](/media/header/toy_car_crash.jpg)
R Crash-Kurs
Kernfragen dieses Beitrags
- Was ist R und was ist RStudio?
- Was ist die Konsole und was ist die Syntax?
- Wie kann ich Syntax ausführen?
- Wie sehen Ergebnisse von Befehlen in R aus?
- Wie kann ich R als Taschenrechner und für logische Vergleiche benutzen?
- Was sind Funktionen und wie sind sie aufgebaut?
- Wie bekomme ich in R Hilfe?
- Was sind Objekte?
- Was ist das Environment?
- Was sind Vektoren und welche unterschiedlichen Arten gibt es?
- Welche mehrdimensionalen Datenstrukturen gibt es und worin unterscheiden sie sich?
- Wie kann ich aus Datensätze einzelne Variablen oder Beobachtungen extrahieren und sie hinzufügen?
- Wie importiere und exportiere ich Daten?
Warum R nutzen?
Ziel dieses gesamten R-Praktikums ist es, dass Sie am Ende des Semesters geübt im Umgang mit R sind, die Grundfunktionalität beherrschen und die Analyseverfahren durchführen können, die in der Vorlesung behandelt werden. Damit wir - oder genauer genommen, eigentlich Sie - dieses Ziel erreichen, legen wir hier mit einer “kurzen” Einführung in die Grundprinzipien von und den Umgang mit R los. Viele Dinge, die hier besprochen werden, sind auch in den anderen Sitzungen zu dieser Veranstaltung relevant und werden dort immer wieder vorkommen. Deswegen ist es das Beste, einfach nebenbei RStudio auf zu haben und die hier beschriebenen Schritte auch direkt selbst mit zu machen.
Zuerst aber ein bisschen ausholen: R haben wir für die Lehre aus einer Reihe von Programmen ausgewählt, weil es ein paar hervorragende Eigenschaften hat:
- R ist “free & free”
- “Free (as in beer)”: gratis verfügbar, für jeden zugänglich
- “Free (as in speech)”: durch die Öffentlichkeit, nicht durch einzelne Instanz reguliert
- Extrem weit verbreitet
- Laut Google Scholar knapp 250 000 mal zitiert
- Allein in den letzten 30 Tagen 877521 mal heruntergeladen
- Für Hausarbeiten, Projekte, Abschlussarbeiten gut geeignet
- Auswertung und Fließtext in einer Datei (wie dieser) vereinbar
- Wiederherstellbarer Arbeitsablauf
- Mit jedem teilbar
- Auch außerhalb der Universität und Forschung eine gefragte Fähigkeit
Ein paar nützliche Links für R sind die R Main Page, wo R runtergeladen werden kann und diverse technische Details zu finden sind. Für eine kurze, schnelle Einführung in verschiedene R-relevante Themen bietet sich Quick R und, spezifisch für die Psychologie, das Personality Project an.
RStudio
Weil die traditionelle R Nutzeroberfläche extrem spartanisch ist, werden wir auf dieser Seite mit RStudio arbeiten. RStudio ist eine zusätzliche Nutzeroberfläche, die den Umgang mit R durch diverse convenience features ein wenig erleichtert. Es muss separat installiert werden, ist aber, genau wie R selbst, gratis erhältlich. Um RStudio herunterzuladen besuchen Sie am einfachsten https://posit.co/, wo Sie oben rechts direkt von einem großen “Download RStudio”-Button begrüßt werden sollten.
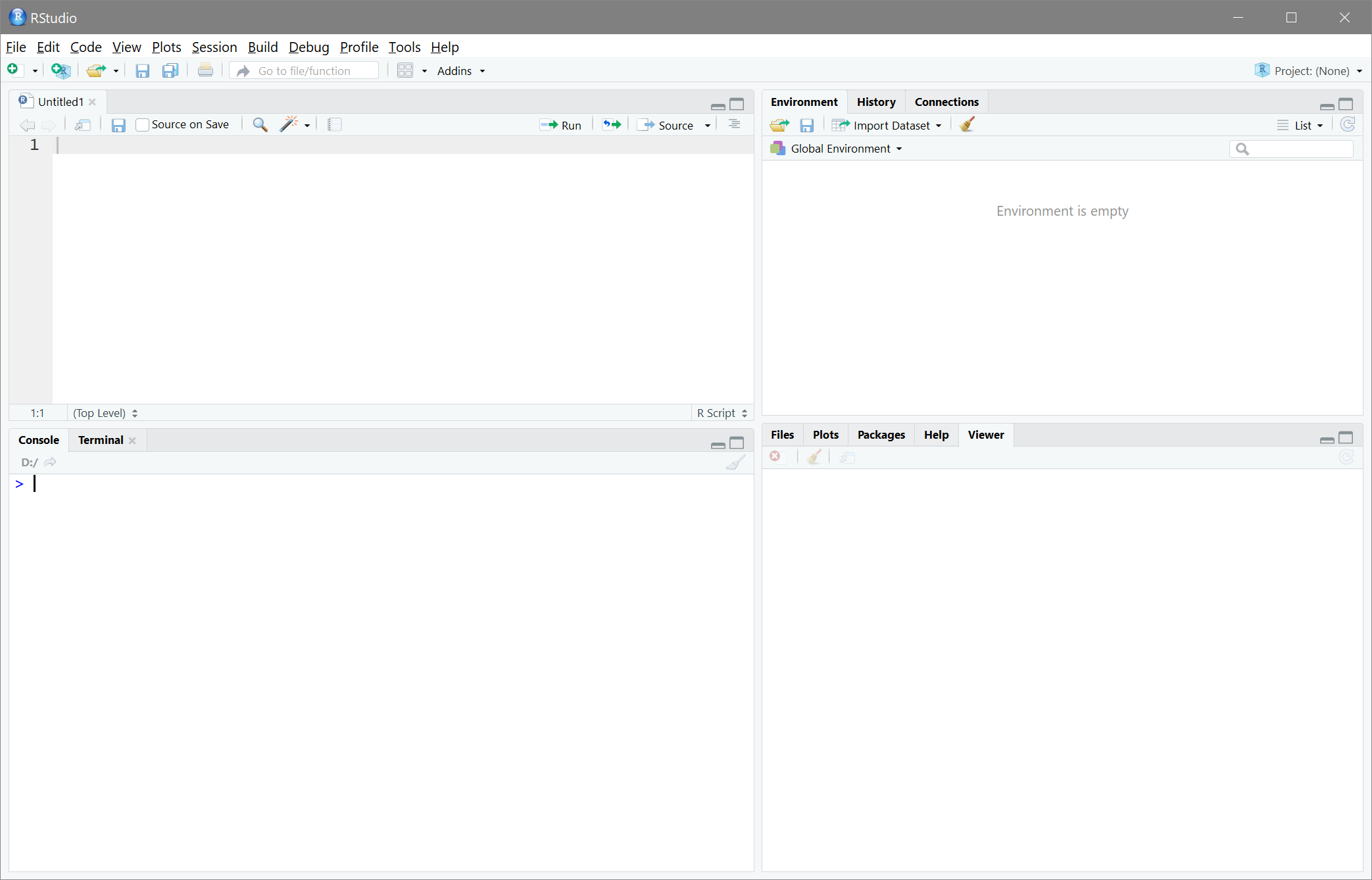
RStudio besteht aus vier Panels. Zunächst sind nur drei sichtbar - durch Strg+Shift+n (OS X: Cmd+Shift+n) oder über den
 Button öffnen Sie eine neue Skriptdatei und das vierte Panel erscheint.
R ist syntaxbasiert - genau genommen ist R eigentlich eine Programmiersprache und kein Auswertungsprogramm - und im neu erschienenen Fenster können Sie diese Syntax schreiben. Das pure schreiben bewirkt zunächst nichts.
Damit etwas passiert, muss die Syntax mit Strg+Return (OS X: cmd+Return) oder mit dem
Button öffnen Sie eine neue Skriptdatei und das vierte Panel erscheint.
R ist syntaxbasiert - genau genommen ist R eigentlich eine Programmiersprache und kein Auswertungsprogramm - und im neu erschienenen Fenster können Sie diese Syntax schreiben. Das pure schreiben bewirkt zunächst nichts.
Damit etwas passiert, muss die Syntax mit Strg+Return (OS X: cmd+Return) oder mit dem
 Button ausgeführt werden. Wenn Sie z.B.
Button ausgeführt werden. Wenn Sie z.B. 3 + 4 in die Syntax schreiben und so ausführen, erscheint in der Konsole:
3 + 4
## [1] 7
Die beiden verbleibenden Panels stellen jeweils als Tabs verschiedene Dinge dar. Oben rechts wird per Voreinstellung das Environment angezeigt. Was genau das bedeutet sehen wir in Kürze. Unten rechts werden fünf Tabs dargestellt, von denen vier im Verlauf des Semesters von Relevanz sein werden:
- Files: erlaubt die Navigation in Ordnern um Dateien ausfindig zu machen.
