](/media/header/plane.jpg)
Konfirmatorische Faktorenanalyse
Einleitung
In der letzten Sitzung wurden faktoranalytische Verfahren für Datenexploration behandelt. Die Ergebnisse der EFA sind datengesteuert: welche Items welchen Faktoren zugeordnet werden, wie viele Faktoren genutzt werden, wie stark der Zusammenhang zwischen Item und Faktor ist, das alles sind Dinge, die aus den Daten heraus entschieden werden. In dieser Sitzung betrachten wir das Vorgehen, wenn in der Faktorenanalyse von einem konkreten, theoretisch fundierten Modell ausgegangen wird und dieses anhand empirischer Daten geprüft werden soll. Ganz im Popper’schen Sinn lässt sich nur durch ein solches Vorgehen wissenschaftliche Erkenntnis gewinnen.
Für die Umsetzung der CFA nutzen wir erneut lavaan. In der ersten Sitzung dieses Semesters hatten wir uns den Umgang mit lavaan schon detailliert angesehen. Grob gesagt gehen wir in drei Schritten vor:
- Modellsyntax schreiben und in einem Objekt ablegen
- Modell schätzen und Ergebnisse in Objekt ablegen
- Ergebnisse im Objekt aus Schritt 2 inspizieren
In der ersten Sitzung hatten wir gesehen, dass in lavaan anhand weniger Begriffe das Pfadmodell in Syntax übersetzt wird, um unser Modell schätzbar zu machen. Diese Begriffe waren
| Bezeichnung | Befehl | Bedeutung |
|---|---|---|
| Regression | ~ | wird vorhergesagt durch |
| Kovarianz | ~~ | kovariiert mit |
| Intercept | ~1 | wird auf 1 regressiert |
| Faktorladung | =~ | wird gemessen durch |
| Formative Faktoren | <~ | wird konstruiert durch |
| Schwellenparameter | ` | t…` |
In der ersten Sitzung hatten wir nur mit ~, ~1 und ~~ für Regressionen, Intercepts und Residualvarianzen gearbeitet. Heute kommen Faktorladungen dazu.
Diese Sitzung schließt mit einem Appendix zur Hierarchie der Messmodelle ab. Wenn Sie ihre inhaltlichen Kenntnisse vertiefen wollen, oder durch ein bisschen zusätzliche Übung Ihre lavaan-Fähigkeiten verbessern möchten, empfehlen wir Ihnen, sich diesen Abschnitt anzugucken!
Datensatz
Konkret wird es in dieser Sitzung um die Faktorstruktur verschwörungstheoretischer Überzeugungen gehen. Dafür nutzen wir Daten aus der Erhebung zur Validierung der Generic Conspiracist Beliefs Scale (GCBS; Brotherton, French, & Pickering, 2013). Die Daten finden Sie öffentlich zugänglich auf der Open Psychometrics Website. Natürlich können Sie dort den Fragebogen auch selbst ausfüllen, wenn Sie möchten. Der Fragebogen besteht aus insgesamt 15 Aussagen, die die Probanden jeweils von 1 (“definitely not true”) bis 5 (“definitely true”) hinsichtlich ihres Wahrheitsgehalts einschätzen sollen.
| Nr. | Facette | Itemformulierung |
|---|---|---|
| 1 | GM | The government is involved in the murder of innocent citizens and/or well-known public figures, and keeps this a secret |
| 2 | GC | The power held by heads of state is second to that of small unknown groups who really control world politics |
| 3 | EC | Secret organizations communicate with extraterrestrials, but keep this fact from the public |
| 4 | PW | The spread of certain viruses and/or diseases is the result of the deliberate, concealed efforts of some organization |
| 5 | CI | Groups of scientists manipulate, fabricate, or suppress evidence in order to deceive the public |
| 6 | GM | The government permits or perpetrates acts of terrorism on its own soil, disguising its involvement |
| 7 | GC | A small, secret group of people is responsible for making all major world decisions, such as going to war |
| 8 | EC | Evidence of alien contact is being concealed from the public |
| 9 | PW | Technology with mind-control capacities is used on people without their knowledge |
| 10 | CI | New and advanced technology which would harm current industry is being suppressed |
| 11 | GM | The government uses people as patsies to hide its involvement in criminal activity |
| 12 | GC | Certain significant events have been the result of the activity of a small group who secretly manipulate world events |
| 13 | EC | Some UFO sightings and rumors are planned or staged in order to distract the public from real alien contact |
| 14 | PW | Experiments involving new drugs or technologies are routinely carried out on the public without their knowledge or consent |
| 15 | CI | A lot of important information is deliberately concealed from the public out of self-interest |
Die 15 Aussagen können auf theoretischer Grundlage fünf verschiedenen Facetten zugeordnet werden, die in der Tabelle mit ihren jeweiligen Abkürzungen eingetragen sind:
- GM: Government malfeasance
- GC: Malevolent global conspiracies
- EC: Extraterrestrial cover-up
- PW: Personal well-being
- CI: Control of information
In dieser Sitzung werden wir untersuchen, inwiefern diese theoretische Zuordnung einer empirischen Prüfung standhält.
Zunächst können wir den Datensatz laden und ein bisschen genauer betrachten. Wie schon für die letzten beiden Sitzungen, haben wir den Datensatz bereits im .rda-Format aufbereitet, sodass Sie Ihn direkt in R von dieser laden können:
source("../../daten/Data_Processing_conspiracy_cfa.R")
Alternativ können Sie den Datensatz natürlich auch für den lokalen Gebrauch hier herunterladen.
