](/media/header/grapevines_dark.jpg)
Vorbereitung
Datenbeispiel
- International College Survey (Diener, Kim-Pietro, Scollon, et al., 2001)
- Wohlbefinden in unterschiedlichen Ländern
load(url('https://pandar.netlify.app/post/kultur.rda'))
head(kultur)[, 1:8] # alle Zeilen und Spalten 1-8 für die ersten 6 Personen
## nation female auf_e kla_e lezu pa na bal
## 1 Turkey male 3.0 3.0 4.0 4.333333 4.250 0.08333333
## 2 Turkey female 2.5 2.5 5.6 5.333333 7.375 -2.04166667
## 3 Turkey female 3.0 3.0 4.0 5.666667 2.000 3.66666667
## 4 Turkey female 3.5 3.0 2.4 3.833333 5.000 -1.16666667
## 5 Turkey female 3.5 2.5 2.0 5.666667 6.125 -0.45833333
## 6 Turkey male 3.0 3.0 4.4 6.666667 4.500 2.16666667
- Lebenszufriedenheit (lezu)
- 5 Items auf einer Skala von 1 (“strongly disagree”) bis 7 (“strongly agree”)
- z.B. “I am satisfied with my life”
- Positiver Affekt (pa) & negativer Affekt (na)
- “For the following list of emotions, please rate how often you felt each of the emotions in the last week”
- Skala von 1 (“not at all”) bis 7 (“all the time”)
- Für positiven Affekt: Pleasant, Happy, Cheerful, etc.
- Für negativen Affekt: Unpleasant, Sad, Anger, etc.
- Klarheit eigener Gefühle (kla_e)
- Aufmerksamkeit auf eigene Gefühle (auf_e)
- Schachtelung in Nationen (nation)
levels(kultur$nation) # Übersicht über alle vorkommenden Nationen
## [1] "Turkey" "Korea" "Slovenia" "Nigeria"
## [5] "Japan" "Chile" "China" "Thailand"
## [9] "Australia" "Hong Kong" "Iran" "Greece"
## [13] "Philippines" "Nepal" "Cyprus" "Indonesia"
## [17] "Mexico" "Belgium" "Portugal" "Uganda"
## [21] "Singapore" "Netherlands" "Malaysia" "Georgia"
## [25] "Croatia" "Ghana" "Bulgaria" "Bangladesh"
## [29] "Russia" "Slovakia" "Zimbabwe" "Germany"
## [33] "Kuwait" "Columbia" "Brazil" "Cameroon"
## [37] "Canada" "India" "S. Africa" "Austria"
dim(kultur) # Anzahl Zeilen und Spalten des ganzen Datensatzes
## [1] 7194 16
Regressionsergebnisse im Beispiel
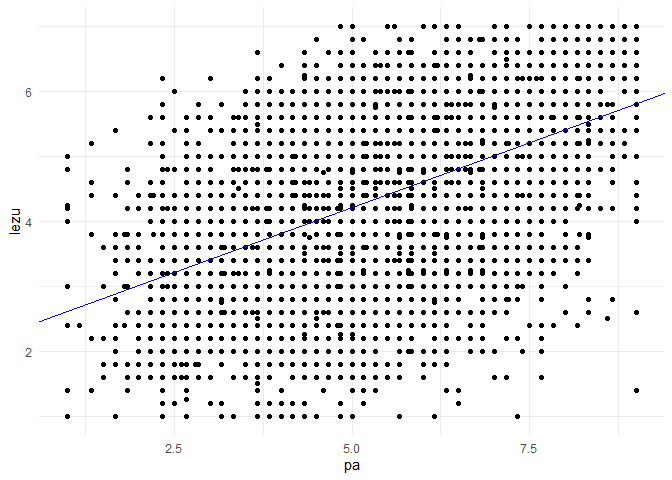
mod <- lm(lezu ~ 1 + pa, kultur) # Interzept wird hier explizit angefordert
summary(mod)
##
## Call:
## lm(formula = lezu ~ 1 + pa, data = kultur)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.4262 -0.7588 0.1076 0.7743 3.0413
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.225025 0.049592 44.87 <2e-16 ***
## pa 0.400132 0.008679 46.10 <2e-16 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.086 on 7139 degrees of freedom
## (53 observations deleted due to missingness)
## Multiple R-squared: 0.2294, Adjusted R-squared: 0.2293
## F-statistic: 2126 on 1 and 7139 DF, p-value: < 2.2e-16
- Darstellung der Ergebnisse (siehe ggplotting unter Extras)
library(ggplot2)
## Want to understand how all the pieces fit together?
## Read R for Data Science: https://r4ds.had.co.nz/
ggplot(kultur, aes(x = pa, y = lezu)) +
geom_point() +
geom_abline(intercept = coef(mod)[1], slope = coef(mod)[2], color = 'blue') +
theme_minimal()