- Plots: hier werden grafische Abbildungen dargestellt.
- Packages: gibt eine Übersicht über die installierten Erweiterungen für R.
- Help: das wahrscheinlich wichtigste Tab - hier wird die Hilfe zu R-Funktionen angezeigt.
Erste Schritte
Eine wichtige Funktionalität jeder Programmiersprache sind Kommentare, die dazu dienen sollen das Vorgehen in einer Syntax zu gliedern und leichter verständlich zu machen. In R werden sie durch (beliebig viele) # begonnen und enden bei einem Zeilenumbruch. Mit Kommentaren kann Syntax auch in verschiedene Abschnitte gegliedert werden. Empfehlenswert ist es, solche Abschnittüberschriften mit #### zu beginnen und mit ---- zu beenden. RStudio erkennt solche Kommentare automatisch als Überschriften und stellt über den
 Button eine darauf basierende Gliederung zur Verfügung.
Button eine darauf basierende Gliederung zur Verfügung.
Wir können das direkt einfach ausprobieren:
#### R als Taschenrechner ----
3 + 4 # Addition
## [1] 7
3 - 4 # Subtraktion
## [1] -1
3 * 4 # Multiplikation
## [1] 12
3 / 4 # Division
## [1] 0.75
3 ^ 4 # Potenz
## [1] 81
In der Gliederung sollte in RStudio jetzt die Überschrift “R als Taschenrechner” auftauchen.
In diesem Beispiel sind zwischen den Zahlen und Operatoren immer Leerzeichen. Leerzeichen spielen für R keine Rolle - sie werden bei der Ausführung ignoriert. Daher können Leerzeichen und Einschübe zu Beginn von Zeilen genutzt werden um der Syntax noch mehr Struktur zu geben. Generell wird empfohlen, R Syntax wie normale Sätze zu schreiben und Leerzeichen zu nutzen, um die Lesbarkeit der Syntax zu gewährleisten. Einige weitere Empfehlungen zur Gestaltung von R Syntax finden Sie im Online Buch von Hadley Wichkam und im Styleguide, der von Google Programmier*innen genutzt wird.
Neben einfachen Taschenrechner-Funktionen mit numerischen Ergebnissen kann R auch logische Abfragen und Vergleiche durchführen:
#### Logische Abfragen ----
3 == 4 # Ist gleich?
## [1] FALSE
3 != 4 # Ist ungleich?
## [1] TRUE
3 > 4 # Ist größer?
## [1] FALSE
3 < 4 # Ist kleiner?
## [1] TRUE
3 >= 4 # Ist größer/gleich?
## [1] FALSE
3 <= 4 # Ist kleiner/gleich?
## [1] TRUE
Die Ergebnisse dieser Abfragen sind boolesch - also immer entweder wahr (TRUE) oder falsch (FALSE). Wie in vielen anderen Programmiersprachen wird in R das ! genutzt um eine Aussage zu negieren. Wir könnten also die “ist ungleich” Relation != auch als “nicht (ist gleich)” umformulieren:
!(3 == 4)
## [1] TRUE
Wie in der Mathematik üblich, wird der Inhalt von Klammern als erstes evaluiert und ergibt hier FALSE. Dieses Ergebnis wird dann durch ! negiert, sodass das finale Ergebnis TRUE ist.
Funktionen und Argumente
Das Nutzen von R als Taschenrechner ist - streng genommen - ein Sonderfall, der vom “üblichen Weg” abweicht, mit dem Dinge in R umgesetzt werden. Mithilfe der einfachen Addition können wir eine Summe bilden:
3 + 4 + 1 + 2
## [1] 10
Für R typischer wäre aber die Umsetzung mit
sum(3, 4, 1, 2)
## [1] 10
Hier wird die Funktion sum() genutzt um die Summe der Argumente (3, 4, 1 und 2) zu bilden. An diesem Beispiel lässt sich bereits die generelle Struktur von Funktionen in R erkennen:
funktion(argument1, argument2, argument3, ...)
In R werden Funktionen namentlich aufgerufen und alle Argumente, die diese Funktion entgegennehmen kann, folgen in Klammern. Die sum()-Funktion ist dabei sogar wieder ein Sonderfall, weil sie unendlich viele Argumente entgegennehmen kann. Eine eher typische Funktion ist z.B. der Logarithmus:
log(100)
## [1] 4.60517
Wie zu erkennen ist, wird mit log() der natürliche Logarithmus einer Zahl bestimmt. Es ist aber mit der gleichen Funktion auch möglich Logarithmen mit jeder anderen Basis zu bilden:
log(100, 10)
## [1] 2
Um zu verstehen, wie das in R funktioniert, können wir die grundlegende Struktur von Logarithmen betrachten. Diese bestehen aus drei Komponenten: $\log_{b}(x) = y$. Dabei bezeichnet $b$ die Basis (Englisch: base) des Logarithmus, $x$ das Argument und $y$ das Ergebnis. Die oben dargestellte Funktion log nimmt also als Erstes $x$ und als Zweites $b$ entgegen.
Weil es bei der beinahe unendliche Mengen von Funktionen in R unmöglich ist, sich die korrekte Reihenfolge aller Argumente zu merken, können Argumente auch direkt benannt werden:
log(x = 100, base = 10)
## [1] 2
In diesem Fall muss man nicht mehr die Reihenfolge der Argumente, sondern lediglich deren Namen kennen. Wenn Argumente so benannt werden, können sie in einer beliebigen Reihenfolge in der Funktion genutzt werden:
log(base = 10, x = 100)
## [1] 2
Weil es nur geringfügig einfacher ist, sich alle Namen von Argumente statt deren Reihenfolge zu merken, bietet R diverse Möglichkeiten sich diesbezüglich helfen zu lassen. Um z.B. die Namen und Reihenfolge von Argumenten einer Funktion in Erfahrung zu bringen kann die Funktion args() auf jede R-Funktion angewendet werden:
args(log)
## function (x, base = exp(1))
## NULL
Dieses Ergebnis bedeutet, dass log() zwei mögliche Argumente hat: x und base. Darüber hinaus besagt base = exp(1), dass es für das zweite Argument eine Voreinstellung gibt, nämlich die Zahl exp(1), also die Euler’sche Zahl $e$. Diese Zahl wird dabei als Ergebnis der Funktion exp() gewonnen:
exp(1)
## [1] 2.718282
Das Ergebnis dieser Funktion wird bestimmt und als Argument an die Funktion log() weitergegeben. Das zeigt bereits eine zentrale Eigenschaft von R: Funktionen können ineinander geschachtelt werden. Dabei werden Klammern wie in der Mathematik gehandhabt und von innen nach außen evaluiert.
Hilfe
R bietet ein sehr detailliertes und gutes integriertes Hilfesystem. Wie Ihnen bestimmt schon aufgefallen ist, versucht RStudio sie mit Auto-Ergänzungen und Pop-Ups über die Argumente einer Funktion zu unterstützen. Für log() sieht das z.B. so aus:
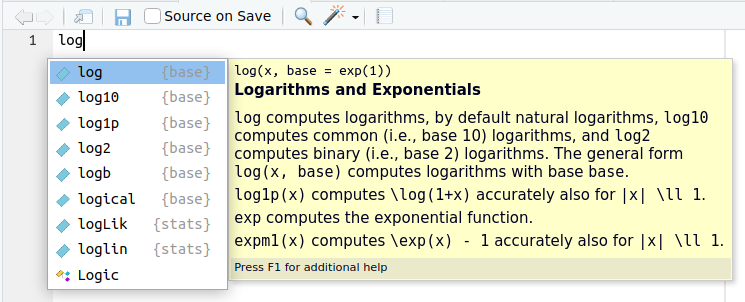
Auch R-intern gibt es diverse Unterstützungsmöglichkeiten. Wenn man mehr Informationen bezüglich einer spezifischen Funktion benötigt, kann man help() auf jede beliebige Funktion anwenden (bzw. ? vor den Namen einer Funktion schreiben). Sie sollten - besonders zum Einstieg in R - häufig und gezielt diese Hilfe in Anspruch nehmen.
help(log)
Die Hilfe zur Funktion wird im Panel unten rechts geöffnet und ist ein Dokument, das üblicherweise aus den folgenden Abschnitten besteht:
- Description: eine kurze Beschreibung der Funktion.