Der Datensatz ist etwas groß, um ihn sich direkt in der Ausgaben anzugucken. Deswegen hier ein kurzer Überblick über seine grundlegenden Eigenschaften:
# Anzahl der Personen
nrow(conspiracy)
## [1] 2495
# Anzahl der Variablen
ncol(conspiracy)
## [1] 19
# Struktur des Datensatzes
str(conspiracy)
## 'data.frame': 2495 obs. of 19 variables:
## $ edu : Factor w/ 3 levels "not highschool",..: 3 1 3 3 2 3 2 2 1 3 ...
## $ urban : Factor w/ 3 levels "rural","suburban",..: NA 2 2 1 2 1 2 1 3 3 ...
## $ gender: Factor w/ 3 levels "male","female",..: 1 2 2 1 1 1 1 1 1 1 ...
## $ age : int 28 14 26 25 37 34 17 23 17 28 ...
## $ Q1 : int 5 5 2 5 5 1 4 5 1 1 ...
## $ Q2 : int 5 5 4 4 4 1 3 4 1 2 ...
## $ Q3 : int 3 5 1 1 1 1 3 3 1 1 ...
## $ Q4 : int 5 5 2 2 4 1 3 3 1 1 ...
## $ Q5 : int 5 5 2 4 4 1 4 4 1 1 ...
## $ Q6 : int 5 3 2 5 5 1 3 5 1 5 ...
## $ Q7 : int 5 5 4 4 4 1 3 5 1 1 ...
## $ Q8 : int 3 5 2 1 3 1 4 5 1 1 ...
## $ Q9 : int 4 1 2 4 1 1 2 5 1 1 ...
## $ Q10 : int 5 4 4 5 5 1 3 5 1 4 ...
## $ Q11 : int 5 4 2 5 5 1 3 5 1 1 ...
## $ Q12 : int 5 5 4 5 5 1 2 5 1 1 ...
## $ Q13 : int 3 4 0 1 3 1 2 3 1 1 ...
## $ Q14 : int 5 4 2 4 5 1 3 4 1 1 ...
## $ Q15 : int 5 5 4 5 5 1 4 5 1 5 ...
Neben den bereitsch beschriebenen 15 Items enthält der Datensatz noch Informationen zum Bildungsniveau (edu), Art des Wohnortes (urban), Geschlecht (gender) und Alter (age) der Befragten. Diese Variablen sind in dieser Sitzung aber zunächst irrelevant.
Einfaktorielles Modell
In der Konzeption der verschwörungstheoretischen Überzeugungen nach Brotherton, French und Pickering (2013) wird behauptet, dass die Items 2, 7 und 12 ein gemeinsames Konstrukt - nämlich “Malevolent global conspiracies” - erheben. Hier noch einmal die genaue Formulierung der drei Aussagen:
| Nr. | Itemformulierung |
|---|---|
| 2 | The power held by heads of state is second to that of small unknown groups who really control world politics |
| 7 | A small, secret group of people is responsible for making all major world decisions, such as going to war |
| 12 | Certain significant events have been the result of the activity of a small group who secretly manipulate world events |
Es wird also behauptet, dass es eine grundlegende Eigenschaft von Personen gibt, die das Ausmaß bestimmt, in dem Personen diese Aussagen als wahr einschätzen. Mithilfe der CFA können wir versuchen, diese Behauptung zu prüfen.
Als Pfadmodell dargestellt sieht das zunächst so aus:

Hier stellen wir das Modell zunächst ohne Gewichtungen dar - es werden lediglich die Beziehungen/Zusammensetzungen zwischen den Variablen verdeutlicht: die Messungen Q2, Q7 und Q12 setzen sich alle aus der zugrundeliegenden latenten Variable GC und dem itemspezifischen Messfehler zusammen.
Modellsyntax
Wie wir es in der ersten Sitzung für die Regression gesehen haben, können wir dieses Pfaddiagramm in lavaan Modellsyntax übersetzen. Zunächst haben wir eine latente Variable, die wir nach Belieben benennen können. Weil es sich anbietet, nennen wir sie GC für “global conspiracy”. Diese latente Variable wirkt sich auf drei manifesten Variablen aus. Bei diesen Variablen haben wir nicht die gleichen Freiheiten in der Benennung, weil es sich bei diesen um manifeste Variablen handelt, die im Datensatz bereits existieren. Daher müssen wir hier auch die Namen verwenden, die im Datensatz für die Variablen genutzt werden. Mit dem =~ wird die Beziehung zwischen einer latenten Variable (links) und beliebig vielen manifesten Variablen (rechts) dargestellt. Diese Beziehung wird allgemein in Form von Faktorladungen quantifiziert. Mehrere manifeste Variablen, die der gleichen latenten Variable zugeordnet werden, können mit einem + verbunden werden. Für die Faktorstruktur sieht der Modellsyntax-Abschnitt also so aus:
'GC =~ Q2 + Q7 + Q12'
Wie schon in der Sitzung zur Regression müssen wir außerdem explizit Residualvarianzen anfordern, weil das Modell sonst behaupten würde, dass die latente Variable eine Varianzaufklärung von 100% an unseren manifesten Variablen leistet. Obwohl das zwar außerordentlich schön für die Entwickler des Fragebogens wäre, wenn es so wäre, ist beinahe jede manifeste Variable in der psychologischen Forschung mit einem gewissen Maß an Messfehler behaftet. Dieser wird in der CFA als Residualvarianz abgebildet. Daher erweitert sich unser Modell um die folgenden drei Zeilen:
'# Faktorladungen
GC =~ Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12'
Um das Modell ein wenig zu gliedern, haben wir mit dem # Kommentare in die Modellsyntax eingefügt, die die einzelnen Abschnitte voneinander abgrenzen. Auch dieses Modell ist noch nicht ganz vollständig. Weil die Varianz der latenten Variable GC nicht explizit angesprochen wird, wird - wie schon bei den Residuen - per Voreinstellung davon ausgegangen, dass diese Varianz 0 ist. Um Varianz auf der latenten Variable zuzulassen, müssen wir also auch diese explizit in das Modell aufnehmen:
'# Faktorladungen
GC =~ Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12
# Latente Varianz
GC ~~ GC'
Dieses Modell müssen wir erneut einem Objekt zuweisen, damit wir es gleich in der lavaan-Funktion ansprechen können. In einer glorreichen Demonstration meines Einfallsreichtums habe ich dieses Objekt mod1 benannt - Modell 1.
