](/media/header/jar_potpourri.jpg)
In diesem Beitrag geben wir eine kurze Übersicht über einige gängige Plotarten mit den Beispielen, die wir schon behandelt haben oder noch behandeln werden. Um die Navigation ein wenig zu vereinfachen, hier eine Tabelle:
| 1 | Balkendiagramm I |
| 2 | Balkendiagramm II |
| 3 | Histogramm |
| 4 | Boxplot |
| 5 | Violin Plot |
| 6 | Ridgelines |
| 7 | Torten und Donuts |
| 8 | Bubble Chart |
| 9 | Karten |
| 10 | Wordcloud |
Balkendiagramm
Die digiGEBF hatte zur Teilnahme an einer Data Challenge aufgerufen. Die Ergebnisse sind hier einsehbar: https://www.digigebf21.de/frontend/index.php?page_id=17723.
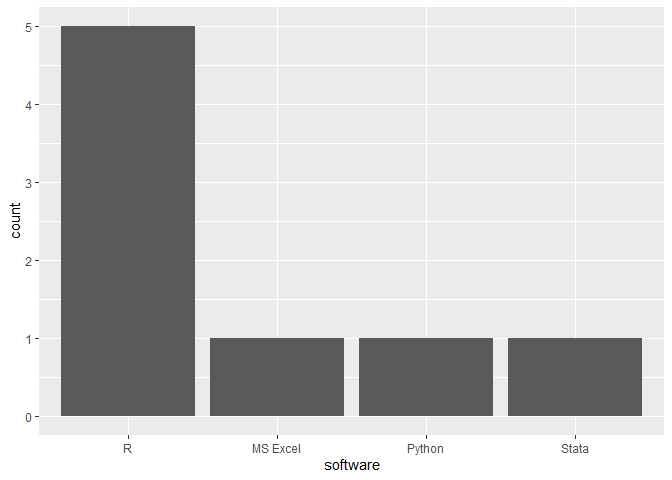
Jeder Beitrag wurde durch die einreichende Person kommentiert und dokumentiert. So lässt sich nachvollziehen, mit welcher Software die Grafiken erzeugt wurden. Dabei zeigt sich folgendes Bild:
| Software | Anzahl |
|---|---|
| R | 5 |
| MS Excel | 1 |
| Python | 1 |
| STATA | 1 |
Diese Ergebnisse lassen sich mit einem Balkendiagramm visualiseren.
Da uns hier bereits die Ergebnisse so vorliegen, wie sie abgebildet werden sollen (als Höhe der Balken), verwenden wir die Funktion geom_col(). (Lägen uns Rohdaten vor, deren Häufigkeit zunächst ausgezählt werden muss, um sie als Höhe der Balken darzustellen, würde man geom_bar() verwenden.)
# Pakete laden
library(ggplot2)
# Datensatz erstellen
df <- data.frame(software = factor(x = c("R", "MS Excel", "Python", "Stata"),
levels = c("R", "MS Excel", "Python", "Stata")),
count = c(5,1,1,1))
# Einfaches Balkendiagramm
ggplot(df, aes(x=software, y=count)) +
geom_col()
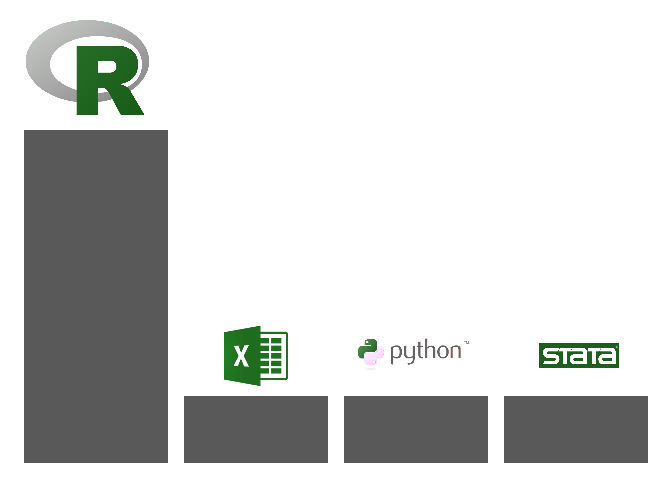
Diese Darstellung lässt sich noch optimieren. Statt der Achsenbeschriftung beschriften wir die Balken selbst mit dem Logo der Software! Zum Einlesen der Bilddateien nutzen wir das Paket magick, zur Integration von Bilddateien in ggplots kann das Paket cowplot verwendet werden.
library(magick)
library(cowplot)
# Software-Logos herunterladen und einlesen (Funktion aus dem Paket magick)
r <- image_read("https://www.r-project.org/logo/Rlogo.svg")
excel <- image_read("https://upload.wikimedia.org/wikipedia/commons/8/8d/Microsoft_Excel_Logo_%282013-2019%29.svg")
python <- image_read("https://upload.wikimedia.org/wikipedia/commons/f/f8/Python_logo_and_wordmark.svg")
stata <- image_read("https://upload.wikimedia.org/wikipedia/commons/5/5c/Stata_Logo.svg")
# ggplot-Befehl zur Erstellung der "nackten" Grafik
ggplot(df, aes(x=software, y=count)) +
geom_col() +
theme_void() +
labs(x="", y="") +
theme(plot.margin = unit(c(3,0,0,0), "cm"),
axis.text.y = element_blank(),
axis.line.y = element_blank(),
axis.ticks.y = element_blank()) -> plot
# Positionieren der Bilddateien auf den Balken (Paket cowplot)
ggdraw(plot) +
draw_image(r, x = .13, y = .86, scale = .2, hjust = .5, vjust = .5) +
draw_image(excel, x = .38, y = .26, scale = .14, hjust = .5, vjust = .5) +
draw_image(python, x = .62, y = .26, scale = .18, hjust = .5, vjust = .5) +
draw_image(stata, x = .86, y = .26, scale = .12, hjust = .5, vjust = .5) +
scale_fill_manual(values = c(rgb(102,153,204, max=255), "grey", "grey", "grey")) +
draw_plot(plot)
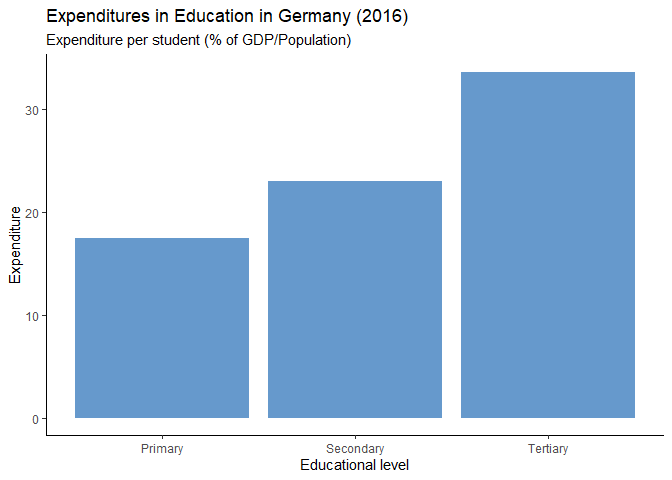
Noch ein Balkendiagramm
