](/media/header/frogs_on_phones.jpg)
Die Lösungen sind exemplarische Möglichkeiten. In R gibt es immer viele Wege, die zum Ziel führen. Wenn Sie einen anderen mit dem korrekten Ergebnis gewählt haben, kann dieser genauso richtig sein wie die hier präsentierten Ansätze.
Vorbereitung
Laden Sie die Daten aus
fb25.rdaoder direkt von der Website über die gelernten Befehle. Die Bedeutung der einzelnen Variablen und ihre Antwortkategorien können Sie dem Dokument Variablenübersicht entnehmen.
Lösung
Daten laden:
load(url('https://pandar.netlify.app/daten/fb25.rda'))
Überblick über den Datensatz verschaffen:
dim(fb25)
## [1] 211 43
str(fb25)
## 'data.frame': 211 obs. of 43 variables:
## $ mdbf1 : num 3 3 3 4 4 3 3 3 2 3 ...
## $ mdbf2 : num 3 2 3 1 3 3 3 2 3 2 ...
## $ mdbf3 : num 1 2 2 3 1 1 1 1 3 3 ...
## $ mdbf4 : num 1 2 2 1 1 1 1 1 1 2 ...
## $ mdbf5 : num 1 2 2 2 1 1 1 3 2 3 ...
## $ mdbf6 : num 3 2 3 1 3 2 1 3 4 2 ...
## $ mdbf7 : num 1 3 2 3 2 2 2 4 2 3 ...
## $ mdbf8 : num 3 3 3 4 4 3 3 3 3 3 ...
## $ mdbf9 : num 1 3 2 2 1 4 2 1 3 4 ...
## $ mdbf10 : num 3 3 2 1 3 3 2 2 3 3 ...
## $ mdbf11 : num 1 2 2 1 1 1 2 1 3 2 ...
## $ mdbf12 : num 3 2 2 3 3 2 2 3 2 1 ...
## $ time_pre : num 43 55 79 53 28 35 44 29 30 52 ...
## $ lz : num 5 3 5 6 5.8 5.2 4.6 4.8 6.8 2.6 ...
## $ extra : num 3.5 4 2.5 4 4.5 3 2.5 2.5 3.5 2 ...
## $ vertr : num 4 3 4 3 2 4.5 2.5 4 3 2.5 ...
## $ gewis : num 2.5 4.5 3.5 4.5 3 3.5 2.5 2 4 5 ...
## $ neuro : num 2 2 3 4 4 5 4.5 1 4.5 5 ...
## $ offen : num 2.5 4.5 4.5 5 4.5 4.5 3.5 4 5 4.5 ...
## $ prok : num 2.6 2.5 2.8 3 2.5 2.9 3 3.4 3.2 2.7 ...
## $ trust : num 3.33 3.83 3.83 3.67 3.67 ...
## $ uni1 : num 0 0 1 0 0 0 0 0 0 1 ...
## $ uni2 : num 1 1 1 1 1 1 1 1 1 1 ...
## $ uni3 : num 1 0 0 1 0 1 0 0 0 0 ...
## $ uni4 : num 0 0 0 0 0 0 0 1 0 1 ...
## $ sicher : int 3 4 4 4 4 3 NA 3 4 3 ...
## $ angst : int 2 2 3 4 3 3 2 2 2 4 ...
## $ fach : int 4 4 4 4 4 4 4 2 2 2 ...
## $ ziel : int 2 2 2 2 2 2 2 1 1 3 ...
## $ wissen : int NA 3 5 NA NA NA 4 NA 3 5 ...
## $ therap : int NA 5 5 NA NA NA 5 NA 5 4 ...
## $ lerntyp : int 3 3 3 3 1 3 1 3 2 1 ...
## $ hand : int 2 2 2 2 2 2 2 2 1 2 ...
## $ job : int 2 1 2 2 1 1 1 1 2 2 ...
## $ ort : int 1 2 2 1 2 1 1 2 2 1 ...
## $ ort12 : int 2 3 1 3 2 2 2 1 1 1 ...
## $ wohnen : int 3 2 3 1 4 3 1 2 4 1 ...
## $ attent_pre : num 4 5 4 5 5 5 5 5 5 4 ...
## $ gs_post : num 3 NA 2.75 3.25 3 3.25 NA 3 2.75 2.25 ...
## $ wm_post : num 3.25 NA 2.75 3.25 2.75 3.25 NA 2.25 1.75 2.25 ...
## $ ru_post : num 2.25 NA 2.25 2.75 2.25 2.5 NA 2 2 2.75 ...
## $ time_post : num 18 NA 71 17 21 51 NA 31 27 34 ...
## $ attent_post: num 5 NA 5 5 5 5 NA 5 5 5 ...
Der Datensatz besteht aus 211 Zeilen (Beobachtungen) und 43 Spalten (Variablen).