mod1 <- '# Faktorladungen
GC =~ Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12
# Latente Varianz
GC ~~ GC'
Modellschätzung und -ergebnisse
Sobald wir das Modell erstellt haben, folgen alle weiteren Schritte dem gleichen Prinzip, das wir in der ersten Sitzung für Regressionen gesehen haben. Zunächst wenden wir das Modell mit dem lavaan-Befehl auf den Datensatz an. Dieser Datensatz muss dabei alle Variablen enthalten, die wir als manifeste Variablen in unserem Modell angesprochen haben.
fit1 <- lavaan(mod1, conspiracy)
## Warning in lav_model_vcov(lavmodel = lavmodel, lavsamplestats = lavsamplestats, : lavaan WARNING:
## Could not compute standard errors! The information matrix could
## not be inverted. This may be a symptom that the model is not
## identified.
Die entstehende Warnung stellt ein ernstzunehmendes Problem dar und wird Ihnen wahrscheinlich häufiger begegnen, wenn Sie Dinge mit lavaan ausprobieren. Die Warnung gibt Ihnen zunächst darüber Auskunft, wo das Problem aufgetreten ist - in diesem Fall in einer lavaan-internen Funktion namens lav_model_vcov - was aber nicht wirklich von Relevanz ist. Viel wichtiger sind die drei Informationen, die im Text der Warnmeldung enthalten sind:
Could not compute standard errors!Es konnten keine Standardfehler bestimmt werden, was bedeutet, dass Sie keinerlei Inferenzstatistik betreiben können.The information matrix could not be inverted.Der technische Grund, aus dem keine Standardfehler bestimmt werden konnten.This may be a symptom that the model is not identified.Die wahrscheinliche Ursache, an der Sie ansetzen sollten, um dieses Problem zu beheben.
Wir können uns die entstandenen Ergebnisse angucken, um herauszufinden, worin genau das Problem liegen könnte:
summary(fit1)
## lavaan 0.6.16 ended normally after 15 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 7
##
## Number of observations 2495
##
## Model Test User Model:
##
## Test statistic NA
## Degrees of freedom -1
## P-value (Unknown) NA
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## GC =~
## Q2 1.112 NA
## Q7 1.183 NA
## Q12 1.255 NA
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q2 0.808 NA
## .Q7 0.665 NA
## .Q12 0.446 NA
## GC 1.153 NA
Die folgende Zeile des Outputs zeigt uns, dass lavaan mit seiner Einschätzung vollkommen Recht hatte:
## [...]
## Degrees of freedom -1
## [...]
In diesem Fall sind die Freiheitsgrade negativ - das Modell ist also global unteridentifiziert. Bevor Sie jetzt direkt weiterlesen, um herauszufinden, wie man dieses Problem behebt, überlegen Sie kurz anhand Ihres Wissens aus dem Theorie-Teil, was genau das Problem sein könnte und wie Sie es beheben würden, wenn dieser Beitrag hier einfach vorbei wäre.
Modellidentifikation
Sie wissen inzwischen bestimmt, wo sich das Problem in diesem Fall verbirgt. Aber haben Sie trotzdem etwas Geduld - wir werden uns hier ein generelles Vorgehen in lavaan ansehen, mit dem man solche Probleme auch in komplizierteren Situationen lösen kann.
Zunächst wissen Sie aus der Theorie-Sitzung, dass die Anzahl bekannter Informationen sich einfach als $s = \frac{p(p + 1)}{2}$ berechnen lässt. Dabei ist $s$ die Anzahl bekannter Informationen (Anzahl der Varianzen und Kovarianzen der manifesten Variablen) und $p$ die Anzahl von manifesten Variablen im Modell. In unserem Fall also
3 * (3 + 1) / 2
## [1] 6
Wir können uns auch genau angucken, welche 6 Informationen wir haben, indem wir uns die Kovarianzmatrix aus unseren Daten (sample statistics) ansehen:
inspect(fit1, 'sampstat')
## $cov
## Q2 Q7 Q12
## Q2 2.233
## Q7 1.517 2.279
## Q12 1.609 1.713 2.263
Hier können wir einfach durchzählen:
## $cov
## Q2 Q7 Q12
## Q2 1
## Q7 2 4
## Q12 3 5 6
Die zu schätzenden Parameter ($t$) können wir im Pfaddiagramm abzählen:

Wenn wir uns nicht unnötig damit belasten möchten die Parameter selbst zu zählen, können wir die Anzahl natürlich auch einfach von lavaan bekommen:
inspect(fit1, 'npar')
## [1] 7
Welche Parameter das genau sind, die hier geschätzt werden, können wir auch mit inspect erfahren:
inspect(fit1, 'free')
## $lambda
## GC
## Q2 1
## Q7 2
## Q12 3
##
## $theta
## Q2 Q7 Q12
## Q2 4
## Q7 0 5
## Q12 0 0 6
##
## $psi
## GC
## GC 7
Hier sehen wir, wie in lavaan die Modell-Matrizen dargestellt werden:
$lambda: die Matrix der Faktorladungen ($\Lambda$)$theta: die Residualkovarianzmatrix ($\Theta$)$psi: die latente Kovarianzmatrix ($\Psi$)
Die latente Kovarianzmatrix haben wir in der Theoriesitzung (aus einer anderen Tradition in der Literatur kommend) als $\Phi$ bezeichnet - beides sind aber unterschiedliche Bezeichnungen für die gleiche Matrix. Das Ergebnis von inspect ist hier eine Liste dieser drei Matrizen. Wenn wir diese Liste in einem Objekt ablegen, können wir die Matrizen mit dem $ auch einzeln inspizieren:
free <- inspect(fit1, 'free')
free$theta
## Q2 Q7 Q12
## Q2 4
## Q7 0 5
## Q12 0 0 6
In theta ist z.B. die Residualvarianz von Q7 der insgesamt 5. Parameter des Modells.