- Usage: die grundlegende Struktur der Funktion. Dieser Abschnitt enthält alle Argumente, die diese Funktion entgegennimmt. In manchen Fällen kann dieser Abschnitt auch mehrere Funktionen enthalten, die gemeinsam dokumentiert sind. Argumente, denen ein
= etwasfolgt, haben eine Voreinstellung und müssen nicht bei jedem Aufruf der Funktion angesprochen werden (sondern nur, wenn man eine andere Einstellung als die Voreinstellung nutzen will). Argumente, denen kein=folgt, müssen hingegen bei jeder Anwendung definiert werden. - Arguments: Eine Liste der Argumente mit einer kurzen Beschreibung.
- Details: Zusatzinformationen zur Funktion.
- Values: Eine Liste der Ergebniselemente, die diese Funktion erzeugt. In R sind Ergebnisse häufig größer als das was in der Konsole gedruckt wird und dieser Abschnitt liefert eine Übersicht über diese Inhalte.
- See also: Ähnliche Funktionen, die vielleicht eher dem entsprechen, was man sucht.
- Examples: Der vielleicht wichtigste Abschnitt - hier wird die Funktion beispielhaft angewendet.
Wie Sie hier sehen, ist die Information, die Ihnen RStudio im Pop-Up anbietet der Anfang dessen, was Sie hier in der Hilfe präsentiert bekommen.
Wenn man den genauen Namen einer Funktion nicht kennt, ist help() meistens nur wenig hilfreich. RStudio bietet an der oberen rechte Ecke des Hilfe-Fensters noch ein zusätzliches Suchfeld für die Hilfe, welches nicht nur die Funktionsnamen, sondern auch deren Beschreibungen durchsucht:

Dadurch öffnet sich im Hilfefenster eine Auflistung aller Befehle, die diesen Suchbegriff enthalten. Die Notation ist dabei immer paket::funktion() - also das Bündel von Funktionen, in dem wir diese spezifische Funktion gefunden haben und dann deren Name. Was genau Pakete sind, werden wir uns später noch einmal vertieft angucken. Sie können einfach links auf den Namen klicken um zur Hilfe der Funktion zu gelangen.
Nachrichten, Warnungen und Fehler
Im Umgang mit R ist es unvermeidlich: es werden Fehler passieren. Wichtig ist nur, dass man weiß, was die Rückmeldung bedeutet, die R produziert und wie man darauf reagieren sollte. Zusätzlich zum unwahrscheinlichen Fall, in dem das korrekte Ergebnis produziert wird, kann man in R drei Formen von Rückmeldungen unterscheiden: messages, warnings und errors.
Eine Message liefert Informationen und dient ausschließlich der Kommunikation. Hier werden z.B. Hinweise bezüglich des Zustands einer Funktion gegeben (etwa, wenn sie sich noch in der Beta-Phase befindet) oder Zusatzinformationen geliefert, die die Interpretation eines Ergebnisse vereinfachen sollen. Der Text, den R bei jedem Start produziert, ist ein Beispiel für eine Message.
Eine Warning deutet darauf hin, dass höchstwahrscheinlich etwas nicht so gelaufen ist, wie geplant, aber dennoch ein Ergebnis produziert wurde. Für den Logarithmus erscheint beispielsweise eine Warnung:
log(-1)
## Warning in log(-1): NaNs produced
## [1] NaN
Warnungen beginnen in R mit dem Wort Warning. In diesem Fall werden wir darauf hingewiesen, dass als Ergebnis der Funktion NaN (Not a Number) erzeugt wurde - also wahrscheinlich ein Ergebnis, das wir nicht haben wollten, als wir den Logarithmus aufgerufen haben.
Die letzte Art sind Error, die immer damit einhergehen, dass kein Ergebnis produziert wird. Für den Logarithmus erhalten wir einen Fehler wenn
log(argument = 10)
## Error: argument "x" is missing, with no default
In diesem Fall werden wir darauf hingewiesen, dass wir keine Einstellung für das Argument x vorgenommen haben, obwohl dieses keine Voreinstellung hat. Daher ist die Funktion unfähig ein Ergebnis zu produzieren. Bei Fehlern sollten Sie bedenken, dass diese das Ausführen mehrerer Zeilen nicht unterbrechen. Wenn Sie also eine komplette Syntax auf einmal ausführen, können aus Fehlern Folgefehler entstehen, weil ein Ergebnis nicht entstanden ist, mit dem Sie anschließend weiter rechnen wollten.
Objekte und das Environment
Einer der großen Vorteile von R gegenüber anderen Ansätzen zur statistischen Datenanalyse ist die Möglichkeit Ergebnisse in Objekten abzulegen und diese als Argumente in anderen Funktionen weiter zu verwenden. Dadurch ergibt sich in R die Möglichkeit sehr große Teile von Auswertungen und Ergebnisdarstellung mit generell gehaltenen Skripten zu automatisieren. Die Zuweisung eines Ergebnisses zu einem Objekt erfolgt über den sog. Zuweisungspfeil <-.
my_num <- sum(3, 4, 1, 2)
Anders als zuvor wird in diesem Fall in der Konsole kein Ergebnis ausgedruckt, sondern lediglich der Befehl gespiegelt. Das Ergebnis der Summen-Funktion ist im Objekt my_num abgelegt. Dieses Objekt sollte nun auch im Panel oben rechts - spezifischer im Tab Environment - aufgetaucht sein.
Objekte können beliebige Namen tragen - ausgeschlossen ist lediglich, dass die Namen mit einer Zahl beginnen. Generell wird empfohlen, Objekte im sog. snake case zu bezeichnen - also in der Form: name_des_objekts. Die Benennung sollte dabei so kurz und prägnant wie möglich sein. Zwei Objekte können aber niemals den gleichen Namen tragen. Wenn Sie ein zweites Objekt erstellen, dass den gleichen Namen trägt, wird das erste Objekt - ohne Warnung - überschrieben. Um den Inhalt eines Objektes abzurufen, müssen Sie lediglich den Namen des Objektes ausführen:
my_num
## [1] 10
Das ist die Kurzfassung von print(my_num). Das eigentliche Ziel von Objektzuweisungen ist aber, den Inhalt von Objekten an weitere Funktionen weiterreichen zu können.
sqrt(my_num)
## [1] 3.162278
Der Inhalt des Objektes wird so als Argument in die Funktion sqrt() übergeben. Das ist letztlich das Gleiche wie
sqrt(sum(3, 4, 1, 2))
## [1] 3.162278
wo das Ergebnis nicht explizit in einem Objekt gespeichert wird, sondern direkt als Argument an eine Funktion weitergegeben wird. Dabei werden geschachtelte Funktionen von innen nach außen evaluiert. Die Aneinanderkettung von Objektzuweisungen und Schachtelungen ist unbegrenzt, sodass sehr komplexe Systeme entstehen können. Weil das aber sehr schnell anstrengend werden kann - und man dabei leicht den Überblick verliert, was eigentlich wann ausgeführt wird - gibt es noch eine weitere Variante, Funktionen aneinander zu reihen: die Pipe.
Bei der Pipe |> wird ein links stehendes Objekt oder Ergebnis genommen und als erstes Argument der rechts stehenden Funktion eingesetzt. Für unser Wurzelbeispiel also:
sum(3, 4, 1, 2) |> sqrt()
## [1] 3.162278
Das hat den immensen Vorteil, dass wir dadurch unseren Code wieder in der, im westlichen Kulturkreis üblichen Variante wie Text von links nach rechts lesen können. Dabei ist das was als erstes passiert links, das Ergebnis wird nach rechts weitergereicht und irgendetwas passiert damit. Auch dieses System ist theoretisch unendlich fortsetzbar:
sum(3, 4, 1, 2) |> sqrt() |> log()
## [1] 1.151293
Wenn wir unser Ergebnis an ein spezifisches Argument weiterreichen wollen, können wir dafür den Platzhalter _ nutzen:
sum(3, 4, 1, 2) |> sqrt() |> log(x = _)
## [1] 1.151293
Zusammengefasst gibt es also drei Möglichkeiten, um Ergebnisse von Berechnungen in weiteren Schritten weiter zu nutzen:
| Beschreibung | Code-Stil |
|---|---|
| Funktionen schachteln | funktion1(funktion2(argument)) |
| Objekt im Environment anlegen | objekt <- funktion1(argument)funktion2(objekt) |
| Ergebnis-Pipe | funktion1(argument) |> funktion2() |
Wann benutzt man am besten welches dieser drei Systeme? Wie so häufig in R ist das eine Sache des persönlichen Schreibstils und dessen, womit man selbst gut zurecht kommt. Meine persönliche Empfehlung ist für dieses Dreiergespann:
- Ergebnisse sollte man als Objekte ablegen, wenn man das Ergebnis im Verlauf des Skripts noch an mehreren Stellen brauchen wird.