## Warning: Removed 53 rows containing missing values
## (`geom_point()`).
- R-Funktionen für Regression
| Befehl | Funktionalität |
|---|---|
summary() | Zusammenfassung der Ergebnisse |
coef() | Koeffizienten ausgeben lassen |
confint() | Konfidenzintervalle für Koeffizienten |
resid() | Ausgabe der $e_{i}$ |
predict() | Ausgabe der $\hat{y}_i$ |
anova() | Modellvergleiche |
plot() | Residuenplots zur Diagnostik |
Pakete
# Für Plots der Modelle - dauert einen Moment
install.packages('sjPlot', dependencies = TRUE)
# Für eine erweiterte Modellzusammenfassung
installpackages('jtools')
Für alternative Ansätze der Darstellung bzw. Berechnung von Komponenten (nur in vereinzelten Beispielen genutzt)
# Für Inferenz der fixed effects
install.packages('lmerTest')
# Für Bestimmung von Pseudo R^2
install.packages('MuMIn')
Hintergrund zu LMMs
Verletzung der Annahme unabhängiger Beobachtungen
- Varianz kleiner als bei Zufallsstichprobe (wegen Abhängigkeiten)
- Effektives $n$ überschätzt
- Präzision der Effekte überschätzt (SE unterschätzt)
Koeffizienten nicht verzerrt, aber gemischt
- Risiko falscher Schlüsse
Für Umgang mit Voraussetzungsverletzung ist Korrektur der SE ausreichend
Für korrekte Zerlegung von Effekten und deren Wirkebene: LMMs
Feste Effekte (Kodiervariablen)
- Aussagen über einzelne Ausprägungen relevant
- Durch Studiendesign festgelegt oder natürliche Gruppen
- Geschlecht, Therapieansätze, Schulformen
Zufällige Effekte (LMMs)
- Zusammenfassende Aussagen über viele Ausprägungen relevant
- Per Zufall aus Population gezogen
- Schulklasse, Therapeut:innen, Teams
Übliche Begriffe
- Mehrebenenmodelle
- Gemischte Modelle (LMMs)
- Hierarchische Modelle
| Level 2 | Level 1 |
|---|---|
| macro-units | micro-units |
| primary units | secondary units |
| clusters | elementary units |
| between level | within level |
Nullmodell
Notation
| Notation | Bedeutung |
|---|---|
| $y_{ij}$ | AV-Wert von Person $i$ in Cluster $j$ |
| $r_{ij}$ | Residuum auf L1, Abweichung der Person von Vorhersage |
| $u_{0j}$ | Residuum auf L2, Abweichung des Clusters von Vorhersage |
| $\beta_{0j}$ | (bedingter) Erwartungswert für Cluster $j$ |
| $\gamma_{00}$ | Erwartungswert der Erwartungswerte über alle Cluster |
Level 1 $$ y_{ij} = \beta_{0j} + r_{ij} $$
Level 2 $$ \beta_{0j} = \gamma_{00} + u_{0j} $$
Gesamtgleichung $$ y_{ij} = \gamma_{00} + u_{0j} + r_{ij} $$
Nullmodell in lme4
library(lme4)
## Loading required package: Matrix
mod0 <- lmer(lezu ~ 1 + (1 | nation), kultur)
Generelle Schreibweise:
lmer: linear mixed effects regressionAV ~ UV: wie inlm(RE | Cluster): Welcher Parameter (RE) soll über die Cluster variieren dürfen
summary(mod0)
## Linear mixed model fit by REML ['lmerMod']
## Formula: lezu ~ 1 + (1 | nation)
## Data: kultur
##
## REML criterion at convergence: 21954.9
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.8470 -0.6650 0.0939 0.7345 3.3902
##
## Random effects:
## Groups Name Variance Std.Dev.
## nation (Intercept) 0.2854 0.5342
## Residual 1.2296 1.1089
## Number of obs: 7163, groups: nation, 40
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 4.39599 0.08581 51.23
Inferenzstatistik in lme4
confint(mod0)
## Computing profile confidence intervals ...
## 2.5 % 97.5 %
## .sig01 0.4264675 0.6719161
## .sigma 1.0908914 1.1273144
## (Intercept) 4.2259305 4.5662197
library(lmerTest)
##
## Attaching package: 'lmerTest'
## The following object is masked from 'package:lme4':
##
## lmer
## The following object is masked from 'package:stats':
##
## step
mod0 <- lmer(lezu ~ 1 + (1 | nation), kultur)
summary(mod0)
## Linear mixed model fit by REML. t-tests use
## Satterthwaite's method [lmerModLmerTest]
## Formula: lezu ~ 1 + (1 | nation)
## Data: kultur
##
## REML criterion at convergence: 21954.9
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.8470 -0.6650 0.0939 0.7345 3.3902
##
## Random effects:
## Groups Name Variance Std.Dev.
## nation (Intercept) 0.2854 0.5342
## Residual 1.2296 1.1089
## Number of obs: 7163, groups: nation, 40
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 4.39599 0.08581 39.05402 51.23 <2e-16
##
## (Intercept) ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Zufällige Effekte
summary(mod0)$var
## Groups Name Std.Dev.
## nation (Intercept) 0.53423
## Residual 1.10885
- Darstellung der Ergebnisse in
sjPlot- gibt
ggplotObjekt aus, sodass damit alle üblichen Anpassungen vorgenommen werden können
- gibt
library(sjPlot)
## Install package "strengejacke" from GitHub (`devtools::install_github("strengejacke/strengejacke")`) to load all sj-packages at once!