Aufgabe 1
Untersuchen Sie, welche Arbeitsbranche Sie und Ihre Kommiliton:innen nach dem Studium anstreben!
- Vergeben Sie zunächst die korrekten Wertelabels an die Ausprägungen der Variable.
- Lassen Sie sich absolute und relative Häufigkeiten ausgeben.
- Untersuchen Sie mit den geeigneten Maßen die zentrale Tendenz und Dispersion dieser Variable.
Lösung
Faktor erstellen
fb25$ziel <- factor(fb25$ziel,
levels = 1:4,
labels = c("Wirtschaft", "Therapie", "Forschung", "Andere"))
levels(fb25$ziel)
## [1] "Wirtschaft" "Therapie" "Forschung" "Andere"
Absolute und relative Häufigkeiten anfordern
table(fb25$ziel) # absolut
##
## Wirtschaft Therapie Forschung Andere
## 25 121 27 30
prop.table(table(fb25$ziel)) # relativ
##
## Wirtschaft Therapie Forschung Andere
## 0.1231527 0.5960591 0.1330049 0.1477833
Zentrale Tendenz und Dispersion für nominalskalierte Variablen: Modus, relativer Informationsgehalt
# Modus
which.max(table(fb25$ziel))
## Therapie
## 2
#relativer Informationsgehalt
hj <- prop.table(table(fb25$ziel)) # hj erstellen
ln_hj <- log(hj) # Logarithmus bestimmen
summand <- ln_hj * hj # Berechnung fuer jede Kategorie
summe <- sum(summand) # Gesamtsumme
k <- length(hj) # Anzahl Kategorien bestimmen
relInf <- -1/log(k) * summe # Relativer Informationsgehalt
relInf
## [1] 0.8059006
Der Modus der Variable lautet Therapie - die meisten Ihres Jahrgangs (n = 121 bzw. 59.61%) streben einen Job in diesem Bereich an. Der relative Informationsgehalt der Variable beträgt 0.81. Sie sehen hier, dass wir im Code einen kleinen Unterschied zum Tutorial eingebaut haben. Die Anzahl der Kategorien wird nicht mehr durch dim(tab) sondern durch length(hj) bestimmt. Das Resultat ist nicht verschieden - die Anzahl der Kategorien wird gezählt. Wir wollen somit aber nochmal deutlich machen, dass es in R immer sehr viele Wege zu einem Ziel geben kann.
Aufgabe 2
Die Variable therap enthält die Angaben über das Ausmaß, in dem sich Sie und Ihre Kommilitonen:innen für anwendungsbezogene Aspekte interessieren.
- Bestimmen Sie für diese Variable den Modus.
- Untersuchen Sie die Streuung für diese Variable optisch, indem Sie einen Boxplot erstellen.
- Bestimmen Sie die Quartile, den Interquartilsbereich (IQB) und den Interquartilsabstand auch als Zahlen.
Lösung
Modus
which.max(table(fb25$therap))
## 5
## 3
Häufigkeiten
table(fb25$therap)
##
## 3 4 5
## 3 28 60
prop.table(table(fb25$therap))
##
## 3 4 5
## 0.03296703 0.30769231 0.65934066
Der Modus der Variable therap beträgt 5, d.h. diese Antwortkategorie wurde am häufigsten genannt (n = 60 bzw. 65.93%).