- Funktionen kann man dann schachteln, wenn mehrere verschiedene Argumente erst aus anderen Funktionen erzeugt werden müssen.
- Die Pipe bietet sich wegen der Leserlichkeit in allen anderen Fällen an.
Wenn wir das Ergebnis unseres zweiten Schritts (also wenn wir die Wurzel ziehen), direkt wieder einem Objekt zuweisen, passiert Folgendes:
my_root <- sqrt(my_num)
Im Environment (oben rechts) sollten jetzt zwei Objekte zu erkennen sein. R-intern kann das Environment über den ls()-Befehl betrachtet werden:
ls()
## [1] "figure_path" "my_num" "my_root"
Wenn das Environment sehr voll ist, kann die Ausgabe mit dem Argument pattern = auf spezifische Objekte eingeschränkt werden:
ls(pattern = 'num')
## [1] "my_num"
Objekte können auch einfach aus dem Environment entfernt werden:
rm(my_num)
ls()
## [1] "figure_path" "my_root"
Beachten Sie wieder, dass R ihnen keinerlei Warnung oder Nachfrage gibt, wenn Sie Objekte entfernen. Sollten Sie also Objekte haben, deren Erstellung lange dauert, gehen Sie vorsichtig mit rm() um. Um das Environment gänzlich zu leeren können Sie entweder in RStudio den
![]() Button (im Tab Environment) nutzen oder direkt über die Syntax arbeiten:
Button (im Tab Environment) nutzen oder direkt über die Syntax arbeiten:
rm(list = ls())
Es empfiehlt sich auch hier idealerweise alle Arbeitsschritte mittels Syntax durchzuführen, damit sie dokumentiert und nachvollziehbar sind.
Natürlich können wir die Objekterstellung auch mit der Schachtelung von Befehlen und der Pipe nach Belieben kombinieren. Wenn wir z.B. in drei Schritten ein Ergebnis erzeugen wollen, was wir später noch brauchen könnten, können wir das Ergebnis durch eine Pipe erstellen und dann als Objekt ablegen:
my_num <- sum(3, 4, 1, 2) |> sqrt() |> log()
my_num
## [1] 1.151293
Eine Frage, die R-Studio Ihnen häufig stellt ist, ob sie das Environment speicher wollen, wenn Sie R-Studio schließen. Generell würde ich Ihnen davon abraten. Das hat zwei einfache Gründe:
- Sie halten Ihren Arbeitsplatz (ihr
Environment) aufgeräumt und es fällt ihnen leichter, den Überblick zu behalten, wenn Sie mit einer leeren Umgebung beginnen. - Ihre Syntax bleibt für Andere anwendbar und Ihre Ergebnisse sind reproduzierbar, wenn alles was nötig ist im Skript passiert und Sie sich nicht darauf verlassen müssen, dass bestimmte Dinge schon im Environment liegen.
Gerade 1. kann Ihnen dabei Helfen Fehler zu umgehen, die nur auftreten, weil Sie vor 4 Monaten mal ein Objekt mit einem spezifischen Namen erzeugt haben, was einfach immer noch im gespeicherten Environment rumliegt.
Daten
Um zu verstehen, wie Daten in R funktionieren, nutzen wir als Beispiel ein klassisches Experiment aus der Psychologie: den Stroop Test. Die Grundidee lässt sich am leichtesten in einem Bild darstellen:

Der Stroop-Effekt ist der Unterschied zwischen der durchschnittlichen Zeit, die man benötigt um die Farbe zu nennen, in der ein Wort abgebildet ist - je nachdem ob die Farbe und das Wort gleich sind oder nicht. Wenn Sie über den Stroop Test mehr erfahren möchten, oder ihn selbst mal ausprobieren wollen, finden Sie bei Psytoolkit Informationen und eine Online-Variante des Tests.
Nehmen wir an, Sie hätten für dieses einfache Beispiel die acht Reaktionszeiten gemessen und diese wären (in Millisekunden): 510, 897, 647, 891, 925, 805, 443 und 778. Um diese Daten in R aufzunehmen können Sie folgendes machen:
c() ist eine Funktion mit der alle Argumente (in diesem Fall acht Reaktionszeiten) in ein gemeinsames Objekt zusammengeführt werden. Dieses Objekt ist ein Vektor - eine eindimensionale Datenreihe. Daten können unterschiedliche Formate haben - welches Format vorliegt erfahren wir mit
class(react)
## [1] "numeric"
Wir erfahren also, dass es sich um ein numerisches Objekt handelt. Um ein wenig detailliertere Information zu erhalten können wir str nutzen:
str(react)
## num [1:8] 510 897 647 891 925 805 443 778
Wir erhalten als Ergebnis die Struktur des Objektes. In diesem Fall handelt es sich um ein numerisches (num) Objekt mit Elementen 1 bis 8 ([1:8]) und dem angezeigten Inhalt. Bei großen Objekten werden nicht alle, sondern nur die ersten paar Elemente hier angezeigt.
Im Kern werden in R drei Typen von Vektoren unterschieden:
| Typ | Kurzform | Inhalt |
|---|---|---|
logical | logi | wahr (TRUE) oder falsch (FALSE) |
numeric | num | Beliebige Zahlen |
character | char | Kombinationen aus Zahlen und Buchstaben |
Um die Reaktionszeiten in react interpretieren zu können, müssen sie mit der jeweiligen Farbe, in der ein Wort abgebildet ist, in Verbindung gebracht werden. Dafür bietet sich ein character Vektor an:
color <- c('gruen', 'gelb', 'blau', 'gruen', 'gelb', 'blau', 'rot', 'rot')
Um zu prüfen, ob ein Objekt einen erwarteten Typ hat, können wir vor den Typ-Namen is. schreiben und das als Funktion anwenden:
is.character(color)
## [1] TRUE
Das Präfix as. wandelt dann Vektoren von ihrem bisherigen Typ in den angegebenen Typ um:
as.character(react)
## [1] "510" "897" "647" "891" "925" "805" "443" "778"
as.numeric(color)
## Warning: NAs introduced by coercion
## [1] NA NA NA NA NA NA NA NA
Wie man sieht funktionieren Umwandlungen aber nicht beliebig - in diesem Fall gibt es keine sinnvolle, numerische Repräsentation der Farben (mehr dazu erfahren Sie in der ersten Sitzung der Vorlesung). Wie gerade besprochen fällt R auf, dass hier etwas wahrscheinlich nicht so funktioniert hat, wie wir es wollten und gibt uns dafür ein Warning.
Als dritte Information benötigen wir in unserem Experiment den Text des Wortes:
text <- c('gruen', 'blau', 'blau', 'rot', 'gelb', 'gruen', 'rot', 'gelb')
Die Kernaussage des Stroop-Effekts ist, dass Reaktionszeiten langsamer sind, wenn Farbe und Wort inkongruent sind (also wenn color und text ungleich sind) als wenn sie kongruent sind (wenn color und text gleich sind). Wie zuvor gesehen, können wir logische Operatoren nutzen um diesen Abgleich durchzuführen. Eine der großen Stärken von R ist, dass diese Abgleiche nicht nur funktionieren, wenn wir einzelne Elemente vergleichen, sondern auch, wenn wir ganze Vektoren vergleichen:
cong <- color == text
cong
## [1] TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE
In cong ist das Ergebnis des elementenweisen Vergleichs von color und text enthalten. Wir sehen also, dass das erste Wort kongruent war (gruen == gruen), das zweite Wort inkongruent (gelb != blau) usw. Wir können einfach zeigen, dass es sich hier um einen logischen Vektor handelt:
is.logical(cong)
## [1] TRUE
Eine Sonderform eines Vektors in R ist der factor. Diese Form wird genutzt um nominal- und ordinalskalierte Variablen (mehr dazu in der Vorlesung!) sinnvoll zu speichern. Das wird dadurch erreicht, dass ein factor eigentlich numerisch ist, aber gleichzeitig für jede Zahl ein sog. “Label” vergibt. Den color Vektor, beispielsweise, können wir mit as.factor von einem character in einen factor umwandeln:
color_fac <- as.factor(color)
str(color_fac)
## Factor w/ 4 levels "blau","gelb",..: 3 2 1 3 2 1 4 4
In diesem Fall werden die ursprünglichen Farben in Zahlenwerte übertragen und es wird anhand des Labels ("blau", "gelb", ...) verdeutlicht welche Zahl welche Farbe repräsentiert. Um alle möglichen Ausprägungen (Engl. levels) der Variable zu sehen:
levels(color_fac)
## [1] "blau" "gelb" "gruen" "rot"
Wir sehen also, dass die Variable vier mögliche Ausprägungen hat. Die Zahlen werden entsprechend der Reihenfolge dieser levels vergeben. Bei der Umwandlung eines character Vektors in einen factor werden die levels dabei einfach alphabetisch sortiert. Um diese Abfolge zu ändern, können wir mit relevel() bestimmen, welche Ausprägung den Wert 1 erhalten soll:
relevel(color_fac, 'gruen')
## [1] gruen gelb blau gruen gelb blau rot rot
## Levels: gruen blau gelb rot
Beachten Sie, dass hier - wie immer in R - durch das ausführen der Funktion keine Veränderung am Objekt vorgenommen wird! Wenn wir diese veränderte Variante speichern wollen, müssen wir dafür ein Objekt anlegen (entweder ein Neues oder das Alte überschreiben).