Im Theorie-Abschnitt haben Sie gehört, dass in Modellen mit latenten Variablen immer entweder eine Faktorladung oder die latente Varianz fixiert werden muss, um der latenten Variable eine Skala zu geben. Entweder wird eine Faktorladung auf 1 gesetzt, um so die Skala der manifesten Variable auf die latente Variable anzuwenden, oder die latente Varianz wird auf 1 fixiert, um die latente Variable in $z$-Werten interpretierbar zu machen. In der EFA ist diese zweite Variante extrem verbreitet. In der CFA wird Ihnen die erste Variante häufiger begegnen.
Um die erste Faktorladung auf 1 zu fixieren, können wir das lavaan-Modell wie folgt ergänzen:
mod1 <- '# Faktorladungen
GC =~ 1*Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12
# Latente Varianz
GC ~~ GC'
Mit 1* legen wir den konkreten Wert der Faktorladung fest. Analog hierzu könnten wir mit 2* diese Ladung auf den Wert 2 fixieren. Das gleiche Prinzip gilt in lavaan für alle Modellparameter, z.B. auch für die Varianz der latenten Variable. Wenn wir diese, statt des Wertes der ersten Faktorladung, festlegen, erhalten wir die zweite Möglichkeit, der latente Variable eine Skala zu geben:
mod1b <- '# Faktorladungen
GC =~ Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12
# Latente Varianz
GC ~~ 1*GC'
Auch hier ist die Festlegung auf 1 üblich, weil diese Zahl viele folgenden Berechnungen dramatisch vereinfacht. Von der puren Anwendung in lavaan her können Sie aber jede beliebige Zahl vor das * schreiben.
Modellschätzung und -ergebnisse - Zweiter Versuch
Das Modell mit der eingeführten Restriktion, dass die 1. Faktorladung auf 1 fixiert ist ($\lambda_{2} = 1$), sollte nun nur noch 6 zu schätzende Parameter enthalten. Demzufolge müsste die Warnmeldung, die beim letzten Versuch entstanden ist, verschwinden:
fit1 <- lavaan(mod1, conspiracy)
So weit, so gut. Wenn wir uns wieder angucken, welche Parameter geschätzt werden mussten, sehen wir,
inspect(fit1, 'free')
## $lambda
## GC
## Q2 0
## Q7 1
## Q12 2
##
## $theta
## Q2 Q7 Q12
## Q2 3
## Q7 0 4
## Q12 0 0 5
##
## $psi
## GC
## GC 6
dass in $lambda nur noch die Ladungen von Q7 und Q12 geschätzt werden müssen. Die Ladung von Q2 ist kein Paramater des Modells mehr, weil wir diese ja auf einen Wert festgelegt haben.
Jetzt können wir uns noch einmal die Ergebnisse angucken:
summary(fit1)
## lavaan 0.6.16 ended normally after 19 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 6
##
## Number of observations 2495
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## GC =~
## Q2 1.000
## Q7 1.064 0.024 45.233 0.000
## Q12 1.129 0.024 46.637 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q2 0.808 0.030 26.795 0.000
## .Q7 0.665 0.029 22.829 0.000
## .Q12 0.446 0.028 15.894 0.000
## GC 1.425 0.062 22.939 0.000
Wir sehen, dass wir jetzt für alle Parameter Standardfehler erhalten und
## [...]
## Degrees of freedom 0
## [...]
das Modell jetzt 0 Freiheitsgrade hat. Es handelt sich also um ein gerade identifiziertes oder auch saturiertes Modell. Modelle mit $df = 0$ enthalten keine prüfbare Vereinfachung der empirischen Datenlage. Die einzelnen Parameter sind lediglich Umformulierungen von Informationen, die wir schon in den empirischen Daten vorliegen haben. Bei Eid, Gollwitzer & Schmitt (2017) finden Sie auf S. 866 - 867 eine detaillierte Darstellung, wie Sie die Parameter dieses Modells auch händisch bestimmen können.
Welche inhaltlichen Aussagen erlaubt uns diese Umformulierung jetzt? Gucken wir uns mal die Faktorladungen an:
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## GC =~
## Q2 1.000
## Q7 1.064 0.024 45.233 0.000
## Q12 1.129 0.024 46.637 0.000
## [...]
In der Ergebnisaufbereitung von lavaan hat sich gegenüber dem Regressionsmodell aus Sitzung 1 wenig geändert. Die Spalten sind nach wie vor Name der Variable, geschätzter Parameter, Standardfehler, $z$-Wert und $p$-Wert. Die Faktorladungen sind durch Überschriften gegliedert. In unserem Fall gibt es nur eine latente Variable, weswegen es nur die Überschrift GC =~ gibt. Alle darunter stehenden Ladungen beziehen sich also logischerweise auf Faktorladungen von manifesten Variable zu dieser latenten Variable. Für die Ladung der manifesten Variable Q2 sind die Spalten für den Standardfehler, $z$-Wert und $p$-Wert leer. Das liegt daran, dass wir diesen Parameter festlegen, es gibt bezüglich seiner Größe also keine Unsicherheit in der Schätzung (die im Standardfehler quantifiziert wird) und demzufolge auch keine Inferenz dazu, ob Sie bedeutsam von 0 verschieden ist. Sie ist per Definition von 0 verschieden, weil wir das - ohne empirische Unsicherheit - so festgelegt haben.
