](/media/header/coastal_sailing.jpg)
Exploratorische Faktorenanalyse
Laden der Daten & Übersicht
Wir beginnen mit dem Datensatz, mit dem wir letztes Skript aufgehört haben. Wie immer müsst ihr dafür den Pfad wählen, in dem sich die Daten befinden. Mit glimpse() können wir uns nochmal einen kurzen Überblick verschaffen, wie die Datenstruktur aussieht und welche Variablen wir nach der Itemanalyse beibehalten/ausgeschlossen haben.
library(tidyverse)
library(here)
data_gis_final <- read.csv(url("https://raw.githubusercontent.com/jlschnatz/PsyBSc8_Diagnostik/main/src/data/data-gis-final.csv"))
glimpse(data_gis_final)
## Rows: 300
## Columns: 17
## $ GIS1 <int> 4, 4, 4, 4, 3, 4, 4, 3, 4, 4, 3, 3, 4, 3, 4, 3, 4, 3, 4, 4, 3, 3, 3, 3, 4, 3, 4,…
## $ GIS2 <int> 3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 4, 3, 4,…
## $ GIS3 <int> 3, 3, 4, 0, 4, 3, 3, 4, 3, 3, 3, 3, 4, 3, 4, 3, 1, 4, 3, 3, 4, 3, 1, 3, 3, 4, 4,…
## $ GIS4 <int> 3, 4, 4, 3, 3, 4, 3, 4, 3, 3, 3, 3, 3, 4, 4, 3, 3, 4, 3, 3, 4, 3, 3, 2, 4, 3, 4,…
## $ GIS5 <int> 3, 4, 3, 3, 3, 4, 3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 4,…
## $ GIS6 <int> 3, 4, 3, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4,…
## $ GIS7 <int> 4, 4, 3, 4, 4, 3, 4, 3, 3, 3, 4, 4, 4, 4, 3, 3, 4, 4, 4, 4, 3, 3, 3, 1, 4, 3, 4,…
## $ GIS8 <int> 4, 4, 4, 4, 4, 3, 3, 4, 4, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 4, 1, 4,…
## $ GIS10 <int> 4, 4, 4, 3, 3, 3, 3, 1, 3, 3, 3, 3, 4, 3, 1, 3, 3, 3, 3, 3, 3, 3, 1, 2, 4, 3, 4,…
## $ GIS11 <int> 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 4, 3, 4,…
## $ GIS12 <int> 4, 4, 4, 3, 3, 3, 3, 3, 3, 4, 3, 4, 4, 3, 4, 3, 3, 4, 3, 3, 4, 3, 4, 3, 4, 2, 4,…
## $ GIS13 <int> 4, 4, 4, 3, 4, 3, 3, 3, 4, 3, 3, 4, 3, 3, 4, 4, 3, 4, 4, 4, 3, 3, 4, 3, 4, 1, 4,…
## $ GIS14 <int> 3, 4, 3, 3, 4, 3, 4, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 1, 3, 3, 3, 4, 2, 4, 2, 4,…
## $ GIS15 <int> 3, 4, 3, 3, 4, 3, 3, 3, 3, 4, 3, 3, 3, 4, 4, 3, 3, 3, 3, 3, 3, 3, 4, 1, 4, 3, 4,…
## $ GIS19 <int> 4, 4, 4, 3, 4, 3, 4, 4, 4, 4, 4, 3, 4, 4, 4, 3, 3, 4, 4, 4, 4, 3, 3, 2, 4, 3, 4,…
## $ GIS20 <int> 3, 4, 4, 3, 4, 3, 3, 3, 3, 3, 4, 3, 4, 4, 3, 3, 3, 3, 3, 4, 3, 3, 1, 2, 4, 3, 4,…
## $ GIS21 <int> 3, 4, 4, 3, 4, 3, 3, 3, 3, 3, 4, 3, 3, 4, 3, 3, 4, 3, 3, 4, 3, 3, 3, 1, 4, 3, 4,…
Als Erinnerung können wir uns nochmal die psychometrische Eigenschaften der beibehaltenen Items anschauen. Wir benutzen dafür wieder die Funktion aus dem sjPlot Package, die wir letztes Skript kennengelernt haben.