plot_model(mod0, type = 're', sort.est = '(Intercept)') + # Plot für Random Effects (re), sortiert nach Schätzung (est) der Interzept ('(Intercept)')
ggplot2::theme_minimal() # Layout
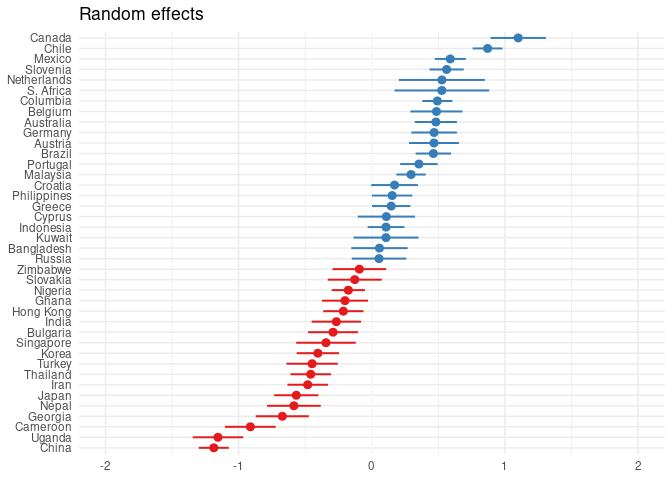
# Breite der Fehlerbalken hängt mit Stichprobengröße zusammen
- Einzelne Werte abrufen (für weitere Verarbeitung)
ranef(mod0)
## $nation
## (Intercept)
## Turkey -0.44818086
## Korea -0.40503647
## Slovenia 0.56208695
## Nigeria -0.17616391
## Japan -0.56699431
## Chile 0.86978321
## China -1.18650851
## Thailand -0.45861364
## Australia 0.48105911
## Hong Kong -0.21362638
## Iran -0.48112865
## Greece 0.14584524
## Philippines 0.15297260
## Nepal -0.58509359
## Cyprus 0.10940207
## Indonesia 0.10703558
## Mexico 0.58950252
## Belgium 0.48558728
## Portugal 0.35390197
## Uganda -1.15522933
## Singapore -0.34397158
## Netherlands 0.52671074
## Malaysia 0.29471140
## Georgia -0.67191598
## Croatia 0.17087872
## Ghana -0.20139742
## Bulgaria -0.29096543
## Bangladesh 0.05749552
## Russia 0.05460689
## Slovakia -0.12780524
## Zimbabwe -0.09329670
## Germany 0.46822898
## Kuwait 0.10655340
## Columbia 0.49243158
## Brazil 0.46243395
## Cameroon -0.91203076
## Canada 1.09983334
## India -0.26631345
## S. Africa 0.52621827
## Austria 0.46699289
##
## with conditional variances for "nation"
ICC
$$ ICC = \rho(y_{ij}, y_{i’j}) = \frac{var(u_{0j})}{var(y_{ij})} = \frac{\sigma^2_{u_{0j}}}{\sigma^2_{u_{0j}} + \sigma^2_{r_{ij}}} $$
- händisch berechnen:
tmp <- VarCorr(mod0) |> as.data.frame()
tmp$vcov[1] / sum(tmp$vcov)
## [1] 0.1883886
- in
jtools
library(jtools)
##
## Attaching package: 'jtools'
## The following objects are masked from 'package:interactions':
##
## cat_plot, interact_plot, johnson_neyman,
## probe_interaction, sim_slopes
print(summ(mod0))
## MODEL INFO:
## Observations: 7163
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 21960.88, BIC = 21981.51
## Pseudo-R² (fixed effects) = 0.00
## Pseudo-R² (total) = 0.19
##
## FIXED EFFECTS:
## -------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------ ------ -------- ------- ------
## (Intercept) 4.40 0.09 51.23 39.05 0.00
## -------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.53
## Residual 1.11
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.19
## --------------------------
- Wenn $ICC > 0$, ist die Annahme der Unabhängigkeit verletzt und es wird ein Multilevel-Modell benötigt
- Wenn $ICC > 0$ können dennoch Gruppenunterschiede bzgl. der Regressionsgewichte bestehen
- Häufig wird $ICC >.10$ als Cut-Off Kriterium gewertet
- Schon bei kleinen Werten, kann Clusterung zur starken Überschätzung der Power führen
- Forschungsbereich Bildung und Organisationen:
- klein: .05, mittel: .10, groß: .15
- Forschungsbereich kleine Gruppen und Familien:
- klein: .10, mittel: .20, groß: .30
- Generell: je größer die Gruppen desto kleiner ICC per Zufall
- Effektive Stichprobengröße: $$ n_{\text{eff}} = \frac{n}{1 + (n_{\text{clus}} - 1)ICC} $$
Level-1 Prädiktoren
Random Intercept Model
Level 1 $$ y_{ij} = \beta_{0j} + \beta_{1j}x_{ij} + r_{ij} $$
Level 2 $$ \beta_{0j} = \gamma_{00} + u_{0j} $$ $$ \beta_{1j} = \gamma_{10} $$
Gesamtgleichung $$ y_{ij} = \gamma_{00} + \gamma_{10}x_{ij} + u_{0j} + r_{ij} $$
Vergleich der Parameterinterpretation:
Nullmodell
- $\gamma_{00}$ Erwartungswert der Gruppenerwartungswerte
- $r_{ij}$ Abweichung eines individuellen Wertes vom jeweiligen Gruppenerwartungswert
- $u_{0j}$ u0j Abweichung eines Gruppenerwartungswert vom Erwartungswert der Gruppenerwartungswerte
Random Intercept Modell
- $\gamma_{00}$ Mittleres Intercept
- $r_{ij}$ Abweichung eines individuellen Wertes von der gruppenspezifische Regressionsgeraden bzw. vom vorhergesagten Wert
- $u_{0j}$ Abweichung eines gruppenspezifischen Intercepts vom mittleren Intercept
Modell in
lme4Aufstellen
mod1 <- lmer(lezu ~ 1 + pa + (1 | nation), kultur) # pa als Prädiktor zusätzlich aufnehmen
print(summ(mod1))
## MODEL INFO:
## Observations: 7141
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20481.85, BIC = 20509.35
## Pseudo-R² (fixed effects) = 0.18
## Pseudo-R² (total) = 0.31
##
## FIXED EFFECTS:
## ---------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------ ------ -------- --------- ------
## (Intercept) 2.50 0.09 29.35 82.79 0.00
## pa 0.35 0.01 39.64 7137.96 0.00
## ---------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.44
## Residual 1.00
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.16
## --------------------------
coef(mod1)$nation['Canada',] # spezifische Koeffizienten für Kanada auswählen
## (Intercept) pa
## Canada 3.391403 0.3490583
mod1b <- lmer(lezu ~ 1 + pa + (1 + pa | nation), kultur) # Random Intercept Random Slope Modell
summ(mod1b)
| Observations | 7141 |
| Dependent variable | lezu |
| Type | Mixed effects linear regression |
| AIC | 20440.39 |
| BIC | 20481.63 |
| Pseudo-R² (fixed effects) | 0.18 |
| Pseudo-R² (total) | 0.32 |
| Est. | S.E. | t val. | d.f. | p | |
|---|---|---|---|---|---|
| (Intercept) | 2.51 | 0.09 | 27.24 | 38.61 | 0.00 |
| pa | 0.35 | 0.02 | 21.82 | 38.56 | 0.00 |
| p values calculated using Satterthwaite d.f. |
| Group | Parameter | Std. Dev. |
|---|---|---|
| nation | (Intercept) | 0.47 |
| nation | pa | 0.08 |
| Residual | 1.00 |
| Group | # groups | ICC |
|---|---|---|
| nation | 40 | 0.18 |
Grafische Darstellung
plot_model(mod1, type = 're', sort.est = '(Intercept)')
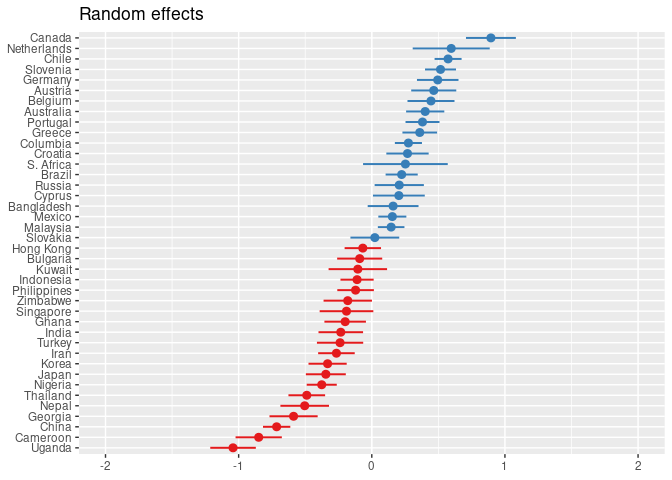
Mehrere Prädiktoren
- Übungsaufgabe: positiven und negativen Affekt aufnehmen
- Was ist bedeutsam in der Vorhersage der Lebenszufriedenheit?