Was bedeuten diese Ladungen aber inhaltlich? Glücklicherweise hält auch für die CFA das beinahe allgemeingültige Mantra der sozialwissenschaftlichen Auswertungsverfahren: “es ist alles nur Regression”. Die Faktorladungen entsprechen hier also dem Regressionsgewicht der manifesten Variable, vorhergesagt durch die latente Variable. (Bitte beachten Sie die Richtung! Häufig wird diese Beziehung fälschlicherweise umgekehrt interpretiert - in der klassischen CFA ist aber die latente Variable die unabhängige Variable und die manifesten Variablen sind die abhängigen Variablen.) Ein Bild:
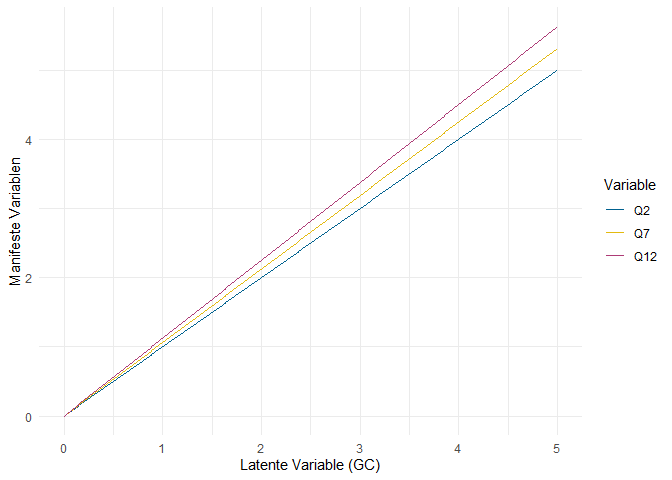
Die Ausprägung der manifesten Variable wird vorhergesagt durch die Ausprägung der latenten Variable - für $GC = 2$ sagen wir also $Q2 = 2$ vorher, weil die Faktorladung dieses Items auf 1 fixiert ist ($\lambda_{2} = 1$). Für Q7 ist die Ladung allerdings $\lambda_{7} = 1.064$, sodass die gelbe Regressionsgerade in der Abbildung ein bisschen steiler verläuft.
Das heißt, dass zwei Personen, die sich in der latenten Variable um eine Einheit unterscheiden, im vorhergesagten Ausmaß der Zustimmung zur Aussage “The power held by heads of state is second to that of small unknown groups who really control world politics” (Q2) ebenfalls um eine Einheit unterscheiden. Bezüglich der Aussage “A small, secret group of people is responsible for making all major world decisions, such as going to war” (Q7) unterscheiden sich die gleichen beiden Personen im vorhergesagten Wert aber um 1.064 Einheiten. Weil der Unterschied auf dem latenten Konstrukt GC sich also stärker in Q7 manifestiert als in Q2 (gleiche Unterschiede in GC führen zu stärkeren Unterschieden in Q7 als in Q2), spricht man davon, dass Q7 stärker auf der latenten Dimension diskriminiert. Daher wird die Faktorladung häufig als Diskriminationsparameter bezeichnet. Durch die Festlegung von $\lambda_2 = 1$ sind die “Einheiten”, von denen hier gesprochen wird, die Einheiten der Skala, die genutzt wurde, um Q2 zu erheben - in unserem Fall also eine 5-Punkt Likert-Skala.
Wie Sie in der Theorie-Sitzung gesehen haben, sind die einzelnen Messgleichungen:
Das sind letztlich also einfache lineare Gleichungen mit einer unabhängigen Variable - wie einfache Regressionen. Weil unsere Vorhersage aber mit Fehlern behaftet ist, ist jede manifeste Variable mit einem Residuum $\delta$ behaftet, deren Varianzen in der lavaan-Zusammenfassung so dargestellt werden:
## [...]
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q2 0.808 0.030 26.795 0.000
## .Q7 0.665 0.029 22.829 0.000
## .Q12 0.446 0.028 15.894 0.000
## GC 1.425 0.062 22.939 0.000
Wie schon bei der Regression in Sitzung 1 wird mit dem . vor dem Variablennamen deutlich gemacht, dass diese Variable in irgendeiner Form im Modell eine abhängige Variable ist. Das heißt, dass es sich bei der berichteten Varianz um eine Residualvarianz handelt. Für GC ist das nicht der Fall, weil - wie gerade besprochen - die latente Variable in der CFA die unabhängige Variable ist.