Es soll ein Vergleich angestellt werden, wie hoch die Ausgaben in Deutschland im Jahr 2016 für die unterschiedlichen Bildungsbereiche (Primar, Sekundar, Tertiär) waren. Dafür eignet sich ein Balkendiagramm. Die Daten müssen jedoch noch umstrukturiert werden, bevor sie mit ggplot dargestellt werden können, da sie aktuell im Datensatz “nebeneinander” stehen - es handelt sich ja um drei verschiedene Variablen - der Densatz ist wide. Er muss zunächst in eine saubere (tidy) Form gebracht werden, sodass alle Werte, die dargestellt werden, in einer einzigen Variable stehen. Dafür bringen wir den Datensatz in die “Lang-Version” (long):
# original-Datensatz mit relevanten Variablen: wide
edu_exp |>
subset(edu_exp$Country == "Germany" & edu_exp$Year == 2016,
select = c("Country", "Year", "Primary", "Secondary", "Tertiary"))
## Country Year Primary Secondary Tertiary
## 988 Germany 2016 17.44257 22.95939 33.58129
# Umstrukturierung in die long-Form
edu_exp_long <- edu_exp |>
subset(edu_exp$Country == "Germany" & edu_exp$Year == 2016,
select = c("Country", "Year", "Primary", "Secondary", "Tertiary")) |>
reshape(direction = "long",
varying = c("Primary", "Secondary", "Tertiary"),
times = c("Primary", "Secondary", "Tertiary"),
v.name = "value",
timevar = "exp")
edu_exp_long
## Country Year exp value id
## 1.Primary Germany 2016 Primary 17.44257 1
## 1.Secondary Germany 2016 Secondary 22.95939 1
## 1.Tertiary Germany 2016 Tertiary 33.58129 1
Hat geklappt. Die Daten liegen uns nun also wieder genau so vor, wie sie dargestellt werden sollen (als Höhe der Balken). In diesem Fall kann geom_col() verwendet werden (siehe Beispiel oben). Es kann aber auch geom_bar() in Kombination mit dem Argument stat="idendity" verwendet werden - so weiß ggplot, dass die Daten nicht (wie per Default in geom_bar()) ausgezählt, sondern direkt übernommen werden können.
edu_exp_long |>
ggplot(aes(x=exp, y=value)) +
geom_bar(stat = "identity", fill = rgb(102, 153, 204, max=255)) +
labs(x = "Educational level",
y = "Expenditure",
title ="Expenditures in Education in Germany (2016)",
subtitle = "Expenditure per student (% of GDP/Population)") +
theme_classic()
Histogramm
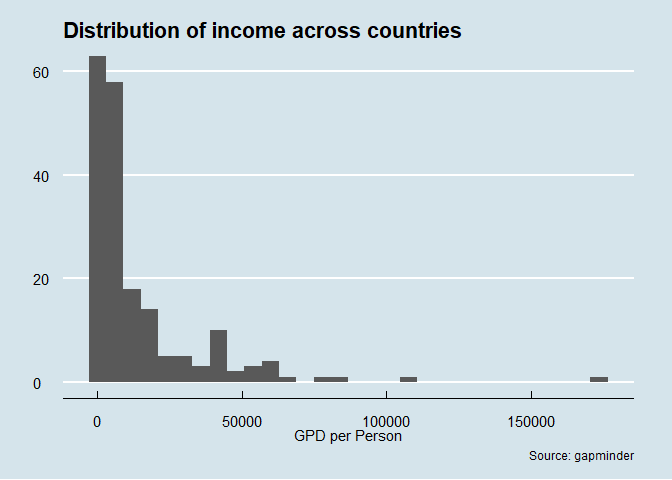
Die Verteilung des Einkommens (GDP/Person) soll für das Jahr 2016 dargestellt werden. Es handelt sich um eine kontinuierliche Variable, so bietet sich ein Histogramm an. Für Histogramme kann die Funktion geom_histogram() verwendet werden. Wir kombinieren sie mit dem Theme theme_economist aus dem Paket ggthemes.
library(ggthemes)
##
## Attache Paket: 'ggthemes'
## Das folgende Objekt ist maskiert 'package:cowplot':
##
## theme_map
edu_exp |>
subset(edu_exp$Year == 2016) |>
ggplot(aes(x = Income)) +
geom_histogram() +
labs(x = "GPD per Person",
y = "",
title ="Distribution of income across countries",
caption = "Source: gapminder") +
theme_economist() +
theme(plot.margin = unit(c(0.5,1,0.5,0.5), "cm"))
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
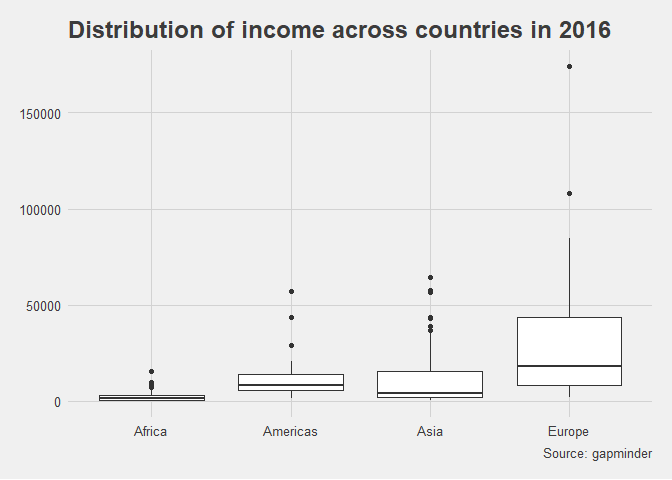
Boxplot
Erneut soll die Verteilung des Einkommens (GDP/Person) für das Jahr 2016 dargestellt werden - diesmal jedoch separat nach Weltregion. Eine alternative Darstellung für Verteilungen ist das Boxplot. Es lässt sich per geom_boxplot() anfordern. Wir hinterlegen über aes(x=Region), dass eine Box pro Weltregion erzeugt wird. Diese Boxen werden dann nebeneinander dargestellt und ein Vergleich ist leicht möglich.
