colorblind hat, die Farben so auswählt, dass sie auch von Personen mit Farbblindheit differenziert werden können. In Fällen mit 6 oder weniger Gruppen bietet sich darüber hinaus an mit der Ästhetik pch (für plot-character) zu arbeiten. Darüber hinaus gibt es für Fans der Filme von Wes Anderson z.B. das Paket wesanderson, welches für jeden seiner Filme die Farbpalette parat hat.
Aber wir können natürlich auch eine, zu unserem eigenen Theme passende, eigene Farbpalette definieren. Für diese Palette können wir zunächst in einem Objekt die Farben festhalten, die wir benötigen. In ggplot2 ist es dabei am gängigsten, Farben entweder über Worte auszuwählen oder via hexadezimaler Farbdefinition zu bestimmen. Für die vier Farben, die von der Corporate Design Abteilung der Goethe Uni Frankfurt definiert werden ergibt sich z.B. folgendes Objekt:
pandar_colors <- c('#00618f', '#737c45', '#e3ba0f', '#ad3b76')
Dieses Objekt können wir dann nutzen um mit scale_color_manual selbstständig Farben zuzuweisen:
scatter +
scale_color_manual(values = pandar_colors)
## Warning: Removed 99 rows containing missing values (`geom_point()`).
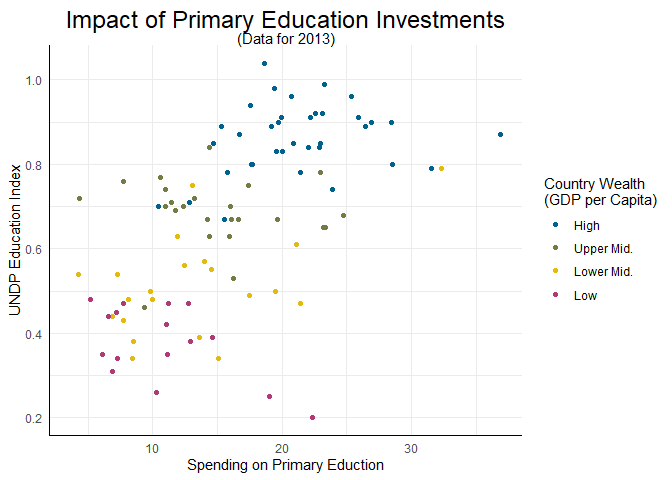
Die Zuordnung der Farben erfolgt anhand der Reihenfolge in pandar_colors und der Reihenfolge der Ausprägungen von Wealth. Wenn Ihnen also die Zuordnung misfällt, können sie ganz einfach die Reihenfolge der Farben tauschen.
Eigene Farbpalette
Um eine eigene Farbpalette zu erzeugen, die mit unserem eigenen Theme Hand in Hand gehen kann, können wir natürlich auch für die Farbgebung eine eigene Funktion erzeugen. Unsere vier Farben haben wir dafür bereits, diese müssen wir nur in eine Funktion übertragen, die auch für beliebig viele unterschiedliche Ausprägungen funktioniert. Bei dem Ansatz, den wir im vorherigen Abschnitt genutzt haben, wären wir z.B. bei fünf Ausprägungen von Wealth an den Punkt gekommen, an dem wir händisch eine weitere Farbe hätten hinzufügen müssen. Um das zu umgehen, können wir Farben interpolieren. Dafür bietet uns ggplot die Möglichkeit mit colorRamp() bzw. colorRampPalette() aus einer begrenzten Anzahl von Farben theoretisch unendliche viele verschiedene Abstufungen zu erzeugen.
Beim Erzeugen einer eigenen Farbpalette bietet es sich an - ist aber nicht zwingend erforderlich - das Benennungsschema von ggplot beizubehalten. In Anlehnung an z.B. scale_color_brewer() (die Voreinstellung in ggplot2) können wir unsere Farbpalette scale_color_pandar() nennen:
scale_color_pandar <- function(discrete = TRUE, ...) {
pal <- colorRampPalette(pandar_colors)
if (discrete) {
discrete_scale('color', 'pandar_colors', palette = pal, ...)
} else {
scale_color_gradientn(colors = pal(4), ...)
}
}
Dröseln wir auf, was in dieser Funktion passiert. Wir definieren für die Funktion ein Argument: discrete soll dazu genutzt werden, entweder Farben für diskrete oder für stetige Variablen zu erzeugen. Der erste Schritt in der Funktion ist es, mit der schon erwähnten Funktion colorRampPalette() Farben zu interpolieren, falls unsere vier vorgefertigten Farben nicht ausreichen. Für den Fall, dass wir diskrete Variablen haben (if (discrete)) wird eine diskrete Skala (discrete_scale) erzeugt, die Punkte färben soll. Wenn wir eine Funktion als scale_fill_pandar() für das Ausmalen von Geometrien definieren würden, würden wir hier das Argument fill benutzen. Dieser Skala geben wir einen Namen (pandar_colors) und reichen die gerade interpolierte Palette weiter (palette = pal). Sollten wir keine diskreten Variablen haben (else) nutzen wir unsere vier Farben (pal(4)) um einen Farbgradienten (scale_color_gradientn) zu erzeugen.