Was bringt uns das Wissen um die latente Varianz und die Residualvarianzen inhaltlich? Ein Kernkonzept der klassischen Messtheorie (KTT; auch, klassische Testtheorie) ist die Reliabilität, also das Ausmaß in dem unser Instrument wahre Unterschiede zwischen Personen misst. Für unser Modell lässt sie sich einfach ausdrücken, für Q7 z.B.:
Besonders die erste Version der Reliabilitätsbestimmung sieht dem klassischen $R^2$ einer Regression sehr ähnlich - was daran liegt, dass es das Gleiche ist. Wenn wir also die Reliabilität einer unserer manifesten Variablen bestimmen wollen, können wir entweder händisch die Paramater verrechnen, oder uns das $R^2$ von lavaan ausgeben lassen, so wie wir es in der 1. Sitzung für die Regression gemacht haben:
inspect(fit1, 'rsquare')
## Q2 Q7 Q12
## 0.638 0.708 0.803
Weil $R^2$ und Reliabilitäten in vielen Fällen von Interesse sind, können wir auch die Modellzusammenfassung um diesen Abschnitt erweitern, indem wir in der summary-Funktion das Zusatzargument rsq auf TRUE setzen. Dann erhalten wir am Ende der Modellzusammenfassung die $R^2$-Schätzungen:
summary(fit1, rsq = TRUE)
## [...]
## R-Square:
## Estimate
## Q2 0.638
## Q7 0.708
## Q12 0.803
In diesem Fall ist die Reliabilität von Q7 also 0.708. Das heißt, dass ca. 71% der interindividuellen Unterschiede, die wir bezüglich der Zustimmung zur Aussage von Q7 beobachten können, auf wahre Unterschiede in der latenten Dimension malevolent global conspiracies attribuiert werden können. Die verbleibenden 29% gehen auf Messfehler zurück. Was uns die CFA hier über das Ausmaß der klassischen Reliabilitätsbestimmung, wie Sie sie wahrscheinlich im Bachelorstudium gelernt haben, hinaus ermöglicht, ist, dass wir die Reliabilität jedes einzelnen Items eines Fragebogens bestimmen können, also nicht nur die der gesamten Skala.
Mittelwertsstruktur
Wie Ihnen vielleicht aufgefallen ist, war in unseren gesammelten Ergebnissen bisher nirgends die Rede von Intercepts oder Mittelwerten. Das liegt daran, dass wir auch diese explizit in die Modellsyntax aufnehmen müssten. Üblicherweise werden in der CFA die Intercepts aller manifesten Variablen als Parameter aufgenommen, der Mittelwert der latenten Variable aber auf 0 fixiert. Dadurch handelt es sich bei der latenten Variable in der CFA im Normalfall um eine zentrierte Variable.
Wie wir bei der Regression schon gesehen haben, können wir Intercepts und Mittelwerte dadurch anfordern, dass wir Variablen auf eine Konstante (idealerweise die 1) regressieren. Das bedeutet also, dass wir unser Modell um einen weiteren Abschnitt erweitern müssen:
mod2 <- '
# Faktorladungen
GC =~ 1*Q2 + Q7 + Q12
# Residualvarianzen
Q2 ~~ Q2
Q7 ~~ Q7
Q12 ~~ Q12
# Latente Varianz
GC ~~ GC
# Intercepts
Q2 ~ 1
Q7 ~ 1
Q12 ~ 1'
Wie immer, müssen wir dieses Modell im 2. Schritt auf die Daten anwenden, bevor wir uns Ergebnisse ausgeben lassen können:
fit2 <- lavaan(mod2, conspiracy)
Mit dem summary Befehl können wir uns wieder die Modellzusammenfassung ansehen. Im Vergleich zum bisherigen fit1 kommt ein Abschnitt dazu:
summary(fit2)
## [...]
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .Q2 2.964 0.030 99.057 0.000
## .Q7 2.667 0.030 88.241 0.000
## .Q12 2.645 0.030 87.812 0.000
## GC 0.000
## [...]
Wie bei der Regression und bei den Varianzen schon gesehen, markiert der . Variablen, die im Modell abhängige Variablen sind, sodass der dargestellte Wert als Intercept (sprich bedingter Mittelwert) und nicht als Mittelwert interpretiert werden sollte. Wie bei Intercepts in Regressionen auch, ist das hier dargestellte Intercept von Q7 der Wert, den wir erwarten, wenn eine Person auf dem Prädiktor (GC) den Wert 0 hat. Durch die Festlegung des Mittelwerts von GC auf 0 bedeutet das Intercept also, dass es der erwartete Wert einer durchschnittlichen Person ist. Genau genommen ist das dann in diesem Fall also lediglich eine sehr umständliche Variante, doch den Mittelwert von Q7 zu meinen. Wenn wir die Darstellung als Regression um diese Intercepts erweitern, ergibt sich folgendes Bild:
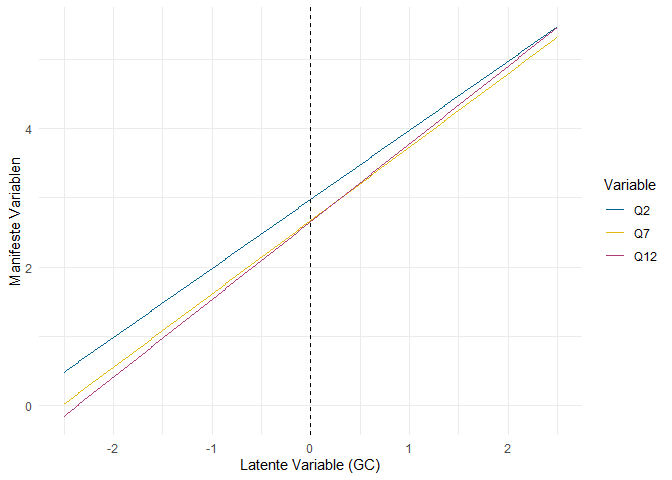
Die gestrichelte Linie stellt den Mittelwert der latenten Variable dar. Der Punkt, an dem die jeweilige Regressionsgerade diese Linie schneidet, ist also das Intercept. Erneut ist eine berechtigte Frage: “Aber was soll mir das jetzt bringen?” Die Intercepts werden im Rahmen der klassischen Testtheorie als Leichtigkeitsparameter interpretiert. Der Aussage “The power held by heads of state is second to that of small unknown groups who really control world politics” (Q2) weist eine Person mit durchschnittlicher Ausprägung auf der Dimension malevolent global conspiracies einen Wahrheitsgehalt von 2.964 zu (auf einer Skala von 1 bis 5). Die gleiche, durchschnittliche Person schätzt den Wahrheitsgehalt der Aussage “A small, secret group of people is responsible for making all major world decisions, such as going to war” (Q7) auf einer Skala von 1 bis 5 mit 2.667 ein. Q2 wird also in größerem Ausmaß zugestimmt - die Aussage ist leichter zu bejahen, daher die Bezeichnung als Leichtigkeitsparameter. Manchmal wird dieser Parameter auch ins Verhältnis zur Range der Skala gesetzt (also zur Differenz zwischen Maximum und Minimum der Skala) und dann in $%$ interpretiert. Vielleicht kennen Sie diesen Koeffizienten auch unter dem Namen Itemschwierigkeit. Da allerdings zumeist die Leichtigkeit quantifiziert wird, macht das die Sache kompliziert. Auch müssen wir hier kein Verhältnis zur Range der Skala verwenden, da alle Items auf der gleichen gemessen wurden und damit die Werte direkt vergleichbar sind.