library(sjPlot)
sjt.itemanalysis(
df = data_gis_final,
factor.groups.titles = NULL # kein Titel
)
| Row | Missings | Mean | SD | Skew | Item Difficulty | Item Discrimination | α if deleted | |
|---|---|---|---|---|---|---|---|---|
| GIS1 | 0.00 % | 3.44 | 0.74 | -1.8 | 0.86 | 0.62 | 0.93 | |
| GIS2 | 0.00 % | 3.29 | 0.79 | -1.5 | 0.82 | 0.49 | 0.94 | |
| GIS3 | 0.00 % | 3.25 | 0.89 | -1.25 | 0.81 | 0.65 | 0.93 | |
| GIS4 | 0.00 % | 3.39 | 0.73 | -1.22 | 0.85 | 0.67 | 0.93 | |
| GIS5 | 0.00 % | 3.23 | 0.68 | -0.77 | 0.81 | 0.67 | 0.93 | |
| GIS6 | 0.00 % | 3.11 | 0.82 | -0.8 | 0.78 | 0.64 | 0.93 | |
| GIS7 | 0.00 % | 3.27 | 0.9 | -1.53 | 0.82 | 0.60 | 0.94 | |
| GIS8 | 0.00 % | 3.26 | 0.97 | -1.57 | 0.81 | 0.68 | 0.93 | |
| GIS10 | 0.00 % | 2.98 | 0.88 | -0.89 | 0.75 | 0.63 | 0.93 | |
| GIS11 | 0.00 % | 3.27 | 0.73 | -1.16 | 0.82 | 0.70 | 0.93 | |
| GIS12 | 0.00 % | 3.41 | 0.81 | -1.64 | 0.85 | 0.73 | 0.93 | |
| GIS13 | 0.00 % | 3.29 | 0.82 | -1.66 | 0.82 | 0.75 | 0.93 | |
| GIS14 | 0.00 % | 3.13 | 0.92 | -1.21 | 0.78 | 0.67 | 0.93 | |
| GIS15 | 0.00 % | 3.16 | 0.75 | -0.9 | 0.79 | 0.66 | 0.93 | |
| GIS19 | 0.00 % | 3.22 | 0.87 | -1.28 | 0.80 | 0.70 | 0.93 | |
| GIS20 | 0.00 % | 2.96 | 0.91 | -0.82 | 0.74 | 0.76 | 0.93 | |
| GIS21 | 0.00 % | 3.03 | 0.92 | -1.01 | 0.76 | 0.69 | 0.93 | |
| Mean inter-item-correlation=0.472 · Cronbach's α=0.937 | ||||||||
Identifikation der Anzahl der Faktoren
Zur Bestimmung der Anzahl der Faktoren in der exploratorischen Faktorenanalyse gibt es mehrere Herangehensweisen, die bereits in dem Lernbar-Video vorgestellt wurden: das Eigenwertkriterium/Kaiser-Guttman-Kriterium (Kaiser, 1960), der Scree-Plot (Cattell, 1966) und die Parallelanalyse (Horn, 1965). Jedes dieser Verfahren hat seine eigenen Vorbehalte hinsichtlich Konservativität und Objektivität. Deswegen ist es in der Praxis empfehlenswert, die Ergebnisse mehrerer Kriterien gleichzeitig zu berücksichtigen, um die höchste Genauigkeit zu erzielen. Für eine Übersicht hinsichtlich verschiedener Extraktionsmethoden und deren Vergleich siehe: Auerswald, 2019.
1. Möglichkeit: Eigenwertkriterium
Das Eigenwertkriterium bzw. Kaiser-Kriterium ist das liberalste Maß der Entscheidung, weswegen tendeziell dadurch viele Faktoren entstehen. Zur Bestimmung werden die Eigenwerte errechnet und alle Faktoren beibehalten, deren Eigenwert >= 1 ist. Es gibt zwei Möglichkeiten, den Eigenwerteverlauf mittels R zu bestimmen.
1. Weg: Base-R Funktion eigen()
# Base
eigen(cor(data_gis_final))$values
## [1] 8.5991430 1.2760151 0.8990121 0.7701418 0.7212324 0.6443391 0.5840884 0.4867182 0.4715973
## [10] 0.4470492 0.4315886 0.3538997 0.3248867 0.2850224 0.2738591 0.2365159 0.1948910
# Alternative Schreibweise (mit pipes):
cor(data_gis_final) %>%
eigen() %>%
chuck("values")
## [1] 8.5991430 1.2760151 0.8990121 0.7701418 0.7212324 0.6443391 0.5840884 0.4867182 0.4715973
## [10] 0.4470492 0.4315886 0.3538997 0.3248867 0.2850224 0.2738591 0.2365159 0.1948910
# in Tabellenform:
cor(data_gis_final) %>%
eigen() %>%
chuck("values") %>%
as_tibble() %>%
tab_df(
title = "Eigenwertverlauf",
col.header = "Eigenwert",
show.rownames = TRUE
)
| Row | Eigenwert |
|---|---|
| 1 | 8.60 |
| 2 | 1.28 |
| 3 | 0.90 |
| 4 | 0.77 |
| 5 | 0.72 |
| 6 | 0.64 |
| 7 | 0.58 |
| 8 | 0.49 |
| 9 | 0.47 |
| 10 | 0.45 |
| 11 | 0.43 |
| 12 | 0.35 |
| 13 | 0.32 |
| 14 | 0.29 |
| 15 | 0.27 |
| 16 | 0.24 |
| 17 | 0.19 |
2. Weg: FactorMineR Package
Mit dem alternativen Weg könnnen wir noch etwas mehr Informationen als nur die Eigenwerte extrahieren. Dazu müssen wir das FactoMineR Package laden bzw. wenn noch nicht geschehen auch installieren. Wir verwenden die PCA() Funktion und extrahieren im Anschluss die Eigenwerte und Varianzaufklärung der möglichen Faktoren aus der abgespeichertern Liste.