Durch die duale Zuordnung von Zahlen und Labels zum Vektor können factor sehr einfach sowohl in numerische Vektoren, als auch character Vektoren umgewandelt werden:
as.numeric(color_fac)
## [1] 3 2 1 3 2 1 4 4
as.character(color_fac)
## [1] "gruen" "gelb" "blau" "gruen" "gelb" "blau" "rot" "rot"
Wie wir im Verlauf des Semesters sehen werden, haben beide Umwandlungen Konsequenzen für die Berechnungen, die wir durchführen können.
Daten zusammenführen
Im Environment liegen jetzt fünf Vektoren (und unsere Zahl, die wir vor einiger Zeit einzeln abgelegt hatten):
ls()
## [1] "color" "color_fac" "cong" "my_num" "react" "text"
Weil diese Vektoren zusammengehören, wäre es sinnvoll, sie zu einem Objekt zu kombinieren. Wie auch bei Vektoren, gibt es unterschiedliche Typen Daten zu kombinieren, allerdings sind ihre Relationen zueinander ein wenig komplizierter:
| Typ | Dimensionen | Inhalt |
|---|---|---|
matrix | 2 | Vektoren des gleichen Typs |
array | $n$ | Vektoren des gleichen Typs |
data.frame | 2 | Vektoren der gleichen Länge |
list | 1 | Beliebige Objekte |
Die Datentypen werden nach oben restriktiver - sie schränken die Kombinationsmöglichkeiten von Daten ein, werden dabei aber effizienter in der Datenverarbeiten (bezogen auf Rechenkapazitäten). In der Psychologie ist der data.frame die häufigste Variante Daten zu speichern. Besonders bei sehr großen Datensätzen (wie sie z.B. in der modernen neurokognitiven Psychologie entstehen) bietet es sich allerdings an mit matrix zu arbeiten.
Aus der Tabelle lässt sich leicht schließen, dass eine matrix ein Sonderfall eines array ist - Daten werden auf zwei Dimensionen restringiert. Vielleicht weniger eindeutig ist die Beziehung zwischen data.frame und list. Ein data.frame ist der Sonderfall einer list in dem alle Elemente die gleiche Länge haben.
Wir können damit beginnen, eine matrix zu erstellen. Dafür können wir zwei Vektoren des gleichen Typs kombinieren. Im Stroop Beispiel sind color und text beide vom Typ character:
class(color)
## [1] "character"
class(text)
## [1] "character"
class(color) == class(text)
## [1] TRUE
Um die Matrix zu erstellen, können wir entweder direkt den matrix-Befehl nutzen oder eine der beiden bind()-Funktionen benutzen. Um Vektoren als Spalten (Engl. columns) zusammenzuführen, steht cbind() zur Verfügung. Um Vektoren hingegen als Zeilen (Engl. rows) zusammenzuführen, können wir rbind() nutzen. Typischerweise werden psychologische Daten so gehandhabt, dass verschiedene Beobachtungen (z.B. unterschiedliche Personen) in Zeilen und verschiedene Variablen in Spalten abgetragen werden. In unserem Fall haben wir acht Beobachtungen (jeder Vektor ist acht Einträge lang) und zwei Variablen (color und text). Daher sollten wir in diesem Fall mit cbind() arbeiten:
mat <- cbind(color, text)
mat
## color text
## [1,] "gruen" "gruen"
## [2,] "gelb" "blau"
## [3,] "blau" "blau"
## [4,] "gruen" "rot"
## [5,] "gelb" "gelb"
## [6,] "blau" "gruen"
## [7,] "rot" "rot"
## [8,] "rot" "gelb"
Das resultierende Objekt ist eine Matrix:
class(mat)
## [1] "matrix" "array"
Weil Matrizen aber Sonderfälle von Arrays sind, ist dieses Objekt auch ein Array! Was es hingegen nicht ist, ist ein data.frame oder eine list.
is.array(mat)
## [1] TRUE
is.data.frame(mat)
## [1] FALSE
is.list(mat)
## [1] FALSE
Weil in einer matrix nur Vektoren des gleichen Typs kombiniert werden können, führt cbind() dazu, dass Vektoren in den allgemeinsten, gemeinsamen Fall umgewandelt werden, bevor sie als Matrix zusammengeführt werden. Wie wir bereits gesehen haben, sind die “klassischen” Typen von Vektoren in R von spezifisch zu allgemein logical -> numeric -> character. In diesem Fall ist werden also alle Vektoren in character umgewandelt:
mat <- cbind(color, text, cong, react)
mat
## color text cong react
## [1,] "gruen" "gruen" "TRUE" "510"
## [2,] "gelb" "blau" "FALSE" "897"
## [3,] "blau" "blau" "TRUE" "647"
## [4,] "gruen" "rot" "FALSE" "891"
## [5,] "gelb" "gelb" "TRUE" "925"
## [6,] "blau" "gruen" "FALSE" "805"
## [7,] "rot" "rot" "TRUE" "443"
## [8,] "rot" "gelb" "FALSE" "778"
Dadurch verlieren wir aber die Möglichkeit, react als numerische Variable zu nutzen. Das bedeutet, dass wir nach der Umwandlung keine mathematischen Berechnungen (und demzufolge auch nur noch limitierte statistische Analysen) mit der neuen Variable durchführen können. Um die Typen von Vektoren zu erhalten und so Unterschiede im Messniveau zwischen Variablen in den gespeicherten Daten zu berücksichtigen, wird meistens data.frame() genutzt:
dat <- data.frame(color, text, cong, react)
dat
## color text cong react
## 1 gruen gruen TRUE 510
## 2 gelb blau FALSE 897
## 3 blau blau TRUE 647
## 4 gruen rot FALSE 891
## 5 gelb gelb TRUE 925
## 6 blau gruen FALSE 805
## 7 rot rot TRUE 443
## 8 rot gelb FALSE 778
str(dat)
## 'data.frame': 8 obs. of 4 variables:
## $ color: chr "gruen" "gelb" "blau" "gruen" ...
## $ text : chr "gruen" "blau" "blau" "rot" ...
## $ cong : logi TRUE FALSE TRUE FALSE TRUE FALSE ...
## $ react: num 510 897 647 891 925 805 443 778
Wie bereits geschildert, müssen alle Vektoren, die zu einem data.frame zusammengeführt werden die gleiche Länge haben. Wenn wir also einen Vektor erstellen, der nur 3 Einträge hat, können wir keinen gemeinsamen Datensatz erzeugen:
three <- c(1, 2, 3)
data.frame(color, text, cong, react, three)
## Error in data.frame(color, text, cong, react, three): Argumente implizieren unterschiedliche Anzahl Zeilen: 8, 3
Dazu gibt es jedoch eine, sehr spezifische, Ausnahme. Es ist möglich, dass Vektoren unterschiedliche Längen haben, wenn die längere Länge ein Vielfaches der kürzeren Länge ist. Wenn wir also einen Vektor mit 4 Elementen erstellen:
four <- c(three, 4)
data.frame(color, text, cong, react, four)
## color text cong react four
## 1 gruen gruen TRUE 510 1
## 2 gelb blau FALSE 897 2
## 3 blau blau TRUE 647 3
## 4 gruen rot FALSE 891 4
## 5 gelb gelb TRUE 925 1
## 6 blau gruen FALSE 805 2
## 7 rot rot TRUE 443 3
## 8 rot gelb FALSE 778 4
In diesen Fällen wird der kurze Vektor solange wiederholt, bis er genauso lang ist, wie der lange Vektor.
Datenextraktion
Bisher haben wir uns mit dem Zusammenführen von Daten befasst, wie es bei der Datensammlung üblich ist. Bei der Datenauswertung und -inspektion kann es aber genauso wichtig sein, Einzelteile von Datensätzen zu extrahieren.