Zweifaktorielles Modell
Wie wir im letzten Abschnitt gesehen haben, hatte das Modell für die Facette malevolent global conspiracies 0 Freiheitsgrade und war deswegen lediglich eine Umformulierung der empirischen Datenlage. Um uns mit Modellen zu beschäftigen, die prüfbare Behauptungen darstellen, können wir zwei Wege beschreiten.
Wir können in das Modell Einschränkungen einführen, die die Beziehung zwischen den drei Items Q2, Q7 und Q12 und der latenten Variable GC präzisieren. Diese Messmodelle der Klassischen Testtheorie werden im Appendix besprochen. Wenn Sie Ihre Kenntnis über die CFA und ihre Umsetzung in lavaan also vertiefen wollen, finden Sie dort eine detaillierte Darstellung der hierarchischen Messmodelle und der Einführung von Paramatergleichsetzungen in lavaan.
Die zweite Möglichkeit, um die behauptete Messstruktur des Konstrukts in prüfbare Aussagen zu überführen, ist, dieses gegenüber anderen psychologischen Konstrukten und Aussagen explizit abzugrenzen. Wenn die drei Aussagen in Q2, Q7 und Q12 Manifestierungen der Facette malevolent global conspiracies darstellen, sollte sie in einer CFA z.B. von der Facette control of information (Q5, Q10, Q15) klar unterscheidbar sein. Wenn sie das nicht wären, müssten wir die theoretische Konzeption der verschwörungstheoretischen Überzeugungen als fünfdimensionales Konstrukt revidieren und z.B. mit einer EFA untersuchen, welche Dimensionen sich empirisch unterscheiden lassen. Wie Sie am Titel dieses Abschnitts erkennen konnten, befassen wir uns hier mit diesem Vorgehen.
Vereinfachte Modellsyntax
Im letzten Abschnitt sind wir den beschwerlichen Weg gegangen, das Modell in seiner Gänze in der lavaan-Modellsyntax darzustellen. Wie erwähnt gibt es aber einige Dinge, die in der breiten Masse der CFA-Modelle in gleicher Weise gehandhabt werden: üblicherweise wird die Faktorladung der 1. manifesten Variable auf 1 fixiert. Für alle abhängigen Variablen werden meistens Residualvarianzen geschätzt. Wenn wir latente Variablen definieren, sollen diese auch Varianz haben. Dieses Verhalten kann in lavaan erzeugt werden, sodass wir uns sparen können, alle Elemente im Modell aufzulisten. Dafür können wir ein sparsames Modell definieren und an einen von drei Befehlen weitergeben:
cfa: enthält Voreinstellungen, die in der Anwendung von CFAs üblich sindsem: macht genau das Gleiche wiecfagrowth: enthält Voreinstellungen für Wachstumskurvenmodelle, eine spezielle Form der Modellierung von Längsschnittdaten.
Warum gibt es cfa und sem? Offiziell sind beide implementiert, weil es in Zukunft passieren könnte, dass unterschiedliche Voreinstellungen für konfirmatorische Faktorenanalysen und Strukturgleichungsmodelle implementiert werden. Derzeit ist das nicht der Fall, sodass beide Funktionen austauschbar verwandt werden können. Ich nutze sie meistens an unterschiedlichen Stellen, um in meinen lavaan-Skripten schnell sehen zu können, was an welcher Stelle passiert.
In jedem Fall funktionieren cfa, sem und growth genauso wie der allgemeine lavaan-Befehl, mit dem wir bisher gearbeitet haben. Der Unterschied besteht lediglich darin, dass Voreinstellungen gesetzt werden, die den Prozess der Modellierung stark abkürzen. Mit der Hilfefunktion ?cfa können Sie sich ansehen, welche Voreinstellungen vorgenommen werden. Da steht:
The cfa function is a wrapper for the more general lavaan function, using the following default arguments:
int.ov.free = TRUE,int.lv.free = FALSE,auto.fix.first = TRUE(unlessstd.lv = TRUE),auto.fix.single = TRUE,auto.var = TRUE,auto.cov.lv.x = TRUE,auto.efa = TRUE,auto.th = TRUE,auto.delta = TRUE, andauto.cov.y = TRUE.