library(FactoMineR)
pca <- PCA(data_gis_final, graph = FALSE)
eigen <- as_tibble(pca$eig) # als dataframe abspeichern
eigen <- as_tibble(pca[["eig"]]) # Alternative
# in Tabellenform:
tab_df(
x = eigen,
show.rownames = TRUE,
title = "Eigenwertverlauf mit zusätzlicher Information hinsichtlich erklärte Varianz",
col.header = c("Eigenwert", "Erklärte Varianz", "Kum. erklärte Varianz")
)
| Row | Eigenwert | Erklärte Varianz | Kum. erklärte Varianz |
|---|---|---|---|
| 1 | 8.60 | 50.58 | 50.58 |
| 2 | 1.28 | 7.51 | 58.09 |
| 3 | 0.90 | 5.29 | 63.38 |
| 4 | 0.77 | 4.53 | 67.91 |
| 5 | 0.72 | 4.24 | 72.15 |
| 6 | 0.64 | 3.79 | 75.94 |
| 7 | 0.58 | 3.44 | 79.38 |
| 8 | 0.49 | 2.86 | 82.24 |
| 9 | 0.47 | 2.77 | 85.01 |
| 10 | 0.45 | 2.63 | 87.64 |
| 11 | 0.43 | 2.54 | 90.18 |
| 12 | 0.35 | 2.08 | 92.26 |
| 13 | 0.32 | 1.91 | 94.17 |
| 14 | 0.29 | 1.68 | 95.85 |
| 15 | 0.27 | 1.61 | 97.46 |
| 16 | 0.24 | 1.39 | 98.85 |
| 17 | 0.19 | 1.15 | 100.00 |
Wie anhand der Ergebnisse erkennbar ist, wird durch das Eigenwertkriterium ein Modell mit 2 Faktoren vorgeschlagen.
2. Möglichkeit: Scree-Plot
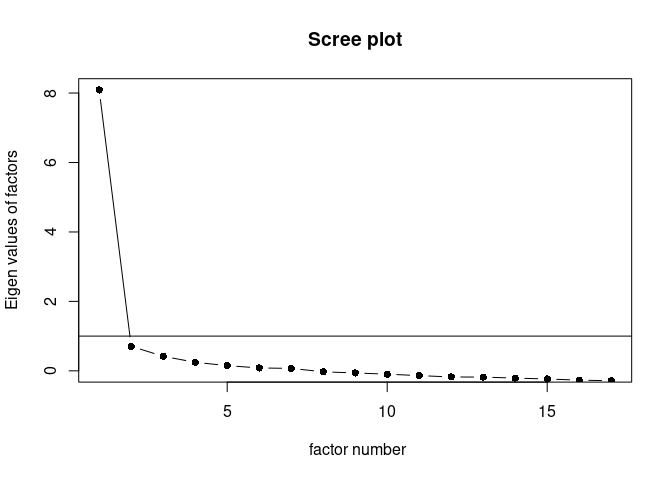
Der Scree-Plot ist ein visuell deskriptives Kriterium zur Entscheidung der Faktoren. Dabei ist das Kriterium konservativer als das Eigenwertkriterium.Wie in dem Lernbar-Video beschrieben wird der optische Knick herangezogen, um die Entscheidung über die Faktorenanzahl zu treffen. Alle Faktoren, die sich “über” dem Knick befinden, werden beibehalten.
Um in R einen Scree-Plot zu generieren, könnnen wir entweder die Base-R Plotting Funktionen verwenden oder das sehr erfolgreiche ggplot2 Package der tidyverse Familie benutzen. Dabei können zwar mit Base R Plotting Funktionen zwar in nur wenigen Zeilen ein Plot erstellt werden, bieten dafür aber nicht so viele Anpassungsmöglichkeiten und folgen keiner klaren Struktur im Vergleich zu ggplot2. Wem es also wichtig sein sollte, schöne Plots zu generieren, sollte eher das ggplot2 Package nutzen. Wer nochmal eine ggplot2 Auffrischung brauchen sollte, findet hier einen nützlichen Link: R for Data Science.
1. Weg: Base-R
Wir benutzen das psych Package, um den Scree-Plot zu erstellen. Dabei verwendet dieses Package im Hintergrund Base R für das Plotting.
library(psych)
scree(
rx = data_gis_final,
factors = TRUE,
pc = FALSE, # sollen Hauptkomponenten auch dargestellt werden?
hline = 1 # Plot mit Knicklinie, hline = -1 -> ohne Linie
)
2. Weg: ggplot2 Package
Wir erstellen zunächst einen Dataframe, indem die Eigenwerte und Nummerierung der Faktoren als zwei Variablen gespeichert sind. Danach werden diese Daten in Layern mittels ggplot2 geplottet.