Der einfachste Fall in R ist die Extraktion eines Elements aus einem Vektor. Dazu können wir noch einmal die Struktur eines Vektors inspizieren:
str(react)
## num [1:8] 510 897 647 891 925 805 443 778
Die [1:8] zeigt uns, wie viele Elemente im Vektor enthalten sind und die Klammern zeigen uns, wie diese Elemente angesprochen werden können:
react[5]
## [1] 925
So erhalten wir das fünfte Element aus dem Vektor. Mit einzelnen Zahlen in den eckigen Klammern können also direkt einzelne Elemente ausgewählt werden. Umgekehrt können auch einzelne Elemente ausgeschlossen werden:
react[-5]
## [1] 510 897 647 891 805 443 778
In den Klammern müssen aber nicht nur einzelne Elemente stehen. Wie beinahe Alles in R, lässt sich eine Funktionsweise einzelner Elemente auch auf ganze Vektoren übertragen. Wir können also einen Selektionsvektor nutzen, um mehrere Elemente auszuwählen:
sel <- c(1, 3, 5)
react[sel]
## [1] 510 647 925
Wie bei allen Dingen, brauchen wir nicht zwingend das Objekt sel anlegen, sondern können Funktionen schachteln:
react[c(1, 3, 5)]
## [1] 510 647 925
Weil es bei großen Datensätzen oder über unterschiedliche Datensätze hinweg selten vorkommt, dass wir spezifische Positionen von relevanten Elementen kennen, können Vektoren auch logisch gefiltert werden. Das bedeutet, dass wir anhand eines logischen Vektors mit der gleichen Länge wie unser Zielvektor über TRUE und FALSE Elemente auswählen können. Einen solchen Vektor haben wir bereits erstellt, nämlich cong der kongruente Farbe-Wort Paare kennzeichnet. Um also alle kongruenten Reaktionszeiten auszuwählen:
react[cong]
## [1] 510 647 925 443
Oder auch das Gegenteil:
react[!cong]
## [1] 897 891 805 778
Weil Vektoren eindimensional sind, benötigen wir zur Auswahl von Elementen nur eine Information. Bei matrix und data.frame sieht das natürlich anders aus. Hier nochmal der zuvor erstellte data.frame:
dat
## color text cong react
## 1 gruen gruen TRUE 510
## 2 gelb blau FALSE 897
## 3 blau blau TRUE 647
## 4 gruen rot FALSE 891
## 5 gelb gelb TRUE 925
## 6 blau gruen FALSE 805
## 7 rot rot TRUE 443
## 8 rot gelb FALSE 778
Er hat also 8 Zeilen und 4 Spalten. Um z.B. die 5. Reaktionszeit auszuwählen, müssen wir das Element in der 5. Zeile und 4. Spalte ansprechen. Bei mehrdimensionalen Objekten werden in R die Dimensionen in eckigen Klammern einfach durch Kommata getrennt:
dat[5, 4]
## [1] 925
In R-Termini nimmt die Auswahlfunktion (die eckigen Klammern) in diesem Fall zwei Argumente entgegen: Zeile und Spalte. Wenn ein Argument ausgelassen wird, ist die Voreinstellung, dass alle Elemente dieser Dimension ausgegeben werden:
dat[1, ] # 1. Zeile, alle Spalten
## color text cong react
## 1 gruen gruen TRUE 510
dat[, 1] # Alle Zeilen, 1. Spalte
## [1] "gruen" "gelb" "blau" "gruen" "gelb" "blau" "rot" "rot"
Wie bei Vektoren, kann die Auswahl wieder über verschiedene Kombinationen aus Auswahlvektoren und einzelnen Elementen erfolgen:
dat[c(2, 3), 3] # 2. und 3. Zeile, 3. Spalte
## [1] FALSE TRUE
dat[cong, ] # Alle kongruenten Zeilen, alle Spalten
## color text cong react
## 1 gruen gruen TRUE 510
## 3 blau blau TRUE 647
## 5 gelb gelb TRUE 925
## 7 rot rot TRUE 443
Um herauszufinden, wie viele Zeilen und Spalten ein Datensatz hat, gibt es die beiden Funktionen:
nrow(dat) # Anzahl der Zeilen
## [1] 8
ncol(dat) # Anzahl der Spalten
## [1] 4
dim(dat) # Alle Dimensionen
## [1] 8 4
In data.frame sind die einzelnen Spalten üblicherweise benannt, weil es sinnvoll ist Variablen spezifische Namen zu geben. Um diese Namen abfragen zu können, gibt es die names() Funktion:
names(dat)
## [1] "color" "text" "cong" "react"
Wenn wir also spezifische Variablen aus einem Datensatz auswählen möchten, können wir diese auch über ihren Namen ansprechen:
dat[, 'react'] # Einzelne Variable auswählen
## [1] 510 897 647 891 925 805 443 778
dat[, c('react', 'cong')] # Mehrere Variable auswählen
## react cong
## 1 510 TRUE
## 2 897 FALSE
## 3 647 TRUE
## 4 891 FALSE
## 5 925 TRUE
## 6 805 FALSE
## 7 443 TRUE
## 8 778 FALSE
Beachten Sie hierbei, dass die Variablennamen in Anführungszeichen stehen müssen, da die Variable sonst als Filtervektor genutzt wird! Als Kurzform für die Auswahl einzelner Variable wird in R häufig das $ genutzt:
dat$react
## [1] 510 897 647 891 925 805 443 778
Daten verändern und hinzufügen
Der Zuweisungspfeil funktioniert auch für Elemente größerer Objekte. Nehmen wir an, wir hätten uns bei der Eingabe der 5. Reaktionszeit vertippt und diese sei eigentlich 725 ms gewesen. Um die vorhandenen Daten zu überschreiben, können wir neue Werte direkt zuweisen. Auch hier sollte beachtet werden, dass es dabei keinerlei Warnung und Absicherung gibt. Sobald die Zuweisung ausgeführt ist, sind die Daten überschrieben und die vorherigen Daten verloren.
dat[5, 'react'] # Aktuellen Inhalt abfragen
## [1] 925
dat[5, 'react'] <- 725 # Aktuellen Inhalt überschreiben
dat[, 'react'] # Alle Reaktionszeiten abfragen
## [1] 510 897 647 891 725 805 443 778
Mit eckigen Klammern und $ können auch Zeilen und Spalten angesprochen werden, die noch nicht existieren. Dieser Ansatz kann z.B. genutzt werden um eine neue Variable zu erstellen. Wenn wir, beispielsweise auch Inkongruenz explizit als Variable im Datensatz aufnehmen wollen, können wir diese Variable direkt erzeugen.
dat$incong <- !dat$cong
dat
## color text cong react incong
## 1 gruen gruen TRUE 510 FALSE
## 2 gelb blau FALSE 897 TRUE
## 3 blau blau TRUE 647 FALSE
## 4 gruen rot FALSE 891 TRUE
## 5 gelb gelb TRUE 725 FALSE
## 6 blau gruen FALSE 805 TRUE
## 7 rot rot TRUE 443 FALSE
## 8 rot gelb FALSE 778 TRUE
Per Voreinstellung werden neue Variablen an die letzte Stelle des Datensatzes aufgenommen. Das Gleiche können wir auch mit neuen Zeilen machen. Hierfür müssen wir eine komplette Zeile mit den korrekten Variablen eingeben.
dat[9, ] <- c('gelb', 'gruen', FALSE, 824, TRUE)
dat
## color text cong react incong
## 1 gruen gruen TRUE 510 FALSE
## 2 gelb blau FALSE 897 TRUE
## 3 blau blau TRUE 647 FALSE
## 4 gruen rot FALSE 891 TRUE
## 5 gelb gelb TRUE 725 FALSE
## 6 blau gruen FALSE 805 TRUE
## 7 rot rot TRUE 443 FALSE
## 8 rot gelb FALSE 778 TRUE
## 9 gelb gruen FALSE 824 TRUE
Um Zeilen oder Spalten aus einem data.frame zu “entfernen” muss eine Kopie des data.frame angelegt werden, in dem dieser Inhalt nicht vorhanden ist. Diese Kopie kann auch genutzt werden um den ursprünglichen data.frame zu überschreiben und so Dinge zu entfernen:
dat <- dat[-9, ] # Datensatz ohne die 9. Zeile
dat
## color text cong react incong
## 1 gruen gruen TRUE 510 FALSE
## 2 gelb blau FALSE 897 TRUE
## 3 blau blau TRUE 647 FALSE
## 4 gruen rot FALSE 891 TRUE
## 5 gelb gelb TRUE 725 FALSE
## 6 blau gruen FALSE 805 TRUE
## 7 rot rot TRUE 443 FALSE
## 8 rot gelb FALSE 778 TRUE
Daten Import/Export
Alle Objekte, die bisher erstellt wurden liegen im Environment - sobald wir R schließen wird dieser geleert und die Objekte gehen verloren. Wie oben bereits erwähnt, ist das in den meisten Fällen das explizit gewünschte Verhalten - durch die Syntax können wir die Objekte ja wiederherstellen - aber in manchen Fällen ist es Sinnvoll Objekte wie Datensätze abzuspeichern und in späteren Schritten die bereits bearbeiteten Daten zu laden.