Die Grafik wird mit dem Theme theme_fivethirtyeight aus dem Paket ggthemes angepasst.
library(ggthemes)
edu_exp |>
subset(edu_exp$Year == 2016) |>
ggplot(aes(x = Region, y = Income)) +
geom_boxplot() +
labs(x = "GPD per Person",
y = "",
title ="Distribution of income across countries in 2016",
caption = "Source: gapminder") +
scale_x_discrete(labels = c("Africa", "Americas", "Asia", "Europe")) +
theme_fivethirtyeight()
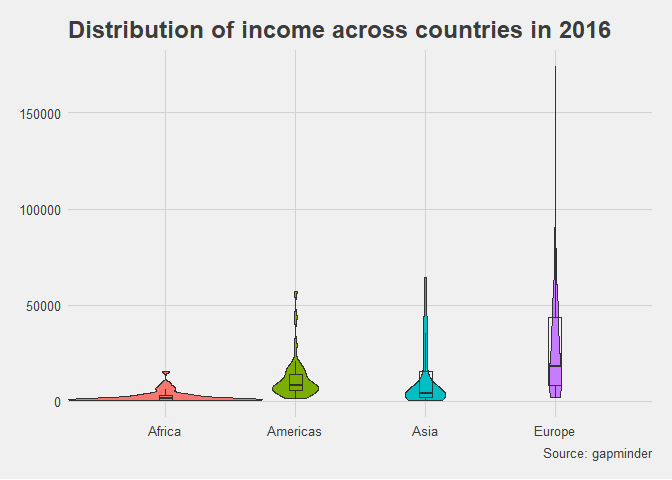
Violin Plot
Für das gleiche Datenbeispiel wie im Boxplot oben (Verteilung des Einkommens (GDP/Person) für das Jahr 2016 separat nach Weltregion) fordern wir nun ein sog. Violin Plot an. Anstelle der Quartile wird die Dichte der Verteilung direkt dargestellt. Auch hier sind die Weltregionen nebeneinander dargestellt (aes(x=Region)), sodass ein Vergleich sehr leicht möglich ist. Das entsprechende Layer wird mit geom_violin angefordert. Zusätzlich werden schmale Boxplots eingezeichnet.
Die Grafik wird ebenfalls mit dem Theme theme_fivethirtyeight aus dem Paket ggthemes angepasst.
library(ggthemes)
edu_exp |>
subset(edu_exp$Year == 2016) |>
ggplot(aes(x = Region, y = Income)) +
geom_violin(aes(fill = Region), width = 1.5, show.legend = FALSE) +
# geom_jitter(width = .1, height = 0, col = "grey") +
geom_boxplot(width = .1, fill = "transparent", outlier.shape = NA) +
labs(x = "GPD per Person",
y = "",
title ="Distribution of income across countries in 2016",
caption = "Source: gapminder") +
scale_x_discrete(labels = c("Africa", "Americas", "Asia", "Europe")) +
theme_fivethirtyeight()
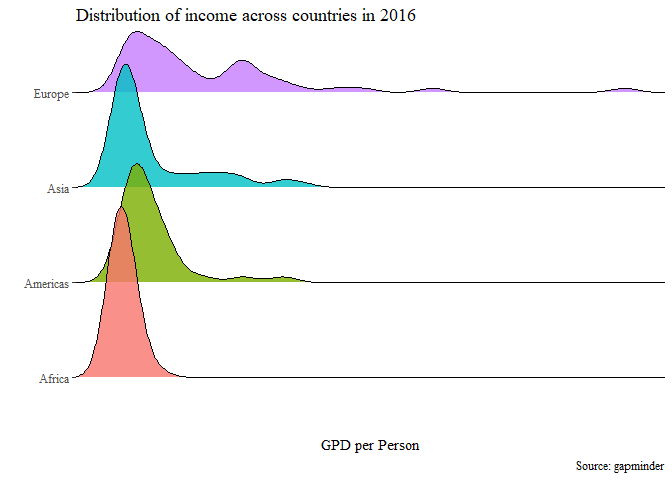
Ridgeline Plot
Für das gleiche Datenbeispiel wie im Boxplot und Violin Plot oben (Verteilung des Einkommens (GDP/Person) für das Jahr 2016 separat nach Weltregion) fordern wir nun ein sog. Ridgleline Plot mit geom_density_ridges() aus dem Paket ggridges an. Auch hier wird die Dichte der Verteilung dargestellt. Die Gruppen sind nun übereinander dargestellt (aes(y=Region). Auch dadurch ist ein Vergleich leicht möglich.
Die Grafik wird mit dem Theme theme_tufte aus dem Paket ggthemes angepasst.
library(ggthemes)
library(ggridges)
edu_exp |>
subset(edu_exp$Year == 2016) |>
ggplot(aes(x = Income, y = Region)) +
geom_density_ridges(aes(fill = Region), alpha=.8, show.legend = FALSE) +
scale_y_discrete(labels = c("Africa", "Americas", "Asia", "Europe")) +
labs(x = "GPD per Person",
y = "",
title ="Distribution of income across countries in 2016",
caption = "Source: gapminder") +
scale_x_discrete(labels = c("Africa", "Americas", "Asia", "Europe")) +
theme_tufte()
## Picking joint bandwidth of 4590
Torten und Donuts
Bevor wir uns damit befassen, wie man in ggplot2 ein Torten-Diagramm erstellen kann (und die Donut-förmige Abwandlung davon) wird in vielen Ecken des Internets die Frage nach dem ob man ein Torten-Diagramm erstellen sollte mit einem vehementen “nein” beantwortet (es gibt auch wissenschaftliche Untersuchungen, die zeigen, dass Daten undeutlicher vermittelt werden). Dennoch werden beide Arten von Plots gerne und häufig genutzt und haben in einigen Fällen ihre Anwendungsgebiete. Im normalen R können wir pie() nutzen, um ein Tortendiagramm anzulegen, in ggplot2 ist das allerdings ein wenig umständlicher.