data_eigen <- tibble(
Eigenwert = eigen(cor(data_gis_final))$values,
Faktor = 1:length(Eigenwert)
)
# Basis-ggplot Layer
ggplot(data = data_eigen, aes(x = Faktor, y = Eigenwert)) +
# Horizontale Linie bei y = 1
geom_hline(
color = "darkgrey",
yintercept = 1,
linetype = "dashed"
) +
# Hinzufügen der Linien
geom_line(alpha = 0.6) +
# Hinzufügen der Punkte
geom_point(size = 3) +
# Achsenveränderung der y-Achse
scale_y_continuous(
breaks = seq(0, 10, 2),
limits = c(0, 10),
expand = c(0, 0)
) +
# Achsenveränderung der x-Achse
scale_x_continuous(
breaks = seq(1, 17),
limits = c(1, 17)
) +
# Theme
theme_classic() +
theme(axis.title = element_text(face = "bold"))
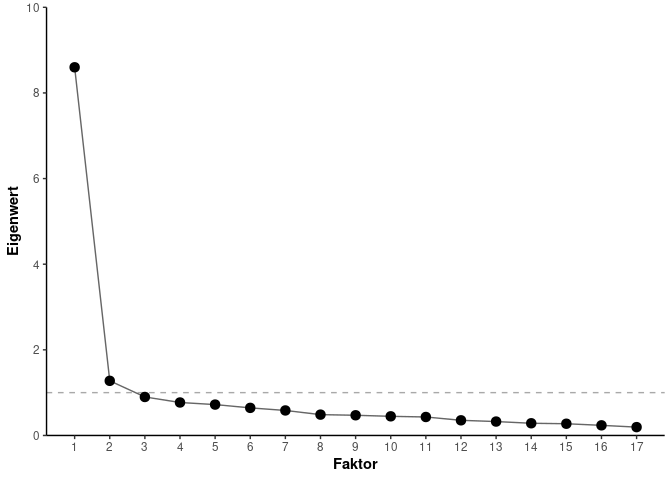
Die Ergebnisse der Scree-Plots suggerieren ein Modell mit nur einem Faktor. Dementsprechend wäre die Entscheidung im Vergleich zum Kaiser-Kriterium deutlich konservativer.
3. Möglichkeit: Parallelanalyse
Die letzte vorgestellte Möglichkeit ist die Parallelanalyse. Hierbei werden die empirischen Eigenwerte einer Faktorenanalyse mit den Eigenwerten eines simulierten Datensatzen mit normalverteilten Daten verglichen (Klopp, 2010). Es werden dabei Faktoren beibehalten, bei denen der empirische Eigenwerte größer als der simulierte Eigenwert ist. Anders formuliert werden Faktoren beibehalten, die mehr Varianz aufklären als rein zufällig simulierte Daten. Von den drei vorgestellten Kriterien ist diese das konservativste Kriterium
Möglichkeit 1
fa.parallel(
x = data_gis_final,
fm = "pa", # Principal Axis Factoring Extraktion
fa = "both", # FA + PCA
n.iter = 500, # Anzahl der Simulationen
quant = .95, # Vergleichsintervall
main = "Parallelanalyse mittels Base R und psych-Package"
)
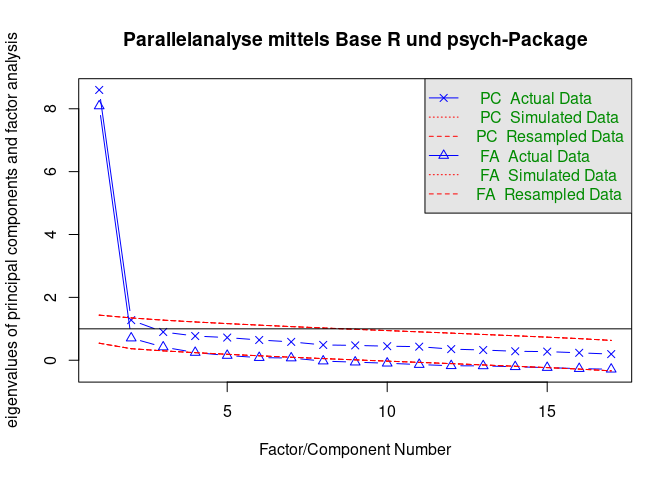
## Parallel analysis suggests that the number of factors = 3 and the number of components = 1
Möglichkeit 2
Wir speichern zunächst die ausgegeben Daten der Funktion fa.parallel() in einem Objekt ab. Danach erstellen wir einen Dateframe mit den relevanten Informationen (empirische und simulierte Eigenwerte).