Um Daten zu laden und zu speichern muss R wissen an welchem Ort nach diesen Daten zu suchen ist. In den meisten Fällen macht es Sinn, für Projekte einen Ordner anzulegen in dem alle relevanten Dateien (z.B. Daten und Syntax) enthalten sind. Dieser Ordner kann R als Working Directory mitgeteilt werden. Das aktuelle Working Directory kann man einfach abrufen:
getwd()
Als Ergebnis sollte ein Ordnerpfad ausgeben werden. Unter Windows hat dieser wahrscheinlich das Format C:/Users/Name/Documents. Um manuell einen anderen Ordner zu nutzen, kann dieser mit setwd() festgelegt werden:
setwd('Pfad/Zum/Ordner')
Windows nutzt \ statt / um Ordner zu strukturieren. Wenn Sie also ihren Zielordner direkt aus der Adresszeile des Ordners kopieren müssen Sie diese Slashes austauschen. Unter OS X oder Linux besteht dieses Problem nicht.
Um sich den Inhalt eines Ordners anzeigen zu lassen (z.B. um zu prüfen, welche Dateien bereits in dem Ordner vorhanden sind):
dir()
R hat zwei eigene Datenformate mit denen Dateien abgespeichert werden können: RDA und RDS.
| Dateiformat | RDA | RDS |
|---|---|---|
| Dateiendung | .rda, .RData | .rds |
| Speichern | save() | saveRDS() |
| Laden | load() | readRDS() |
| Gespeicherte Objekte | Mehrere | Einzeln |
| Ladeverhalten | Objekte werden im Environment wiederhergestellt | Geladene Daten einem neuen Objekt zuweisen |
Generell ist RDS dann zu präferieren, wenn einzelne Objekte (z.B. Datensätze) gespeichert werden und RDA dann, wenn man mehrere Objekte gemeinsam abspeichern möchte. Der Vorteil von RDS ist, dass geladenen Dateien beim Laden ein neuer, in dieser Sitzung nützlicher Name gegeben werden kann. Beim Laden eines RDA werden die Objekte mit den Namen geladen, die sie bei ihrer Erstellung hatten, was zu Konflikten mit bereits im Environment vorhandenen Objekten führen kann (diese werden ohne Vorwarnung überschrieben).
Dieses Verhalten können wir uns im Folgenden anschauen. Zunächst speichern wir den Stroop Datensatz:
save(dat, file = 'dat.rda')
Dann leeren wir das gesamte Environment:
rm(list = ls())
ls()
## character(0)
Wenn wir jetzt den Datensatz laden, wird er mit seiner Originalbenennung (dat) wiederhergestellt:
load('dat.rda')
ls()
## [1] "dat"
Jetzt durchlaufen wir die gleichen Schritte mit dem RDS Format:
saveRDS(dat, 'dat.rds')
rm(list = ls())
ls()
## character(0)
Beim Laden des Datensatzes können wir diesen jetzt einem beliebigen Objekt zuweisen:
stroop <- readRDS('dat.rds')
stroop
## color text cong react incong
## 1 gruen gruen TRUE 510 FALSE
## 2 gelb blau FALSE 897 TRUE
## 3 blau blau TRUE 647 FALSE
## 4 gruen rot FALSE 891 TRUE
## 5 gelb gelb TRUE 725 FALSE
## 6 blau gruen FALSE 805 TRUE
## 7 rot rot TRUE 443 FALSE
## 8 rot gelb FALSE 778 TRUE
Dieses Verhalten ist konsistent mit dem Verhalten von anderen Funktionen zum Datenimport. R kann mithilfe verschiedener Funktionen eine Vielzahl unterschiedlicher Datenformate einlesen. Zwei sehr typische - Klartextformate (.txt oder .dat) und CSV (.csv) - können über die Funktionen read.table() und read.csv() eingelesen werden. Genaugenommen ist dabei read.csv() nur eine Abwandlung von read.table() mit anderen Voreinstellungen für die gleichen Argumente, sodass wir hier nur die read.table() Funktion betrachten werden.
Daten aus dem Fragebogen
Die Daten aus der Befragung, die Sie letzte Woche ausgefüllt haben finden Sie hier. Diese liegen im CSV Format vor und die Datei heißt fb25.csv. Beachten Sie, dass der Datensatz durch die Befragung anhand von SoSciSurvey eigentlich auch im R-Datenformat .rda vorliegt. Da Sie sich jedoch nicht sicher sein können, ob Sie in Zukunft immer eine Datei mit diesem Format verwenden werden, besprechen wir auch das Einlesen von anderen Formaten. Mit read.table() können wir den CSV Datensatz laden, müssen aber bestimmte Eigenheiten des Datensatzes bedenken. Wenn Sie den Datensatz mit einem Text-Editor öffnen sehen die ersten 5 Zeilen folgendermaßen aus:
## "mdbf1","mdbf2","mdbf3","mdbf4","mdbf5","mdbf6","mdbf7","mdbf8","mdbf9","mdbf10","mdbf11","mdbf12","time_pre","lz","extra","vertr","gewis","neuro","offen","prok","trust","uni1","uni2","uni3","uni4","sicher","angst","fach","ziel","wissen","therap","lerntyp","hand","job","ort","ort12","wohnen","attent_pre","gs_post","wm_post","ru_post","time_post","attent_post"
## 3,3,1,1,1,3,1,3,1,3,1,3,43,5,3.5,4,2.5,2,2.5,2.6,3.33333333333333,0,1,1,0,3,2,4,2,NA,NA,3,2,2,1,2,3,4,3,3.25,2.25,18,5
## 3,2,2,2,2,2,3,3,3,3,2,2,55,3,4,3,4.5,2,4.5,2.5,3.83333333333333,0,1,0,0,4,2,4,2,3,5,3,2,1,2,3,2,5,NA,NA,NA,NA,NA
## 3,3,2,2,2,3,2,3,2,2,2,2,79,5,2.5,4,3.5,3,4.5,2.8,3.83333333333333,1,1,0,0,4,3,4,2,5,5,3,2,2,2,1,3,4,2.75,2.75,2.25,71,5
## 4,1,3,1,2,1,3,4,2,1,1,3,53,6,4,3,4.5,4,5,3,3.66666666666667,0,1,1,0,4,4,4,2,NA,NA,3,2,2,1,3,1,5,3.25,3.25,2.75,17,5
Die Art in der dieser Datensatz aufbereitet ist, muss R mitgeteilt werden, damit wir ihn ordentlich einlesen können. Es empfiehlt sich dafür mit help(read.table) die Hilfe zu öffnen. Was diese Hilfe verrät sind unter Anderem die Argumente, die die Funktion entgegennimmt:
args(read.table)
## function (file, header = FALSE, sep = "", quote = "\"'", dec = ".",
## numerals = c("allow.loss", "warn.loss", "no.loss"), row.names,
## col.names, as.is = !stringsAsFactors, tryLogical = TRUE,
## na.strings = "NA", colClasses = NA, nrows = -1, skip = 0,
## check.names = TRUE, fill = !blank.lines.skip, strip.white = FALSE,
## blank.lines.skip = TRUE, comment.char = "#", allowEscapes = FALSE,
## flush = FALSE, stringsAsFactors = FALSE, fileEncoding = "",
## encoding = "unknown", text, skipNul = FALSE)
## NULL
Das einzige Argument ohne Voreinstellung ist file, also der Dateiname. Wenn wir den Datensatz mit Voreinstellungen laden, erhalten wir folgenden Fehler:
fb25 <- read.table('fb25.csv')
## Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, : line 2 did not have 2 elements
Das liegt in diesem Fall daran, dass read.table() als Voreinstellung annimmt, dass die erste Zeile der Datei nicht besonders ist (header = FALSE). In unserem Fall enthält diese Zeile aber die Namen der Variablen, sodass wir diese Einstellung ändern müssen:
fb25 <- read.table('fb25.csv', header = TRUE)
## Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, : line 1 did not have 2 elements
Wieder ergibt sich ein Fehler, der lamentiert, dass es mehr Spalten als Variablennamen gibt. Das liegt daran, dass read.table() per Voreinstellung davon ausgeht, dass Variablen (bzw. Spalten des Datensatzes) durch Leerzeichen getrennt sind (sep = ""). In unserer Datei erfolgt das aber durch Kommata.