Weil wir hier die gleichen Farben genutzt haben, wie im letzten Abschnitt, unterscheidet sich unsere Abbildung nicht von der, die wir schon gesehen haben:
scatter + scale_color_pandar()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
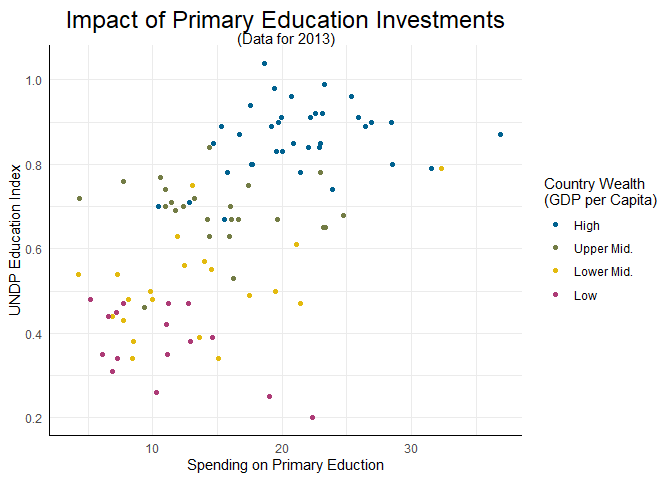
Interessant wird es dann, wenn wir weniger oder mehr als unsere vier Ausprägungen haben. Sehen wir zunächst, was passiert, wenn wir z.B. nur zwei Gruppen haben. Dazu können wir eine binäre Version der Variable Wealth erzeugen, in der die Stufen zu High und Low zusammengefasst sind:
edu_2013$Wealth_bin <- edu_2013$Wealth
levels(edu_2013$Wealth_bin) <- list('High' = c('High', 'Upper Mid.'),
'Low' = c('Lower Mid.', 'Low'))
Die entsprechende Abbildung sieht dann so aus:
ggplot(edu_2013, aes(x = Primary, y = Index, color = Wealth_bin)) +
geom_point() +
scale_color_pandar()
## Warning: Removed 99 rows containing missing values (`geom_point()`).
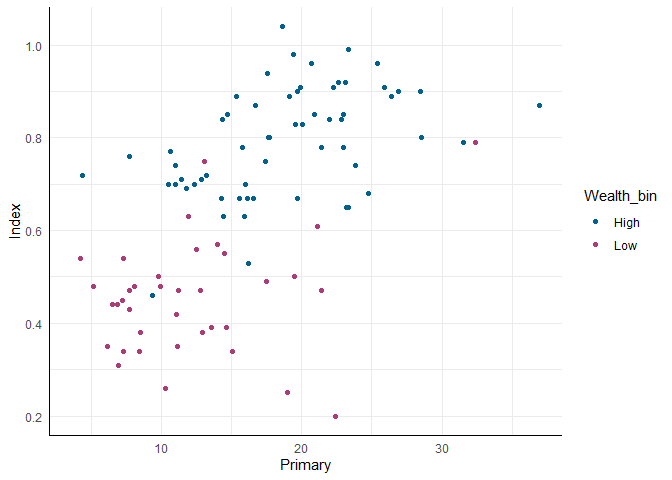
Hier wurden also die beiden Endpunkte unserer Farbpalette genutzt, um die Unterschiede der Gruppen zu verdeutlichen. Sehen wir, was passiert, wenn wir eine kontinuierliche Variable nutzen - erneut die logarithmierte Income Variable. Hierbei dürfen wir nicht vergessen, unserer Farbpalette mitzuteilen, dass wir jetzt eine stetige Variable benutzen:
ggplot(edu_2013, aes(x = Primary, y = Index, color = log(Income))) +
geom_point() +
scale_color_pandar(discrete = FALSE)
## Warning: Removed 99 rows containing missing values (`geom_point()`).
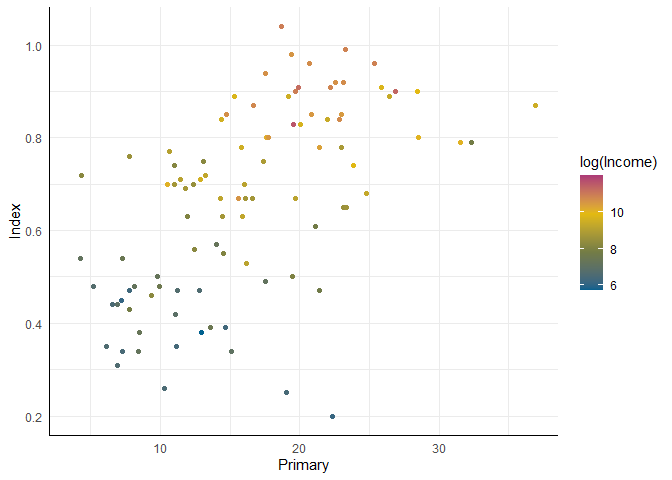
Hier wird jetzt ein Farbverlauf durch unsere vier Farben gelegt und genutzt, um unterschiedliche Ausprägungen von Income zu differenzieren. In beiden Varianten hat unsere Farbpalette aber ganze Arbeit geleistet!
Wer sich für noch mehr Informationen bezüglich eigener Farbpaletten interessiert (z.B. um eine Palette für das eigene Institut zu erstellen) wird in diesem extrem detaillierten Blogbeitrag von Simon Jackson fündig.
Das, was wir hier und im ggplot Intro besprochen haben, ist schon vollkommen ausreichend um damit anzufangen, die unglaublich weite Welt der Datenvisualisierung zu erkunden. Im ggplotpourri haben wir noch ein paar Beispiele zusammengetragen und in den Abschnitten zu gganimate und plotly geht es dann um animierte bzw. interaktive Datenvisualisierung!