data_pa <- fa.parallel(
x = data_gis_final,
fm= "pa",
fa = "fa",
plot = FALSE,
n.iter = 500,
quant = .95
)
## Parallel analysis suggests that the number of factors = 3 and the number of components = NA
# Dataframe
tibble(
Observed = data_pa$fa.values, # empirisch
Simulated = data_pa$fa.sim # simuliert
) %>%
# Zeilennummer als eigene Variable
rownames_to_column(var = "Factor") %>%
mutate(Factor = as.integer(Factor)) %>%
# Wide-Format in Long-Format
pivot_longer(
cols = -Factor,
names_to = "obs_sim",
values_to = "Eigenvalue"
) %>%
ggplot(aes(x = Factor, y = Eigenvalue, color = obs_sim)) +
geom_line(
size = 0.7,
alpha = .8
) +
geom_point(
size = 3.5,
alpha = .8
) +
scale_y_continuous(
breaks = seq(0, 9, 3),
limits = c(-.5, 9),
expand = c(0, 0)
) +
scale_x_continuous(
breaks = seq(1, 17),
limits = c(0, 17),
expand = c(0, 0)
) +
scale_color_manual(
name = NULL,
values = c("#1D3554", "#DFE07C")
) +
coord_cartesian(clip = "off") +
theme_light() +
theme(legend.position = "bottom")
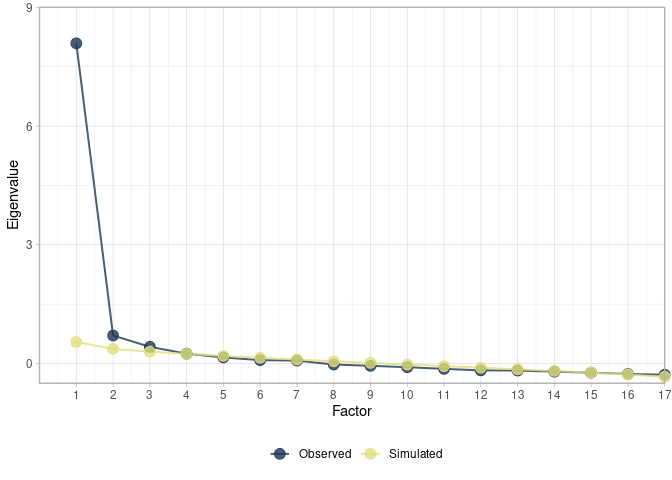
Die Ergebnisse der Parallelanalyse suggerieren ein Modell mit drei Faktoren. Da dies das konservativste Vorgehen ist, entscheiden wir uns für ein dreifaktorielles Modell für die weitere Analyse.
Extraktion der Faktoren & Rotation
Als nächsten Schritt können wir nun die eigentliche exploratorische Faktoranalyse durchführen. Wir benutzen dafür wieder ein Befehl aus dem sjPlot Package, mit dem wir direkt die Faktorstruktur als Tabelle darstellen können. Es gibt aber auch viele alternative Packages, mit denen eine EFA durchgeführt werden kann (z.B. psych fa() oder base R factanal()).
Wir spezifizieren ein Modell mit 3 Faktoren, die mittels Principal Axis Facoring extrahiert werden (method = "pa") und führen anschließend eine oblimine Rotation durch (rotation = "oblimin"). Wie in der Lernbar bereits vorgestellt, gibt es unterschiedliche Rotationsverfahren nach der Extraktion der Faktoren. Bei orthogonalen Rotation bleiben die latenten Faktoren unkorreliert, wohingegen bei obliquer Rotation die Faktoren miteinander korrelieren dürfen. Alle Rotationsverfahren haben das Ziel, möglichst eine Einfachstruktur zu erhalten, d.h. dass jedes Item möglichst nur auf einen Faktor lädt. Für einen Vergleich verschiedener Rotationsverfahren und wann welches angewendet werden sollte: Costello, 2005.
tab_fa(
data = data_gis_final,
nmbr.fctr = 3,
rotation = "oblimin",
fctr.load.tlrn = 0,
method = "pa",
title = "Faktorenanalyse",
)
| Factor 1 | Factor 2 | Factor 3 | |
|---|---|---|---|
| GIS1 | 0.23 | 0.04 | 0.50 |
| GIS2 | 0.03 | -0.07 | 0.66 |
| GIS3 | 0.15 | -0.11 | 0.77 |
| GIS4 | 0.22 | 0.09 | 0.51 |
| GIS5 | -0.15 | 0.38 | 0.61 |
| GIS6 | 0.07 | 0.39 | 0.31 |
| GIS7 | 0.44 | 0.26 | 0.01 |
| GIS8 | 0.65 | 0.10 | 0.06 |
| GIS10 | 0.00 | 0.30 | 0.47 |
| GIS11 | 0.23 | 0.26 | 0.35 |
| GIS12 | 0.83 | -0.05 | 0.09 |
| GIS13 | 0.71 | 0.13 | 0.05 |
| GIS14 | 0.41 | 0.33 | 0.05 |
| GIS15 | 0.25 | 0.50 | 0.03 |
| GIS19 | 0.36 | 0.50 | -0.03 |
| GIS20 | 0.03 | 0.76 | 0.13 |
| GIS21 | 0.12 | 0.75 | -0.04 |
| Cronbach's α | 0.86 | 0.86 | 0.87 |
Finale Modellspezifizierung
Die Faktorladungen von Item 6 und Item 11 liegen unter dem üblichen Cut-off Wert von $\lambda = 0.4$ (bzw. teils auch $\lambda = 0.3$) und sollten deswegen ausgeschlossen werden. Alle anderen Items laden weitestgehend gut auf einen Faktor und besitzen hohe Faktorladungen. Für eine abschließende Modellspezifizierung erstellen wir einen neuen Datensatz ohne die zwei genannten Variablen und führen erneut eine Faktorenanalyse durch.