fb25 <- read.table('fb25.csv', header = TRUE, sep = ",")
Im Environment erscheint jetzt das Objekt fb25. Mit head() können wir uns den Kopf des Datensatzes (die ersten 6 Zeilen) anzeigen lassen:
head(fb25) # Kopfzeilen
## mdbf1 mdbf2 mdbf3 mdbf4 mdbf5 mdbf6 mdbf7 mdbf8 mdbf9 mdbf10 mdbf11 mdbf12 time_pre lz extra vertr gewis neuro offen prok
## 1 3 3 1 1 1 3 1 3 1 3 1 3 43 5.0 3.5 4.0 2.5 2 2.5 2.6
## 2 3 2 2 2 2 2 3 3 3 3 2 2 55 3.0 4.0 3.0 4.5 2 4.5 2.5
## 3 3 3 2 2 2 3 2 3 2 2 2 2 79 5.0 2.5 4.0 3.5 3 4.5 2.8
## 4 4 1 3 1 2 1 3 4 2 1 1 3 53 6.0 4.0 3.0 4.5 4 5.0 3.0
## 5 4 3 1 1 1 3 2 4 1 3 1 3 28 5.8 4.5 2.0 3.0 4 4.5 2.5
## 6 3 3 1 1 1 2 2 3 4 3 1 2 35 5.2 3.0 4.5 3.5 5 4.5 2.9
## trust uni1 uni2 uni3 uni4 sicher angst fach ziel wissen therap lerntyp hand job ort ort12 wohnen attent_pre gs_post wm_post
## 1 3.333333 0 1 1 0 3 2 4 2 NA NA 3 2 2 1 2 3 4 3.00 3.25
## 2 3.833333 0 1 0 0 4 2 4 2 3 5 3 2 1 2 3 2 5 NA NA
## 3 3.833333 1 1 0 0 4 3 4 2 5 5 3 2 2 2 1 3 4 2.75 2.75
## 4 3.666667 0 1 1 0 4 4 4 2 NA NA 3 2 2 1 3 1 5 3.25 3.25
## 5 3.666667 0 1 0 0 4 3 4 2 NA NA 1 2 1 2 2 4 5 3.00 2.75
## 6 4.166667 0 1 1 0 3 3 4 2 NA NA 3 2 1 1 2 3 5 3.25 3.25
## ru_post time_post attent_post
## 1 2.25 18 5
## 2 NA NA NA
## 3 2.25 71 5
## 4 2.75 17 5
## 5 2.25 21 5
## 6 2.50 51 5
str(fb25) # Struktur des Datensatzes
## 'data.frame': 211 obs. of 43 variables:
## $ mdbf1 : int 3 3 3 4 4 3 3 3 2 3 ...
## $ mdbf2 : int 3 2 3 1 3 3 3 2 3 2 ...
## $ mdbf3 : int 1 2 2 3 1 1 1 1 3 3 ...
## $ mdbf4 : int 1 2 2 1 1 1 1 1 1 2 ...
## $ mdbf5 : int 1 2 2 2 1 1 1 3 2 3 ...
## $ mdbf6 : int 3 2 3 1 3 2 1 3 4 2 ...
## $ mdbf7 : int 1 3 2 3 2 2 2 4 2 3 ...
## $ mdbf8 : int 3 3 3 4 4 3 3 3 3 3 ...
## $ mdbf9 : int 1 3 2 2 1 4 2 1 3 4 ...
## $ mdbf10 : int 3 3 2 1 3 3 2 2 3 3 ...
## $ mdbf11 : int 1 2 2 1 1 1 2 1 3 2 ...
## $ mdbf12 : int 3 2 2 3 3 2 2 3 2 1 ...
## $ time_pre : int 43 55 79 53 28 35 44 29 30 52 ...
## $ lz : num 5 3 5 6 5.8 5.2 4.6 4.8 6.8 2.6 ...
## $ extra : num 3.5 4 2.5 4 4.5 3 2.5 2.5 3.5 2 ...
## $ vertr : num 4 3 4 3 2 4.5 2.5 4 3 2.5 ...
## $ gewis : num 2.5 4.5 3.5 4.5 3 3.5 2.5 2 4 5 ...
## $ neuro : num 2 2 3 4 4 5 4.5 1 4.5 5 ...
## $ offen : num 2.5 4.5 4.5 5 4.5 4.5 3.5 4 5 4.5 ...
## $ prok : num 2.6 2.5 2.8 3 2.5 2.9 3 3.4 3.2 2.7 ...
## $ trust : num 3.33 3.83 3.83 3.67 3.67 ...
## $ uni1 : int 0 0 1 0 0 0 0 0 0 1 ...
## $ uni2 : int 1 1 1 1 1 1 1 1 1 1 ...
## $ uni3 : int 1 0 0 1 0 1 0 0 0 0 ...
## $ uni4 : int 0 0 0 0 0 0 0 1 0 1 ...
## $ sicher : int 3 4 4 4 4 3 NA 3 4 3 ...
## $ angst : int 2 2 3 4 3 3 2 2 2 4 ...
## $ fach : int 4 4 4 4 4 4 4 2 2 2 ...
## $ ziel : int 2 2 2 2 2 2 2 1 1 3 ...
## $ wissen : int NA 3 5 NA NA NA 4 NA 3 5 ...
## $ therap : int NA 5 5 NA NA NA 5 NA 5 4 ...
## $ lerntyp : int 3 3 3 3 1 3 1 3 2 1 ...
## $ hand : int 2 2 2 2 2 2 2 2 1 2 ...
## $ job : int 2 1 2 2 1 1 1 1 2 2 ...
## $ ort : int 1 2 2 1 2 1 1 2 2 1 ...
## $ ort12 : int 2 3 1 3 2 2 2 1 1 1 ...
## $ wohnen : int 3 2 3 1 4 3 1 2 4 1 ...
## $ attent_pre : int 4 5 4 5 5 5 5 5 5 4 ...
## $ gs_post : num 3 NA 2.75 3.25 3 3.25 NA 3 2.75 2.25 ...
## $ wm_post : num 3.25 NA 2.75 3.25 2.75 3.25 NA 2.25 1.75 2.25 ...
## $ ru_post : num 2.25 NA 2.25 2.75 2.25 2.5 NA 2 2 2.75 ...
## $ time_post : int 18 NA 71 17 21 51 NA 31 27 34 ...
## $ attent_post: int 5 NA 5 5 5 5 NA 5 5 5 ...
Wir können den Datensatz übrigens auch direkt von der Website in R laden. Das file-Argument nimmt auch direkt URLs entegegen:
fb25 <- read.table('https://pandar.netlify.app/daten/fb25.csv', header = TRUE, sep = ",")
so kann umgangen werden, dass wir die gleiche Datei immer und überall lokal speichern müssen, obwohl wir eine zentrale, online verfügbare Datei nutzen.
Gegenspieler von read.table() ist write.table() mit dem Daten im Klartextformat gespeichert werden können. Um den Datensatz als .txt-Datei abzuspeichern können wir Folgendes nutzen:
write.table(fb25, # zu speichernder Datensatz
'fb25.txt' # Dateiname
)
Diese Datei entspricht den Voreinstellungen von write.table(). Daher sehen die ersten 5 Zeilen in einem Text-Editor jetzt so aus:
## "mdbf1" "mdbf2" "mdbf3" "mdbf4" "mdbf5" "mdbf6" "mdbf7" "mdbf8" "mdbf9" "mdbf10" "mdbf11" "mdbf12" "time_pre" "lz" "extra" "vertr" "gewis" "neuro" "offen" "prok" "trust" "uni1" "uni2" "uni3" "uni4" "sicher" "angst" "fach" "ziel" "wissen" "therap" "lerntyp" "hand" "job" "ort" "ort12" "wohnen" "attent_pre" "gs_post" "wm_post" "ru_post" "time_post" "attent_post"
## "1" 3 3 1 1 1 3 1 3 1 3 1 3 43 5 3.5 4 2.5 2 2.5 2.6 3.33333333333333 0 1 1 0 3 2 4 2 NA NA 3 2 2 1 2 3 4 3 3.25 2.25 18 5
## "2" 3 2 2 2 2 2 3 3 3 3 2 2 55 3 4 3 4.5 2 4.5 2.5 3.83333333333333 0 1 0 0 4 2 4 2 3 5 3 2 1 2 3 2 5 NA NA NA NA NA
## "3" 3 3 2 2 2 3 2 3 2 2 2 2 79 5 2.5 4 3.5 3 4.5 2.8 3.83333333333333 1 1 0 0 4 3 4 2 5 5 3 2 2 2 1 3 4 2.75 2.75 2.25 71 5
## "4" 4 1 3 1 2 1 3 4 2 1 1 3 53 6 4 3 4.5 4 5 3 3.66666666666667 0 1 1 0 4 4 4 2 NA NA 3 2 2 1 3 1 5 3.25 3.25 2.75 17 5