mod2 <- lmer(lezu ~ 1 + pa + na + (1 | nation), kultur)
print(summ(mod2))
## MODEL INFO:
## Observations: 7134
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20140.59, BIC = 20174.96
## Pseudo-R² (fixed effects) = 0.21
## Pseudo-R² (total) = 0.34
##
## FIXED EFFECTS:
## ----------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------- ------ -------- --------- ------
## (Intercept) 3.34 0.10 35.04 137.11 0.00
## pa 0.31 0.01 35.49 7130.58 0.00
## na -0.18 0.01 -18.45 7126.81 0.00
## ----------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.43
## Residual 0.98
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.16
## --------------------------
Prüfung via Modellvergleich
anova(mod0, mod1, mod2)
## Error in anova.merMod(mod0, mod1, mod2): models were not all fitted to the same size of dataset
- Fehlende Werte auf den UVs verändern Größe des Datensatzes
kultur_comp <- mod2@frame
mod0_u <- update(mod0, data = kultur_comp)
mod1_u <- update(mod1, data = kultur_comp)
mod2_u <- update(mod2, data = kultur_comp)
anova(mod0_u, mod1_u, mod2_u)
## refitting model(s) with ML (instead of REML)
## Data: kultur_comp
## Models:
## mod0_u: lezu ~ 1 + (1 | nation)
## mod1_u: lezu ~ 1 + pa + (1 | nation)
## mod2_u: lezu ~ 1 + pa + na + (1 | nation)
## npar AIC BIC logLik deviance Chisq Df
## mod0_u 3 21868 21889 -10931 21862
## mod1_u 4 20453 20480 -10222 20445 1417.51 1
## mod2_u 5 20122 20156 -10056 20112 332.65 1
## Pr(>Chisq)
## mod0_u
## mod1_u < 2.2e-16 ***
## mod2_u < 2.2e-16 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Random Slopes Modelle
Level 1 $$ y_{ij} = \beta_{0j} + \beta_{1j}x_{1ij} + \beta_{2j}x_{2ij} + r_{ij} $$
Level 2 $$ \beta_{0j} = \gamma_{00} + u_{0j} $$ $$ \beta_{1j} = \gamma_{10} + u_{1j} $$ $$ \beta_{2j} = \gamma_{20} + u_{2j} $$
Gesamtgleichung $$ y_{ij} = \gamma_{00} + \gamma_{10}x_{1ij} + \gamma_{20}x_{2ij} + u_{0j} + u_{1j}x_{1ij} + u_{2j}x_{2ij} + r_{ij} $$
mod3 <- lmer(lezu ~ 1 + pa + na + (1 + pa + na | nation), kultur)
## Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl =
## control$checkConv, : Model failed to converge with
## max|grad| = 0.00698484 (tol = 0.002, component 1)
- Fehlende Konvergenz des Modells
- sehr kleine Zufallseffekte
- sehr hohe Korrelationen zwischen Zufallseffekten
- hohe Modellkomplexität
- in jedem Fall: inhaltliche Diagnostik betreiben!
# Optimizer wechseln, langsamer aber Versuch Konvergenz zu erreichen
opts <- lmerControl(optimizer = 'bobyqa')
mod3 <- lmer(lezu ~ 1 + pa + na + (1 + pa + na | nation), kultur, control = opts)
print(summ(mod3))
## MODEL INFO:
## Observations: 7134
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20092.97, BIC = 20161.69
## Pseudo-R² (fixed effects) = 0.21
## Pseudo-R² (total) = 0.35
##
## FIXED EFFECTS:
## --------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------- ------ -------- ------- ------
## (Intercept) 3.38 0.10 33.31 39.77 0.00
## pa 0.31 0.01 21.44 37.36 0.00
## na -0.18 0.02 -11.26 35.54 0.00
## --------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.46
## nation pa 0.07
## nation na 0.08
## Residual 0.97
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.18