drop_facload1 <- c("GIS6","GIS11")
data_gis_fa1<- dplyr::select(data_gis_final, -all_of(drop_facload1))
tab_fa(
data = data_gis_fa1,
nmbr.fctr = 3,
rotation = "oblimin",
fctr.load.tlrn = 0,
method = "pa",
title = "Finale Faktorenanalyse"
)
| Factor 1 | Factor 2 | Factor 3 | |
|---|---|---|---|
| GIS1 | 0.20 | 0.07 | 0.49 |
| GIS2 | -0.03 | -0.01 | 0.67 |
| GIS3 | 0.12 | -0.09 | 0.80 |
| GIS4 | 0.22 | 0.09 | 0.50 |
| GIS5 | -0.10 | 0.36 | 0.55 |
| GIS7 | 0.48 | 0.21 | -0.00 |
| GIS8 | 0.72 | 0.02 | 0.04 |
| GIS10 | -0.03 | 0.34 | 0.45 |
| GIS12 | 0.81 | -0.04 | 0.09 |
| GIS13 | 0.76 | 0.09 | 0.03 |
| GIS14 | 0.43 | 0.32 | 0.05 |
| GIS15 | 0.25 | 0.50 | 0.02 |
| GIS19 | 0.36 | 0.50 | -0.03 |
| GIS20 | -0.01 | 0.80 | 0.12 |
| GIS21 | 0.09 | 0.78 | -0.04 |
| Cronbach's α | 0.86 | 0.86 | 0.85 |
Deskriptive Analyse der Faktorstruktur
Anschließend können wir für jeden Faktor getrennt eine finale Itemanalyse durchführen. Das sjPlot Package kann dabei alle drei Tabellen für die Faktoren gleichzeitig in einer Funktion berechnen. Dafür muss zunächst jedoch ein Index erstellt werden, der spezifiziert, welche Items zu welchem Faktor gehören. Danach kann durch das Argument factor.groups die Faktorstruktur spezifiziert werden.
fa_index <- tab_fa(
data = data_gis_fa1,
nmbr.fctr = 3,
rotation = "oblimin",
fctr.load.tlrn = 0,
method = "pa"
) %>%
pluck("factor.index")
sjt.itemanalysis(
df = data_gis_fa1,
factor.groups = fa_index,
factor.groups.titles = c("Faktor 1","Faktor 2","Faktor 3")
)
| Row | Missings | Mean | SD | Skew | Item Difficulty | Item Discrimination | α if deleted | |
|---|---|---|---|---|---|---|---|---|
| GIS7 | 0.00 % | 3.27 | 0.9 | -1.53 | 0.82 | 0.61 | 0.85 | |
| GIS8 | 0.00 % | 3.26 | 0.97 | -1.57 | 0.81 | 0.68 | 0.83 | |
| GIS12 | 0.00 % | 3.41 | 0.81 | -1.64 | 0.85 | 0.75 | 0.82 | |
| GIS13 | 0.00 % | 3.29 | 0.82 | -1.66 | 0.82 | 0.76 | 0.82 | |
| GIS14 | 0.00 % | 3.13 | 0.92 | -1.21 | 0.78 | 0.64 | 0.84 | |
| Mean inter-item-correlation=0.563 · Cronbach's α=0.862 | ||||||||
| Row | Missings | Mean | SD | Skew | Item Difficulty | Item Discrimination | α if deleted | |
|---|---|---|---|---|---|---|---|---|
| GIS15 | 0.00 % | 3.16 | 0.75 | -0.9 | 0.79 | 0.64 | 0.86 | |
| GIS19 | 0.00 % | 3.22 | 0.87 | -1.28 | 0.80 | 0.71 | 0.83 | |
| GIS20 | 0.00 % | 2.96 | 0.91 | -0.82 | 0.74 | 0.77 | 0.80 | |
| GIS21 | 0.00 % | 3.03 | 0.92 | -1.01 | 0.76 | 0.75 | 0.81 | |
| Mean inter-item-correlation=0.613 · Cronbach's α=0.864 | ||||||||
| Row | Missings | Mean | SD | Skew | Item Difficulty | Item Discrimination | α if deleted | |
|---|---|---|---|---|---|---|---|---|
| GIS1 | 0.00 % | 3.44 | 0.74 | -1.8 | 0.86 | 0.62 | 0.82 | |
| GIS2 | 0.00 % | 3.29 | 0.79 | -1.5 | 0.82 | 0.58 | 0.83 | |
| GIS3 | 0.00 % | 3.25 | 0.89 | -1.25 | 0.81 | 0.72 | 0.80 | |
| GIS4 | 0.00 % | 3.39 | 0.73 | -1.22 | 0.85 | 0.64 | 0.82 | |
| GIS5 | 0.00 % | 3.23 | 0.68 | -0.77 | 0.81 | 0.65 | 0.82 | |
| GIS10 | 0.00 % | 2.98 | 0.88 | -0.89 | 0.75 | 0.59 | 0.83 | |
| Mean inter-item-correlation=0.486 · Cronbach's α=0.848 | ||||||||
| Component 1 | Component 2 | Component 3 | |
|---|---|---|---|
| Component 1 | α=0.862 | ||
| Component 2 | 0.756 (<.001) | α=0.864 | |
| Component 3 | 0.676 (<.001) | 0.652 (<.001) | α=0.848 |
| Computed correlation used pearson-method with listwise-deletion. | |||
Ebenfalls sollte zusätzlich zur internen Konsistenz Cronbach´s $\alpha$ auch McDonald´s $\omega$ für jede Skala berechnet werden. Dafür speichern wir den Index als Dataframe und danach alle Itemnamen des jeweiligen Faktors als eigenes Objekt ab. Nun können wir eine kleine Funktion erstellen, mit der wir immer wieder für einen Datensatz $\alpha$ und $\omega$ berechnen können. Wir sparen uns somit die Arbeit, jedes Mal wieder den Code zu wiederholen, welcher im Body (hinter der eckigen Klammern) der Funktion steht. Wichtig ist, dass wir mit der return() angeben, was letztendlich dem User ausgegeben werden soll (sonst wird nichts angezeigt).