Generell werden Tortendiagramme nur dann empfohlen, wenn man Anteile von einem Gesamten darstellen möchte. Leider haben wir keine dafür direkt geeignete Variable in unserem Datensatz, aber wir können uns etwas erstellen. Wir betrachten im Folgenden die Ausgaben für die drei unterschiedlichen Bildungsbreiche und wie diese in unterschiedlichen Ländern aussehen. Dafür erstellen wir zunächst Proportionen:
edu_exp$Total <- subset(edu_exp, select = c('Primary', 'Secondary', 'Tertiary')) |>
rowSums()
tmp <- edu_exp[, c('Primary', 'Secondary', 'Tertiary')] / edu_exp$Total
names(tmp) <- c('PrimaryProp', 'SecondaryProp', 'TertiaryProp')
edu_exp <- cbind(edu_exp, tmp)
Wie immer, nehmen wir 2013 und beschränken uns auf die Länder, die in diesem Jahr für alle drei Ausgaben Daten vorhanden haben. Wie wir schon im ersten Beitrag gesehen haben, müssen wir die Daten mehrerer Variablen für die ordentliche Darstellung ins lange Format übertragen.
prop_long <- subset(edu_exp, Year == 2013 & !is.na(Total),
select = c('Country', 'Year',
'PrimaryProp', 'SecondaryProp', 'TertiaryProp')) |>
reshape(direction = 'long',
varying = c('PrimaryProp', 'SecondaryProp', 'TertiaryProp'),
v.names = 'Proportion',
timevar = 'Type',
times = c('Primary', 'Secondary', 'Tertiary'))
geom_rect() ist der Umweg über den wir uns in ggplot2 an das Kreisdiagramm heranpirschen müssen. Dafür benötigen wir klare Enden unserer Rechtecke, also bei welchen y-Werten die Balken anfangen und aufhören sollen. Weil die Balken ja bündig einen Kreis ergeben sollen, brauchen wir erstmal auch einen bündigen Balken, das heißt jede Kategorie muss das aufhören, wo die nächste beginnt. Damit wir das nicht gleichzeitig und unübersichtlich für alle Länder gleicheztig machen, beschränken wir uns wieder auf Spanien:
spain <- subset(prop_long, Country == 'Spain')
spain$Max <- cumsum(spain$Proportion)
spain$Min <- c(0, head(spain$Max, n = -1))
spain
## Country Year Type Proportion id Max Min
## 26.Primary Spain 2013 Primary 0.2966316 26 0.2966316 0.0000000
## 26.Secondary Spain 2013 Secondary 0.3113845 26 0.6080161 0.2966316
## 26.Tertiary Spain 2013 Tertiary 0.3919839 26 1.0000000 0.6080161
Mit geom_rect() können wir jetzt einen Balken erstellen, der genau bündig von einem Bildungstyp in den nächsten übergeht:
bar <- ggplot(spain,
aes(ymin = Min, ymax = Max,
xmin = 2, xmax = 3,
fill = Type)) +
geom_rect(color = 'white') +
theme_void() + scale_fill_pandar()
bar

Wir nutzen statt des theme_pandar() hier theme_void(), um den Plot von Achsen und anderen Kennzeichnungen zu befreien. color = 'white' setze ich hier, um eine sauber aussehende Grenze zwischen den Abschnitten herzustellen.
Jetzt müssen wir aus diesem Türmchen nur noch einen Kreis formen. Dafür transformieren wir die Koordinaten ins polare System, sodass (0, 0) in der Mitte liegt und sich die Datenpunkte von dort entfernen:
pie <- bar + coord_polar("y")
pie
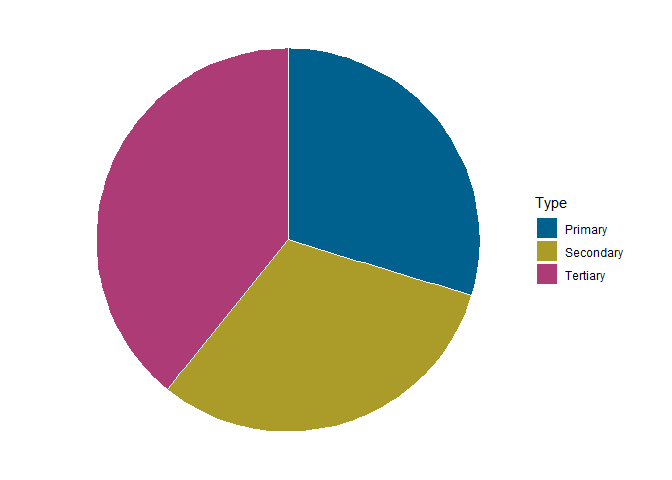
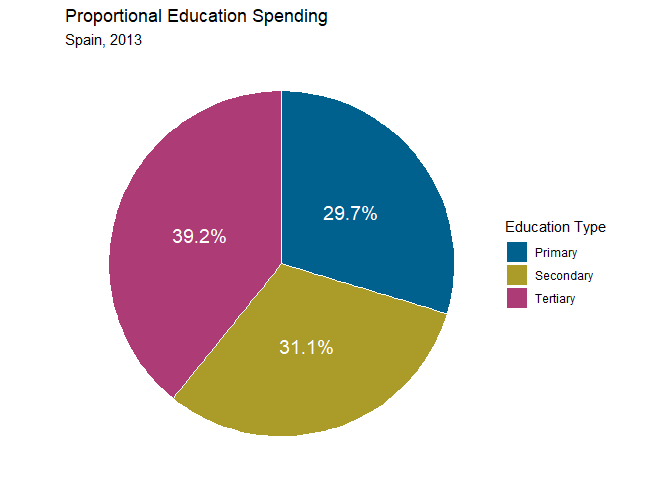
Jetzt können wir über geom_text noch die Prozente in die Abschnitte eintragen. Dabei müssen wir nur ordentliche Positionen für die Labels bestimmen. Ich setze diese einfach mal in die Mitte. Danach erzeugen wir noch die Prozentzahlen und pasten sie mit dem Prozentzeichen zusammen. Das sollte für unsere Label genügen.
spain$Position <- (spain$Max + spain$Min) / 2
spain$Percent <- paste0(round(spain$Proportion * 100, 1), '%')
Weil wir Änderungen an den Daten vorgenommen haben, müssen wir den neuen Datensatz direkt über das data-Argument ansprechen (sonst wüsste geom_text() nichts von den neuen Variablen)
pie <- pie +
geom_text(data = spain, x = 2.5,
aes(y = Position, label = Percent),
color = 'white', size = 5) +
labs(fill = 'Education Type') +
ggtitle('Proportional Education Spending', 'Spain, 2013')
pie
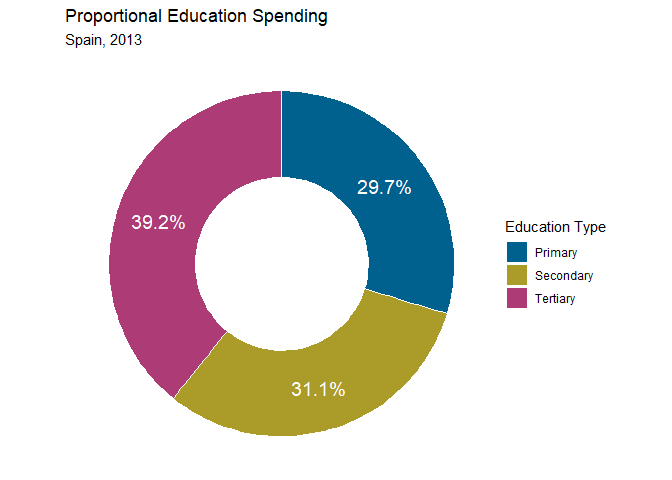
Um aus diesem Kuchen jetzt einen Donut zu machen, müssen wir nur das mittlere Stück herausnehmen, indem wir die x-Achse in eine Region erweitern, in die unser geom_rect() nicht reicht.