## --------------------------
- Gibt leider Korrelationen zwischen REs nicht aus
summary(mod3)$varcor
## Groups Name Std.Dev. Corr
## nation (Intercept) 0.461841
## pa 0.068146 -0.201
## na 0.078971 -0.545 -0.170
## Residual 0.972926
Tests der Zufallseffekte
anova(mod0, mod1) # Fehlermeldung, da Modelle auf den gleichen Datensatz angewandt werden müssen
# Respezifizierung
mod0b <- update(mod0, data = mod1@frame)
mod1b <- update(mod1, data = mod1@frame)
anova(mod0b, mod1b)
## refitting model(s) with ML (instead of REML)
## Data: mod1@frame
## Models:
## mod0b: lezu ~ 1 + (1 | nation)
## mod1b: lezu ~ 1 + pa + (1 | nation)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## mod0b 3 21888 21909 -10941 21882
## mod1b 4 20471 20498 -10231 20463 1419.8 1 < 2.2e-16
##
## mod0b
## mod1b ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
anova(mod2, mod3, refit = FALSE)
## Data: kultur
## Models:
## mod2: lezu ~ 1 + pa + na + (1 | nation)
## mod3: lezu ~ 1 + pa + na + (1 + pa + na | nation)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## mod2 5 20141 20175 -10065 20131
## mod3 10 20093 20162 -10036 20073 57.625 5 3.758e-11
##
## mod2
## mod3 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
confint(mod3)
## 2.5 % 97.5 %
## .sig01 0.28803189 0.65838445
## .sig02 -0.59999696 0.41636426
## .sig03 -0.81112066 -0.04285697
## .sig04 0.04324943 0.09596252
## .sig05 -0.68676513 0.35625998
## .sig06 0.05101183 0.11042401
## .sigma 0.95705358 0.98925414
## (Intercept) 3.18096518 3.58486611
## pa 0.27964164 0.33677395
## na -0.21457578 -0.15018436
Cluster-spezifische Effekte
coef(mod3)
## $nation
## (Intercept) pa na
## Turkey 3.079609 0.3240335 -0.15334430
## Korea 3.035652 0.3134756 -0.18870927
## Slovenia 4.175206 0.2567306 -0.21844958
## Nigeria 2.884775 0.2613936 -0.06944037
## Japan 3.348555 0.3633213 -0.30076708
## Chile 3.532361 0.3643897 -0.15439392
## China 2.598440 0.2457450 -0.12783837
## Thailand 3.244452 0.2347657 -0.15131066
## Australia 3.786806 0.3451124 -0.25063483
## Hong Kong 3.088846 0.3728187 -0.18464812
## Iran 3.025575 0.3631968 -0.20183329
## Greece 3.643419 0.2642847 -0.10955991
## Philippines 3.292682 0.3213366 -0.18554132
## Nepal 2.964934 0.3076757 -0.19683121
## Cyprus 3.678413 0.3042301 -0.18522169
## Indonesia 3.194257 0.3054312 -0.14505951
## Mexico 2.998797 0.3464551 -0.08919096
## Belgium 3.642758 0.3557332 -0.22231382
## Portugal 3.719618 0.3758926 -0.28584215
## Uganda 3.299325 0.2149200 -0.33049530
## Singapore 3.148670 0.3434949 -0.19295706
## Netherlands 3.598536 0.3259988 -0.12747582
## Malaysia 3.580539 0.2726054 -0.12509839
## Georgia 3.061731 0.2409629 -0.17861740
## Croatia 3.657427 0.3363808 -0.24157264
## Ghana 3.676624 0.2090380 -0.19709996
## Bulgaria 3.329737 0.2706613 -0.16330327
## Bangladesh 3.190197 0.3365804 -0.10865159
## Russia 3.444138 0.2978680 -0.14481123
## Slovakia 3.859745 0.2801994 -0.27383103