Boxplot
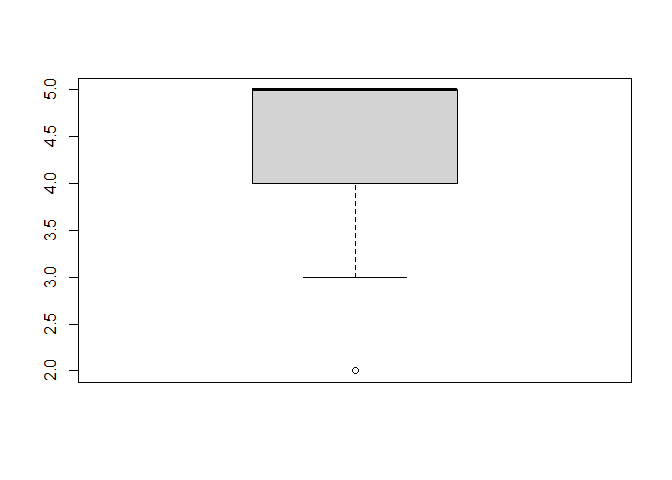
boxplot(fb25$therap)
Quartile
quantile(fb25$therap, c(.25,.5,.75), na.rm=T)
## 25% 50% 75%
## 4 5 5
Der Median beträgt 5. Das 1. und 3. Quartil betragen 4 bzw. 5. Folglich sind die Grenzen des Interquartilsbereich (IQB) 4 und 5. Der Interquartilsabstand (IQA) beträgt 1.
Aufgabe 3
Erstellen Sie für die Variable wohnen eine geeignete Abbildung.
- Stellen Sie sicher, dass die einzelnen Ausprägungen der Variable in der Darstellung interpretierbar benannt sind!
- Dekorieren Sie diese Abbildung nach eigenen Wünschen (z.B. mit einer Farbpalette und Achsenbeschriftungen).
- Speichern Sie die Grafik per Syntax als .jpg-Datei mit dem Namen “Befragung-fb25.jpg” ab.
Lösung
Faktor erstellen
fb25$wohnen <- factor(fb25$wohnen,
levels = 1:4,
labels = c("WG", "bei Eltern", "alleine", "sonstiges"))
Ansprechende Grafik erstellen
Um eine ansprechende Grafik zu erhalten, können wir einige Argumente anpassen. Hier ist natürlich nur eine beispielhafte Lösung abgebildet.
# Ansprechende Darstellung
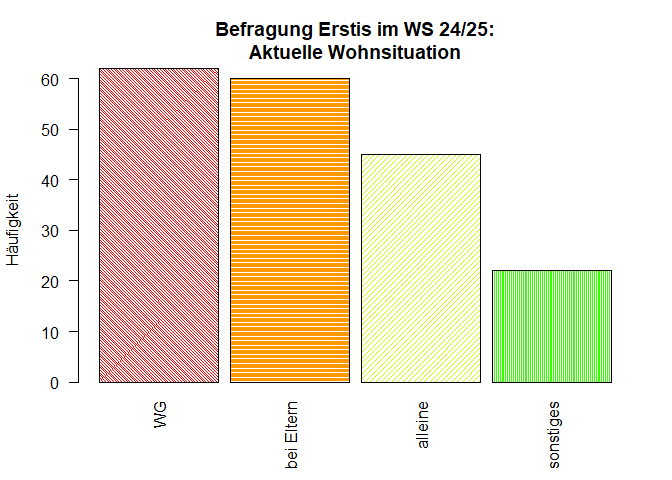
barplot(
# wichtig: Funktion auf Häufigkeitstabelle, nicht die Variable selbst anwenden:
table(fb25$wohnen),
# aussagekräftiger Titel, inkl. Zeilenumbruch ("\n")
main = "Befragung Erstis im WS 25/26:\nAktuelle Wohnsituation",
# y-Achsen-Beschriftung:
ylab = "Häufigkeit",
# Farben aus einer Farbpalette:
col = rainbow(10),
# Platz zwischen Balken minimieren:
space = 0.1,
# graue Umrandungen der Balken:
border = "grey2",
# Unterscheidlich dichte Schattierungen (statt Füllung) für die vier Balken:
density = c(50, 75, 25, 50),
# Richtung, in dem die Schattierung in den vier Balken verläuft
angle = c(-45, 0, 45, 90),
# Schriftausrichtung der Achsen horizontal:
las=2,
#y-Achse erweitern, sodass mehr Platz zum Titel bleibt:
ylim = c(0,70))
Speichern (per Syntax)
jpeg("Befragung-fb25.jpg", width=20, height=10, units="cm", res=200)
barplot(
table(fb25$wohnen),
main = "Befragung Erstis im WS 25/26:\nAktuelle Wohnsituation",
ylab = "Häufigkeit",
col = rainbow(10),
space = 0.1,
border = "grey2",
density = c(50,75,25,50),
angle = c(-45,0,45,90),
las=2,
ylim = c(0,70))
dev.off()
Im Arbeitsverzeichnis sollte die Datei nun vorliegen.