pie + xlim(c(1, 3))
Bubble Chart
In Übung 1 sollten Sie diese auf gapminder.org erzeugte Grafik nachbasteln:

Die Variablen liegen alle im edu_exp-Datensatz vor. Allerdings sieht die ggplot-Grafik ohne Anpassungen wie folgt aus:
edu_exp |>
subset(Year == 2015) |>
ggplot(aes(x=Income, y=Expectancy)) +
geom_point()
Zunächst wird der Datensatz noch so sortiert, dass kleine Länder “hinten” stehen und “zuletzt” ins Plot kommen, also vorne (unverdeckt) zu sehen sind. Außerdem hinterlege ich schon mal die vier Farben als rgb-Vektor, nachdem ich sie mit gimp “gemessen” hatte.
# Datensatz sortieren
edu_exp <- edu_exp[order(edu_exp$Population, decreasing = T),]
# Farben der vier Weltregionen
tuerkis <- rgb(0,213,233, max=255)
gruen <- rgb(127,235,0, max=255)
rot <- rgb(255,88,114, max=255)
gelb <- rgb(255,231,0, max=255)
Im nachfolgenden Code sind alle Schritte kommentiert:
edu_exp |>
# Auswahl der Daten von 2015:
subset(Year == 2015) |>
# Grund-Grafik anfordern:
ggplot(aes(x=Income, y=Expectancy)) +
# Neu: Text für die Jahreszahl ("2015") einfügen, sodass diese ganz im Hintergrund steht
annotate("text", x=8000, y=50, label="2015", size=50, colour ="grey90", family="courier new", fontface=2) +
# Neu: Farbthema: heller Hintergrund, schwarze Linien an x- und y-Achse
theme_classic() +
# Wie bisher: Punkte einzeichnen --> Streu-Punkt-Diagramm,
# Neu: Unterscheidung der Punkte nach Farbe (Region) und Größe (Population);
# Transparenz der Datenpunkte (alpha), Rand um die Punkte (shape)
geom_point(aes(fill = Region, size = Population), shape=21, alpha=.7, show.legend=F) +
# Skalieren der Größe der Punkte, sodass die Unterschiede deutlicher sind
scale_size(range = c(1, 30)) +
# Neu: Beschriftung der Achsen
labs(x="Income", y="Life expectancy") +
# Neu: Beschriftung an den Innenseiten der Achsen
annotate("text", x=125000, y=11, label="per Person (GDP/capita, PPP$ inflation-adjusted)", hjust = 1, vjust = 1) +
annotate("text", x=410, y=90, label="years", hjust = 1, vjust = -2, angle=90) +
# Neu: manuelle Spezifikation der y-Achse: Wertebereich, Position der Beschriftungen (10er-Schritte)
scale_y_continuous(limits = c(10, 92),
breaks = seq(10,92, by=10)) +
# Neu: manuelle Spezifikation der x-Achse: Wertebereich, log-Transformation, Position und Name der Beschriftungen
scale_x_continuous(limits = c(400,128000),
trans = "log2",
breaks = c(500, 1000, 2000, 4000, 8000, 16000, 32000, 64000, 128000),
labels = c("500", "1000", "2000", "4000", "8000", "16k", "32k", "64k", "128k")) +
# Neu: manuelle Spezifikation der Farben
scale_fill_manual(
values = c(tuerkis, gruen, rot, gelb),
breaks = c("africa", "americas", "asia", "europe")) +
# Neu: Theme (Anpassung der Schriftgroesse, relativ zur Groesse 12, blaues Raster im Hintergrund, Rand für die Legende)
theme(text = element_text(size=12),
axis.text = element_text(size=rel(.8)),
axis.title = element_text(size=rel(1.2)),
panel.grid.major = element_line(colour = "azure2"),
plot.margin = margin(1, 6, 1, 1, "cm")) -> plot_ohne_Legende
Die Grafik ohne Legende sieht nun so aus:
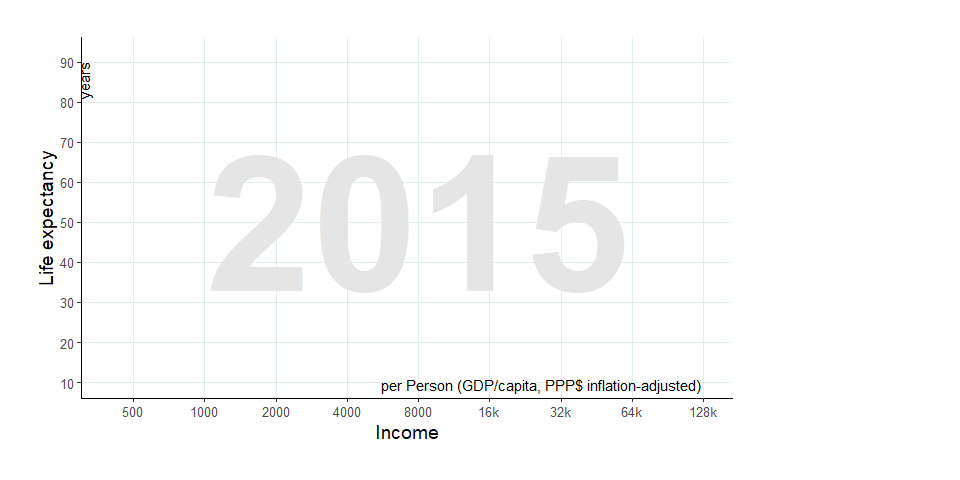
Um die Legende für die Farben (Weltregionen) anzufügen, habe ich einen Screenshot der Weltkarte von der gapminder-Webseite gemacht und als Bilddatei gespeichert (“5_gapminder-map.png”). Diese lese ich nun mit der image_read()-Funktion aus dem Paket magick ein. Anschließend füge ich sie “oben rechts” (x = 1, y = .95) in das zuvor erzeugte ggplot ein. Dafür verwende ich wieder die Funktion draw_image() aus dem Paket cowplot.