## Zimbabwe 3.340911 0.2964229 -0.18914432
## Germany 3.826812 0.3333658 -0.21541109
## Kuwait 3.378347 0.3747503 -0.24066901
## Columbia 2.904568 0.4045385 -0.12502986
## Brazil 3.720055 0.3164294 -0.20185945
## Cameroon 2.786755 0.1910105 -0.08125616
## Canada 3.953572 0.3682449 -0.22887844
## India 3.263558 0.2099854 -0.07876218
## S. Africa 3.590770 0.3093363 -0.18161212
## Austria 3.685436 0.3694097 -0.23295950
##
## attr(,"class")
## [1] "coef.mer"
plot_model(mod3, type = 're', grid = FALSE, sort.est = TRUE)[c(1,3)]
## [[1]]
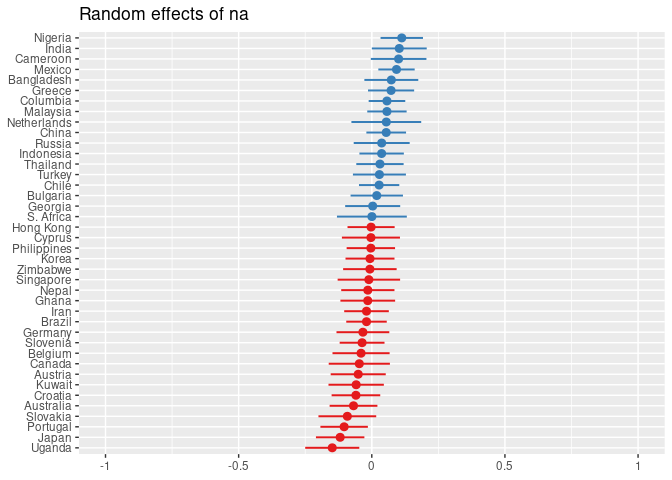
##
## [[2]]
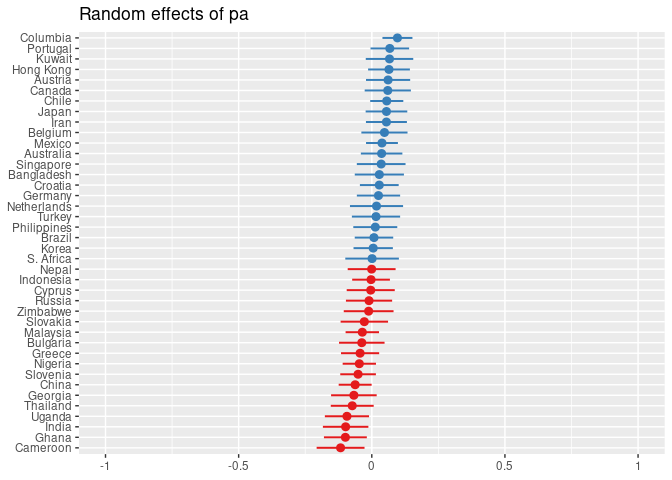
Level 2 Prädiktoren
Im Random Intercept Modell
Level 1 $$ y_{ij} = \beta_{0j} + \beta_{1j}x_{1ij} + \beta_{2j}x_{2ij} + r_{ij} $$
Level 2 $$ \beta_{0j} = \gamma_{00} + \gamma_{01} w_{j} + u_{0j} $$ $$ \beta_{1j} = \gamma_{10} $$ $$ \beta_{2j} = \gamma_{20} $$
Gesamtgleichung $$ y_{ij} = \gamma_{00} + \gamma_{10}x_{1ij} + \gamma_{20}x_{2ij} + \gamma_{01} w_{j} + u_{0j} + r_{ij} $$
- Interpretation der Parameter
(Intercept)Erwarteter Lebenszufriedenheitswert für Menschen mit 0 positiven Affekt in einem Land mit 0 GDPpa/naUnterschied zwischen Personen, die sich um eine Einheit im positiven/negativen Affekt unterscheiden, aber aus Ländern mit gleichem GDP kommen.gdpUnterschied zwischen Personen mit gleichem positivem und negativen Affekt die aus Ländern mit 1 GDP Unterschied kommen
mod4 <- lmer(lezu ~ 1 + pa + na + gdp + (1 | nation), kultur)
print(summ(mod4))
## MODEL INFO:
## Observations: 7134
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20120.50, BIC = 20161.74
## Pseudo-R² (fixed effects) = 0.26
## Pseudo-R² (total) = 0.33
##
## FIXED EFFECTS:
## ----------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------- ------ -------- --------- ------
## (Intercept) 2.08 0.24 8.55 44.68 0.00
## pa 0.31 0.01 35.70 7116.43 0.00
## na -0.18 0.01 -18.45 7128.77 0.00
## gdp 1.72 0.32 5.45 38.61 0.00
## ----------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.32
## Residual 0.98
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.10
## --------------------------
Zentrierung
- Effekte der L1 Prädiktoren sind Mischungen aus Individual- und Ländereffekten
- Allgemein CWC für die meisten L1 Prädiktoren empfohlen (mehr bei Enders & Tofighi, 2007, und Yaremych et al., 2021)
cwc <- with(kultur, aggregate(cbind(pa, na) ~ nation, FUN = mean))
names(cwc) <- c('nation', 'pa_mean', 'na_mean')
kultur_cen <- merge(kultur, cwc, by = 'nation', all.x = TRUE)
kultur$pa_cwc <- kultur$pa - kultur$pa_mean
kultur$na_cwc <- kultur$na - kultur$na_mean
- Modellterme verändern sich
mod5 <- lmer(lezu ~ 1 + pa_mean + pa_cwc + na_mean + na_cwc + (1 | nation), kultur)
print(summ(mod5))
## MODEL INFO:
## Observations: 7134
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20141.83, BIC = 20189.94