index <- as.data.frame(fa_index) %>%
rownames_to_column(var = "item")
f1_names <- pull(filter(index, fa_index == 1), item)
f2_names <- pull(filter(index, fa_index == 2), item)
f3_names <- pull(filter(index, fa_index == 3), item)
# Funktionsinput: Dataframe & Vektor der Variablennamen des jeweiligen Faktors
get_reliability <- function(.data, .var_names) {
om <- omega(dplyr::select(.data, all_of(.var_names)), plot = FALSE)
out <- list(
omega = om$omega.tot,
alpha = om$alpha
)
# Angabe, welche Objekte ausgegeben werden sollen
return(out)
}
get_reliability(data_gis_fa1, f1_names)
## $omega
## [1] 0.8937074
##
## $alpha
## [1] 0.8657088
get_reliability(data_gis_fa1, f2_names)
## $omega
## [1] 0.87744
##
## $alpha
## [1] 0.8638386
get_reliability(data_gis_fa1, f3_names)
## $omega
## [1] 0.8748985
##
## $alpha
## [1] 0.850356
Testwertanalyse
Als letztes werden wir die deskriptiven Kennwerte der Testwerte der drei Skalen genauer betrachten. Diese müssen wir zunächst erstmal berechnen. Über die Funktion rowwise() wird angegeben, dass nachfolgend eine Variable erstellt wird, bei der über die Zeilen hinweg aufsummiert werden soll. Die Variablen/Items die aufsummiert werden, können über die Funktion c_across(variablen/items) angegeben werden.
data_gis_fa1 <- data_gis_fa1 %>%
rowwise() %>%
dplyr::mutate(gis_score = sum(c_across(everything()))) %>%
dplyr::mutate(
f1 = sum(c_across(all_of(f1_names))),
f2 = sum(c_across(all_of(f2_names))),
f3 = sum(c_across(all_of(f3_names))),
)
Wir können uns mittles der describe(), welche bereits im letzten Skript vorgestellt wurde die wichtigsten deskriptiven Kennwerte ausgeben lassen.
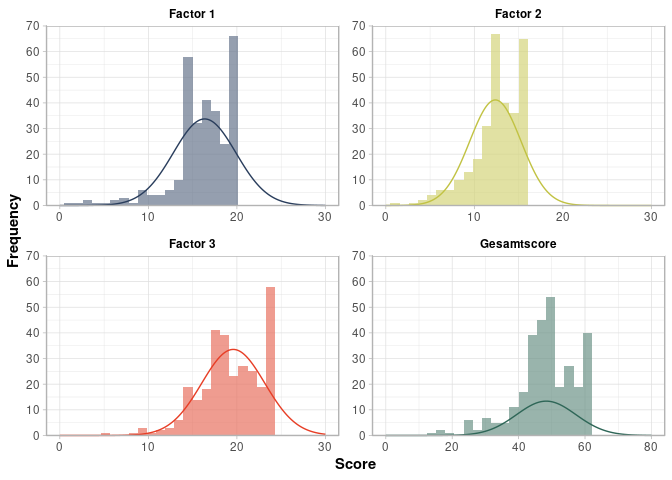
tab_df(describe(data_gis_fa1$f1))
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 300 | 16.36 | 3.55 | 17 | 16.93 | 2.97 | 1 | 20 | 19 | -1.59 | 3.21 | 0.21 |
tab_df(describe(data_gis_fa1$f2))
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 300 | 12.38 | 2.91 | 12 | 12.68 | 2.97 | 1 | 16 | 15 | -0.77 | 0.67 | 0.17 |
tab_df(describe(data_gis_fa1$f3))
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 300 | 19.59 | 3.57 | 20 | 19.94 | 2.97 | 5 | 24 | 19 | -0.80 | 0.76 | 0.21 |
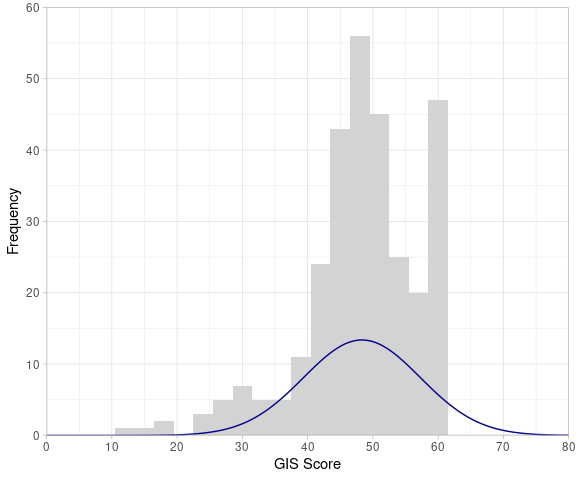
Diese deskriptiven Kennwerte können wir zudem abschließend in einem Histogramm mit unterlegter Normalverteilung visualisieren. Wir benutzen für das Plotten der Normalverteilung das Package ggh4x mit der Funktion stat_theodensity(). Das praktische hierbei ist, dass wir nicht aktiv die Parameter der Normalverteilung (M und SD) angeben müssen, sondern die Funktion das für uns im Hintergrund auf Basis der Daten berechnet. Im nachfolgenden Beispiel wird der Plot für den Gesamttestwert (alle Items) berechnet. Wenn eine der 3 Skalen geplottet werden soll, muss dies nur in der ggplot() Funktion angegeben werden (s.h. Code).