library(magick)
library(cowplot)
# Weltkarte (Screenshot von der gapminder Webseite)
weltkarte <- image_read("ggplotting-gapminder-map.png")
ggdraw(plot_ohne_Legende) +
draw_image(weltkarte, x = 1, y = .95, hjust = 1, vjust = 1, halign = 1, valign = 1, width = .2)
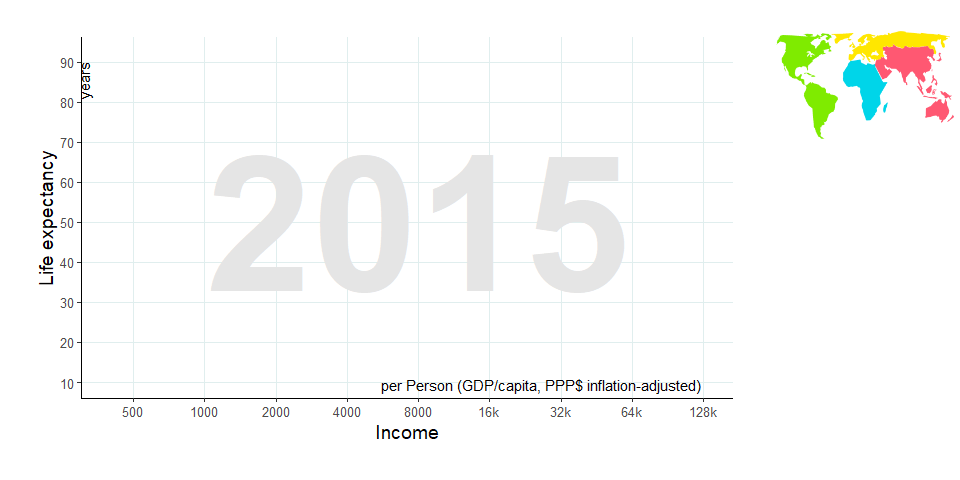
Und schließlich können wir die Grafik auch noch animieren, sodass sie dem Vorbild auf www.gapminder.org sogar noch ähnlicher wird. Leider scheinen sich cowplot und gganimate nicht so gut zu vertragen - daher muss ich die Farblegende rechts weglassen. Ansonsten kann ich den Code der statischen Grafik oben weitgehend übernehmen; lediglich die folgenden Dinge musste ich entfernen:
- Fallauswahl für das Jahr 2015
subset()) - Textbox mit “2015” im Hintergrund der Grafik (
annotate()) - der große Rand rechts (
plot.margin), weil es ja nun keine Legende gibt
edu_exp |>
ggplot(aes(x=Income, y=Expectancy)) +
theme_classic() +
geom_point(aes(fill = Region, size = Population), shape=21, alpha=.7, show.legend=F) +
scale_size(range = c(1, 30)) +
labs(x="Income", y="Life expectancy") +
annotate("text", x=125000, y=11, label="per Person (GDP/capita, PPP$ inflation-adjusted)", hjust = 1, vjust = 1) +
annotate("text", x=410, y=90, label="years", hjust = 1, vjust = -2, angle=90) +
scale_y_continuous(limits = c(10, 92),
breaks = seq(10,92, by=10)) +
scale_x_continuous(limits = c(400,128000),
trans = "log2",
breaks = c(500, 1000, 2000, 4000, 8000, 16000, 32000, 64000, 128000),
labels = c("500", "1000", "2000", "4000", "8000", "16k", "32k", "64k", "128k")) +
scale_fill_manual(
values = c(tuerkis, gruen, rot, gelb),
breaks = c("africa", "americas", "asia", "europe")) +
theme(text = element_text(size=12),
axis.text = element_text(size=rel(.8)),
axis.title = element_text(size=rel(1.2)),
panel.grid.major = element_line(colour = "azure2")) -> plot_ohne_Legende
library(gganimate)
anim <- plot_ohne_Legende +
transition_time(Year) +
labs(title = "{frame_time}") +
theme(plot.title = element_text(hjust=.5))
animate(anim, start_pause = 20, end_pause = 20,
height = 15, width = 30, units = "cm", res = 300)

Karten
Bei psychologischen Daten eher selten, aber mit dem Gapminder Datensatz natürlich sehr naheliegend, ist die Datenvisualisierung auf Karten. Für komplexere Karten (z.B. mit Google Maps) gibt es das ggmap Paket. Für unsere Zwecke reichen allerdings die von ggplot2 mitgelieferten Karten aus.
Karten benötigen eine sehr eigene Art der Datenaufbereitung, die häufig nicht gerade platzsparend ist. Daher sind die meisten Karten in R nicht als Datensätze vorhanden, sondern müssen erst einmal in solche überführt werden. Dafür gibt es die map_data Funktion. Um die Weltkarte in einen Datensatz zu übertragen, z.B.:
welt <- map_data('world')
head(welt)
## long lat group order region subregion
## 1 -69.89912 12.45200 1 1 Aruba <NA>
## 2 -69.89571 12.42300 1 2 Aruba <NA>
## 3 -69.94219 12.43853 1 3 Aruba <NA>
## 4 -70.00415 12.50049 1 4 Aruba <NA>
## 5 -70.06612 12.54697 1 5 Aruba <NA>
## 6 -70.05088 12.59707 1 6 Aruba <NA>
Was man in den Daten sieht sind Länge- und Breitengrade von Landesgrenzen. Außerdem bestimmt die Variable group das Land (anhand dessen die Landesgrenzen gruppiert werden sollten). Damit Linie der Grenzen nicht hin und her springt gibt es außerdem die Variable order die angibt, welcher Punkt in der Grenze als nächstes kommt. Anhand dieser Punkte werden in ggplot2 mit der allgemeinen geom_polygon Funktion Karten gezeichnet. Um eine leere Weltkarte zu erzeugen reicht Folgendes aus:
ggplot(welt, aes(x = long, y = lat, group = group)) +
geom_polygon()
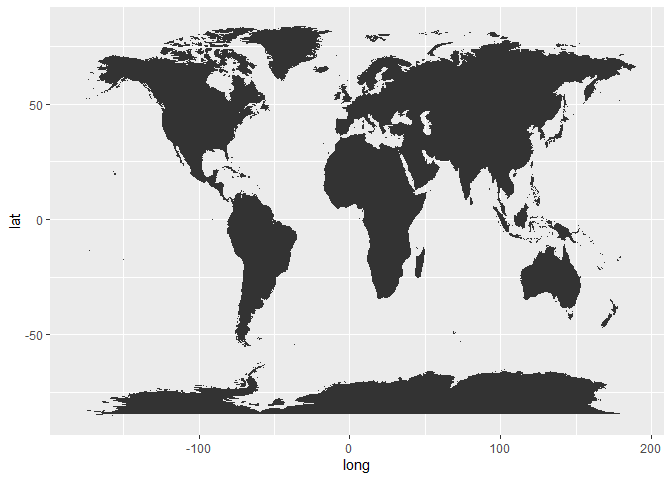
Wie man sieht, hat dieser Plot die gleichen Eigenschaften wie normale ggplots - weil es ein ganz normaler Plot ist. Um einzelne Länder erkennen zu können, sollten wir z.B. die Länder weiß und nicht schwarz füllen. Außerdem brauchen wir nicht unbedingt x- und y-Achse, sodass wir das komplett leere Theme theme_void nutzen können:
ggplot(welt, aes(x = long, y = lat, group = group)) +
geom_polygon(fill = 'white', color = 'black', lwd = .25) +
theme_void()
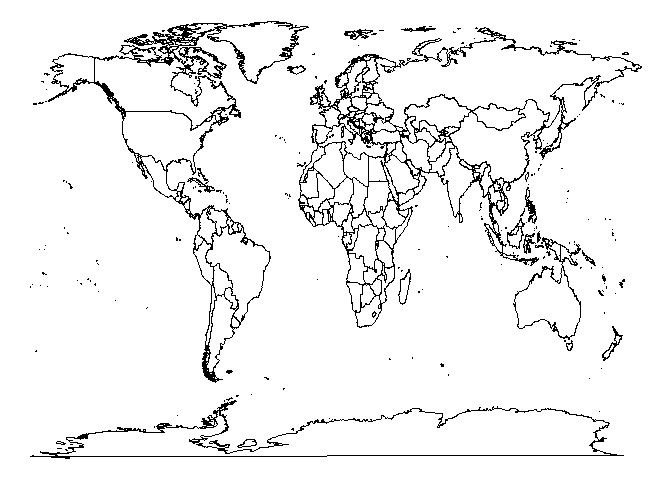
Um die Karten-Daten mit den Daten in Verbindung zu bringen steht uns leider - wie so häufig - im Weg, dass die Daten nicht einheitlich kodiert wurden. In diesem Fall sind es die Benennungen der Länder, die uneinheitlich sind. Um herauszufinden, wo Unterschiede bestehen, können wir die normalen Operatoren der Mengenvergleiche in R nutzen:
setdiff(unique(welt$region), unique(edu_exp$Country))
## [1] "Aruba"
## [2] "Anguilla"
## [3] "United Arab Emirates"
## [4] "American Samoa"
## [5] "Antarctica"
## [6] "French Southern and Antarctic Lands"
## [7] "Antigua"
## [8] "Barbuda"
## [9] "Saint Barthelemy"
## [10] "Bermuda"
## [11] "Ivory Coast"
## [12] "Democratic Republic of the Congo"
## [13] "Republic of Congo"
## [14] "Cook Islands"
## [15] "Curacao"
## [16] "Cayman Islands"
## [17] "Canary Islands"
## [18] "Falkland Islands"
## [19] "Reunion"
## [20] "Mayotte"
## [21] "French Guiana"
## [22] "Martinique"
## [23] "Guadeloupe"
## [24] "Faroe Islands"
## [25] "Micronesia"
## [26] "Guernsey"
## [27] "Greenland"
## [28] "Guam"
## [29] "Heard Island"
## [30] "Isle of Man"
## [31] "Cocos Islands"
## [32] "Christmas Island"
## [33] "Chagos Archipelago"
## [34] "Jersey"
## [35] "Siachen Glacier"
## [36] "Kyrgyzstan"
## [37] "Nevis"
## [38] "Saint Kitts"
## [39] "Kosovo"
## [40] "Laos"
## [41] "Saint Lucia"
## [42] "Saint Martin"
## [43] "Northern Mariana Islands"
## [44] "Montserrat"
## [45] "New Caledonia"
## [46] "Norfolk Island"
## [47] "Niue"
## [48] "Bonaire"
## [49] "Sint Eustatius"
## [50] "Saba"
## [51] "Pitcairn Islands"
## [52] "Puerto Rico"
## [53] "Madeira Islands"
## [54] "Azores"
## [55] "French Polynesia"
## [56] "Western Sahara"
## [57] "South Sandwich Islands"
## [58] "South Georgia"
## [59] "Saint Helena"
## [60] "Ascension Island"
## [61] "Saint Pierre and Miquelon"
## [62] "Slovakia"
## [63] "Swaziland"
## [64] "Sint Maarten"
## [65] "Turks and Caicos Islands"
## [66] "Trinidad"
## [67] "Tobago"
## [68] "Vatican"
## [69] "Grenadines"
## [70] "Saint Vincent"
## [71] "Virgin Islands"
## [72] "Wallis and Futuna"
setdiff(unique(edu_exp$Country), unique(welt$region))
## [1] "Congo, Dem. Rep." "Cote d'Ivoire"
## [3] "UAE" "Hong Kong, China"
## [5] "Lao" "Kyrgyz Republic"
## [7] "Slovak Republic" "Congo, Rep."
## [9] "Trinidad and Tobago" "Eswatini"
## [11] "St. Lucia" "St. Vincent and the Grenadines"
## [13] "Micronesia, Fed. Sts." "Antigua and Barbuda"
## [15] "St. Kitts and Nevis" "Tuvalu"
## [17] "Holy See"
Im Folgenden werden die Namen der Länder mit dem recode Befehl des car-Pakets umkodiert. Leider gibt es schon vorab ein Land, nach dem man in Datenaufbereitungen immer vorab schauen sollte: wie auch hier ist es häufiger der Fall, dass die Elfenbeiküste als Cote d'Ivoire kodiert ist. Leider bewirkt das ' in diesem Namen bei Umkodierungen immer einiges an Problemen, sodass wir es vorab direkt umstellen:
edu_exp[grepl('Cote', edu_exp$Country), 'Country'] <- 'Ivory Coast'
die verbleindenden Ländern können dann umkodiert werden:
# Recodes
edu_exp$Country <- car::recode(edu_exp$Country,
"'Antigua and Barbuda' = 'Antigua';
'Congo, Rep.' = 'Republic of Congo';
'Congo, Dem. Rep.' = 'Democratic Republic of the Congo';
'Micronesia, Fed. Sts.' = 'Micronesia';
'United Kingdom' = 'UK';
'Holy See' = 'Vatican';
'Kyrgyz Republic' = 'Kyrgyzstan';
'St. Kitts and Nevis' = 'Saint Kitts';
'Lao' = 'Laos';
'St. Lucia' = 'Saint Lucia';
'North Macedonia' = 'Macedonia';
'Slovak Republic' = 'Slovakia';
'Eswatini' = 'Swaziland';
'Trinidad and Tobago' = 'Trinidad';
'United States' = 'USA';
'Saint Vincent and the Grenadines' = 'Saint Vincent'")
Diese Umkodierung ist nicht auf andere Datensätze übertragbar - wir müssen immer in den Daten die vorliegen nachgucken, welche Schritte zum Angleichen verschiedener Datensätze notwendig sind.