## Pseudo-R² (fixed effects) = 0.27
## Pseudo-R² (total) = 0.38
##
## FIXED EFFECTS:
## ----------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------- ------ -------- --------- ------
## (Intercept) 1.96 0.86 2.27 36.67 0.03
## pa_mean 0.63 0.12 5.25 36.45 0.00
## pa_cwc 0.31 0.01 35.24 7091.92 0.00
## na_mean -0.27 0.15 -1.79 37.60 0.08
## na_cwc -0.18 0.01 -18.42 7091.92 0.00
## ----------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.40
## Residual 0.98
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.14
## --------------------------
Cross-Level Interaktion
Level 1 $$ y_{ij} = \beta_{0j} + \beta_{1j}x_{1ij} + \beta_{2j}x_{2ij} + r_{ij} $$
Level 2 $$ \beta_{0j} = \gamma_{00} + \gamma_{01} w_{j} + u_{0j} $$ $$ \beta_{1j} = \gamma_{10} + \gamma_{11} w_{j} + u_{1j} $$ $$ \beta_{2j} = \gamma_{20} + \gamma_{21} w_{j} + u_{2j} $$
Gesamtgleichung $$ y_{ij} = \gamma_{00} + \gamma_{10}x_{1ij} + \gamma_{20}x_{2ij} + \gamma_{01} w_{j} + \gamma_{11} w_{j}x_{1ij} + \gamma_{21} w_{j}x_{2ij} + u_{0j} + u_{1j}x_{1ij} + u_{2j}x_{2ij} + r_{ij} $$
| Parameter | Bedeutung |
|---|---|
| $\gamma_{00}$ | Mittleres Intercept |
| $\gamma_{01}$ | Regressionsgewicht des L2-Prädiktors $w_j$ für den Random Intercept |
| $\gamma_{10}$ | Slope des L1-Prädiktors $x_{ij}$ für L2-Einheiten mit $w_j = 0$, $E(B_1 |
| $\gamma_{11}$ | Veränderung von $\hat\beta_{ij}$ pro Einheit des L2-Prädiktors $w_j$ |
| $u_{0j}$ | L2-Residuum bzgl. der Intercepts $(\beta_{0j} − \hat\beta_{0j})$ |
| $u_{1j}$ | L2-Residuum bzgl. des Slopes $(\beta_{1j} − \hat\beta_{1j})$ |
| $r_{ij}$ | L1-Residuum $(y_{ij} − \hat y_{ij})$ |
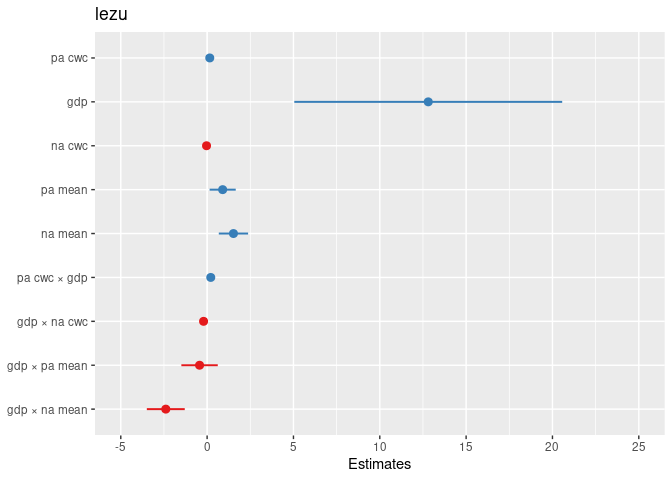
mod6 <- lmer(lezu ~ pa_cwc*gdp + na_cwc*gdp + pa_mean*gdp + na_mean*gdp + (pa_cwc + na_cwc | nation), kultur)
print(summ(mod6))
## MODEL INFO:
## Observations: 7134
## Dependent Variable: lezu
## Type: Mixed effects linear regression
##
## MODEL FIT:
## AIC = 20057.76, BIC = 20174.59
## Pseudo-R² (fixed effects) = 0.33
## Pseudo-R² (total) = 0.37
##
## FIXED EFFECTS:
## --------------------------------------------------------
## Est. S.E. t val. d.f. p
## ----------------- ------- ------ -------- ------- ------
## (Intercept) -7.30 2.85 -2.56 35.30 0.01
## pa_cwc 0.15 0.06 2.50 41.71 0.02
## gdp 12.81 3.96 3.24 36.45 0.00
## na_cwc -0.03 0.07 -0.48 34.65 0.63
## pa_mean 0.90 0.39 2.33 33.17 0.03
## na_mean 1.53 0.43 3.52 37.09 0.00
## pa_cwc:gdp 0.21 0.08 2.56 42.40 0.01
## gdp:na_cwc -0.21 0.09 -2.21 35.70 0.03
## gdp:pa_mean -0.44 0.54 -0.81 34.11 0.42
## gdp:na_mean -2.39 0.56 -4.27 38.05 0.00
## --------------------------------------------------------
##
## p values calculated using Satterthwaite d.f.
##
## RANDOM EFFECTS:
## ------------------------------------
## Group Parameter Std. Dev.
## ---------- ------------- -----------
## nation (Intercept) 0.22
## nation pa_cwc 0.06
## nation na_cwc 0.07
## Residual 0.97
## ------------------------------------
##
## Grouping variables:
## --------------------------
## Group # groups ICC
## -------- ---------- ------
## nation 40 0.05
## --------------------------
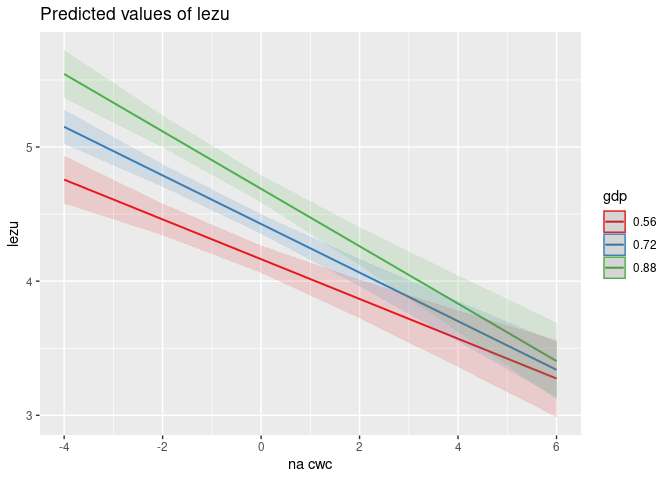
plot_model(mod6, 'pred',
terms = c('na_cwc', 'gdp'))
plot_model(mod6, 'est')