library(ggh4x)
ggplot(data_gis_fa1, aes(x = gis_score)) + # oder x = f1/f2/f3
geom_histogram(
binwidth = 3,
fill = "lightgrey",
) +
stat_theodensity(
mapping = aes(y = after_stat(count)),
distri = "norm",
color = "darkblue",
size = 0.5
) +
scale_x_continuous(
name = "GIS Score",
limits = c(0, 80), # Achsenlimit
breaks = seq(0, 80, 10), # Achsenabschnitte
expand = c(0, 0)
) +
scale_y_continuous(
name = "Frequency",
limits = c(0, 60),
breaks = seq(0, 60, 10),
expand = c(0, 0)
) +
theme_light()
Für diejenigen unter euch, die sich in etwas anspruchvolleres R bzw. ggplot2-Territorium wagen wollen: Es gibt auch die Möglichkeit, alle Skalen gleichzeitig in einem Bild zu plotten. Um jeden einzelnen Schritt der großen Pipe zu verstehen, geht am besten jeden einzelnen Layer durch und schaut, wie sich der Plot verändert. Auch hilfreich kann es sein, wenn man die einzelnen Parameter in den Layern verändert, um zu schauen, was diese bewirken. Es reicht allerdings natürlich auch völlig aus, wenn ihr euch an dem letzten Plot orientiert!
library(ggh4x)
library(fitdistrplus)
strip_labels <- as_labeller(c(f1 = "Factor 1", f2 = "Factor 2",
f3 = "Factor 3", gis_score = "Gesamtscore"))
data_gis_fa1 %>%
dplyr::select(f1, f2, f3, gis_score) %>%
pivot_longer(
cols = everything(),
names_to = "factor",
values_to = "score"
) %>%
ggplot(aes(x = score, fill = factor)) +
facet_wrap(
facets = vars(factor),
labeller = strip_labels,
scales = "free"
) +
geom_histogram(
bins = 30,
alpha = 0.7,
show.legend = FALSE
) +
stat_theodensity(aes(y = after_stat(count), color = factor)) +
facetted_pos_scales(
x = list(
factor == "f1" ~ scale_x_continuous(limits = c(0, 30)),
factor == "f2" ~ scale_x_continuous(limits = c(0, 30)),
factor == "f3" ~ scale_x_continuous(limits = c(0, 30)),
factor == "gis_score" ~ scale_x_continuous(limits = c(0, 80))
)
) +
scale_y_continuous(
expand = c(0, 0),
limits = c(0, 70),
breaks = seq(0, 70, 10)
) +
scale_x_continuous(expand = c(0, 0)) +
coord_cartesian(clip = "off") +
xlab("Score") +
ylab("Frequency") +
scale_fill_manual(values=c("#68768cFF","#d4d47bFF","#e87261FF","#6d9388FF")) +
scale_colour_manual(values=c("#293d5cFF","#c1c243FF","#e73e26FF","#2e6657FF")) +
guides(color = "none", fill = "none") +
theme_light() +
theme(
panel.spacing = unit(.35, "cm"),
axis.title = element_text(face = "bold"),
strip.text = element_text(
face = "bold",
color = "black",
margin = margin(b = 5)),
strip.background = element_rect(fill = "white")
)
Literatur
Auerswald, M., & Moshagen, M. (2019). How to determine the number of factors to retain in exploratory factor analysis: A comparison of extraction methods under realistic conditions. Psychological Methods, 24(4), 468.
Cattell, R. B. (1966). The scree test for the number of factors. Multivariate Behavioral Research, 1(2), 245–276.
Costello, A. B., & Osborne, J. (2005). Best practices in exploratory factor analysis: Four recommendations for getting the most from your analysis. Practical Assessment, Research, and Evaluation, 10(1), 7.
Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis. Psychometrika, 30(2), 179–185.
Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20(1), 141–151.
Klopp, E. (2010). Explorative Faktorenanalyse. https://doi.org/10.23668/psycharchives.9238