Wir können den Datensatz auf das letzte Jahr beschränken, das wir vorliegen haben (2017):
edu_2017 <- subset(edu_exp, Year == 2017)
Anschließend können wir den Datensatz mit der Weltkarte zusammenführen. Dafür verwenden wir wieder den merge Befehl. Damit nach dem merge die Grenzen richtig gezeichnet werden, müssen wieder die Reihenfolge der Daten wiederherstellen. Dazu wird mit order nach Land (group) und dann nach Reihenfolge der Grenzpunkte (order) sortiert.
edu_map <- merge(welt, edu_2017,
by.x = 'region', by.y = 'Country',
all.x = TRUE, all.y = FALSE)
edu_map <- edu_map[order(edu_map$group, edu_map$order), ]
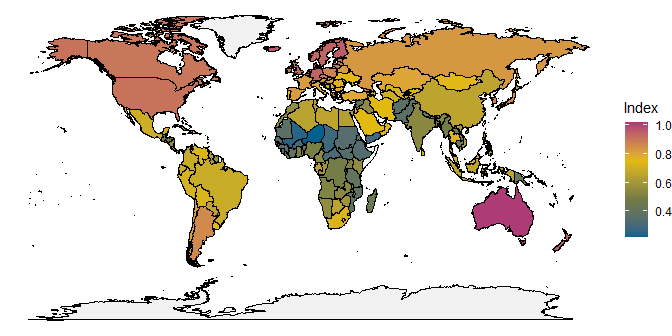
Mit den neuen Daten können wir unsere vorherige Karte jetzt so ergänzen, dass wir die Länder nach der Anzahl der Fälle einfärben:
ggplot(edu_map, aes(x = long, y = lat, group = group)) +
geom_polygon(color = 'black', lwd = .25,
aes(fill = Index)) +
theme_void() +
scale_fill_pandar(discrete = FALSE, na.value = 'grey95')
Wordcloud
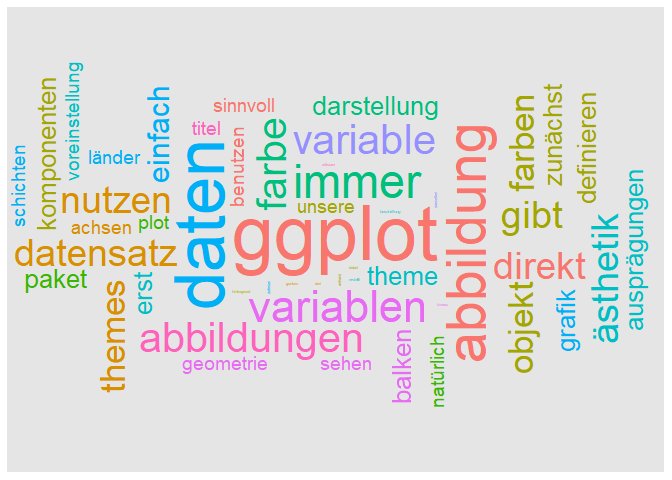
Nicht nur Zahlen, sondern auch Texte können visualisiert werden! Glauben Sie nicht? Naja stimmt, am Ende werden in Wordclouds ja auch wieder Zahlen dargestellt - nämlich die Häufigkeiten, mit der die Wörter im Textkorpus aufgetreten sind. Um so eine Wordcloud anzufordern, muss zunächst (a) der Text eingelesen werden, (b) eine sortierte Häufigkeitstabelle erstellt, und (3) die Wordcloud spezifiziert werden.
Zur Illustration lese ich zunächst die Texte aller pandaR Seiten aus, in denen wir die Inhalte schriftlich ausgearbeitet hatten.
Zum Auslesen der Texte verwende ich Funktionen aus rvest, mit dem sich prima Webscraping betreiben lässt. Außerdem habe ich herausgefunden, dass der relevante CSS-Selektor “p” heißt, in dem die Fließtexte stehen.
library(rvest)
## Warning: Paket 'rvest' wurde unter R Version 4.3.2 erstellt
# Funktion zum Einlesen der Texte von Websites
make.text <- function(website){
read_html(website) |>
html_nodes("p") |>
html_text() |>
paste(collapse = "")
}
# Anwenden der Funktion auf die relevanten pandaR-Seiten:
texte <- paste(
make.text('https://pandar.netlify.app/lehre/statistik-ii/grafiken-ggplot2'),
collapse = "")
Nun liegt ein sehr langer Fließtext vor, der sich aus den Texten der einzelnen Seiten zusammensetzt. Als nächstes muss dieser Text bereinigt werden, d.h., alle Großbuchstaben ersetzen, Sonderzeichen, Zahlen und stopwords entfernen, Satzzeichen entfernen, … Dafür bietet sich das Paket tm an.
library(tm)
## Lade nötiges Paket: NLP
##
## Attache Paket: 'NLP'
## Das folgende Objekt ist maskiert 'package:ggplot2':
##
## annotate
# Erstellen der Wort-Häufigkeitstabelle
docs <- Corpus(VectorSource(texte))
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, '[/@\\|\\"]')
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeNumbers)
docs <- tm_map(docs, removeWords, stopwords("german"))
docs <- tm_map(docs, removeWords, c("dass"))
docs <- tm_map(docs, removePunctuation)
docs <- tm_map(docs, stripWhitespace)
tdm <- as.matrix(TermDocumentMatrix(docs))
vec <- sort(rowSums(tdm), decreasing=TRUE)
table <- data.frame(word = names(vec), freq = vec)
Die ersten Zeilen der resultierenden Häufigkeitstabelle sehen nun so aus:
head(table)
## word freq
## ggplot ggplot 26
## daten daten 22
## abbildung abbildung 15
## immer immer 12
## variablen variablen 11
## abbildungen abbildungen 10
Diese Tabelle bildet nun die Grundlage für die Wordcloud. Zur Erstellung der Wordcloud nutze ich das Paket ggwordcloud. Es enthält eine Funktion für die entsprechende Geometrie, und es lassen sich alle sonstigen ggplot-Funktionen damit kombinieren. So kann ich beispielsweise über theme die Hintergrundfarbe spezifizieren.
# Erstellen der wordcloud
library(ggwordcloud)
## Warning: Paket 'ggwordcloud' wurde unter R Version 4.3.3 erstellt
table$angle <- 90 * sample(c(0, 1), nrow(table), replace = TRUE, prob = c(60, 40))
ggplot(table[1:50,],) +
geom_text_wordcloud(aes(label = word, size = freq,
color = factor(sample.int(10, 50, replace = TRUE)),
angle = angle)) +
scale_size(range = c(1, 20)) +
theme(panel.background = element_rect(fill = "grey90"))