Eine Übersicht über alle möglichen Einstellung in lavaan finden Sie mit ?lavOptions. Für uns sind folgende Aussagen von zentraler Bedeutung:
auto.fix.first = TRUE: die erste Faktorladung jeder latenten Variable wird automatisch fixiertauto.var = TRUE: die Varianz latenter Variablen und Residualvarianzen manifester Variablen werden automatisch frei geschätztauto.cov.lv.x = TRUE: Kovarianzen zwischen exogenen latenten Variablen werden automatisch frei geschätzt.
Das heißt, dass dies Dinge sind, die wir in der Modellsyntax nicht mehr explizit ansprechen müssen. Die Syntax des mod1 aus dem letzten Abschnitt verkürzt sich daher auf nur eine Zeile:
mod1_simple <- 'GC =~ Q2 + Q7 + Q12'
Wenn Sie dieses Modell an cfa weitergeben, entstehen genau die gleichen Ergebnisse, die wir im zweiten Anlauf erzeugt hatten. Probieren Sie es gerne aus, um zu prüfen, ob Sie angeschwindelt wurden. Was hierbei erneut fehlt, ist die Mittelwertsstruktur, die nicht per Voreinstellung mit in das Modell aufgenommen wird. Diese können wir aber per Argument von cfa anfordern:
fit2_simple <- cfa(mod1_simple, conspiracy,
meanstructure = TRUE)
Dann erhalten wir erneut den zusätzlichen Abschnitt mit den Intercepts, den wir im letzten Abschnitt per Hand erzeugt hatten.
Modellierung mit zwei latenten Variablen
Diese neu gefundene Leichtigkeit der Modellierung können wir direkt nutzen, um ein zweifaktorielles Modell für die beiden Facetten malevolent global conspiracies und control of information aufzustellen. Zu unseren bisherigen drei Items (Q2, Q7 und Q12) kommen die folgenden drei dazu:
| Nr. | Itemformulierung |
|---|---|
| 5 | Groups of scientists manipulate, fabricate, or suppress evidence in order to deceive the public |
| 10 | New and advanced technology which would harm current industry is being suppressed |
| 15 | A lot of important information is deliberately concealed from the public out of self-interest |
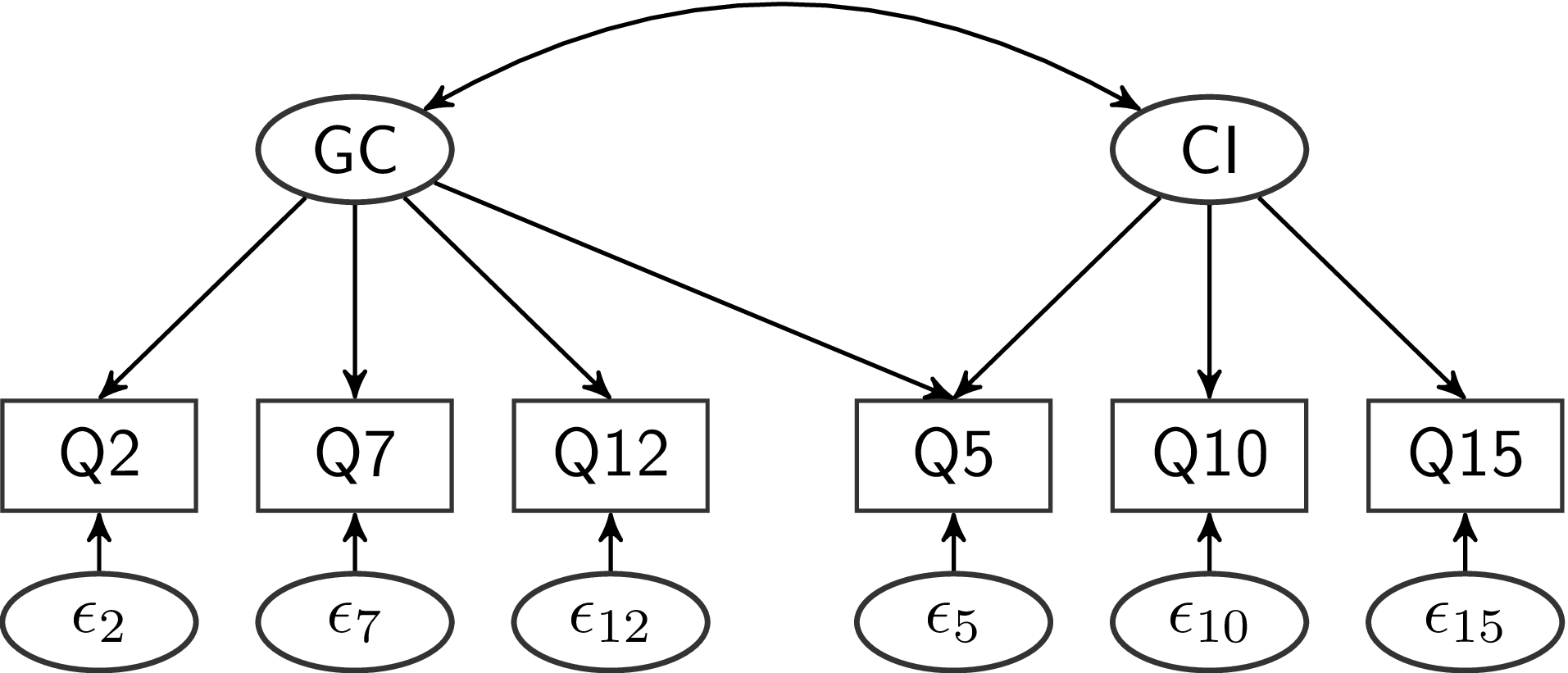
Um die beiden Facetten voneinander abzugrenzen, stellen wir ein Modell mit zwei latenten Variablen auf, welches als Pfaddiagramm so aussieht:
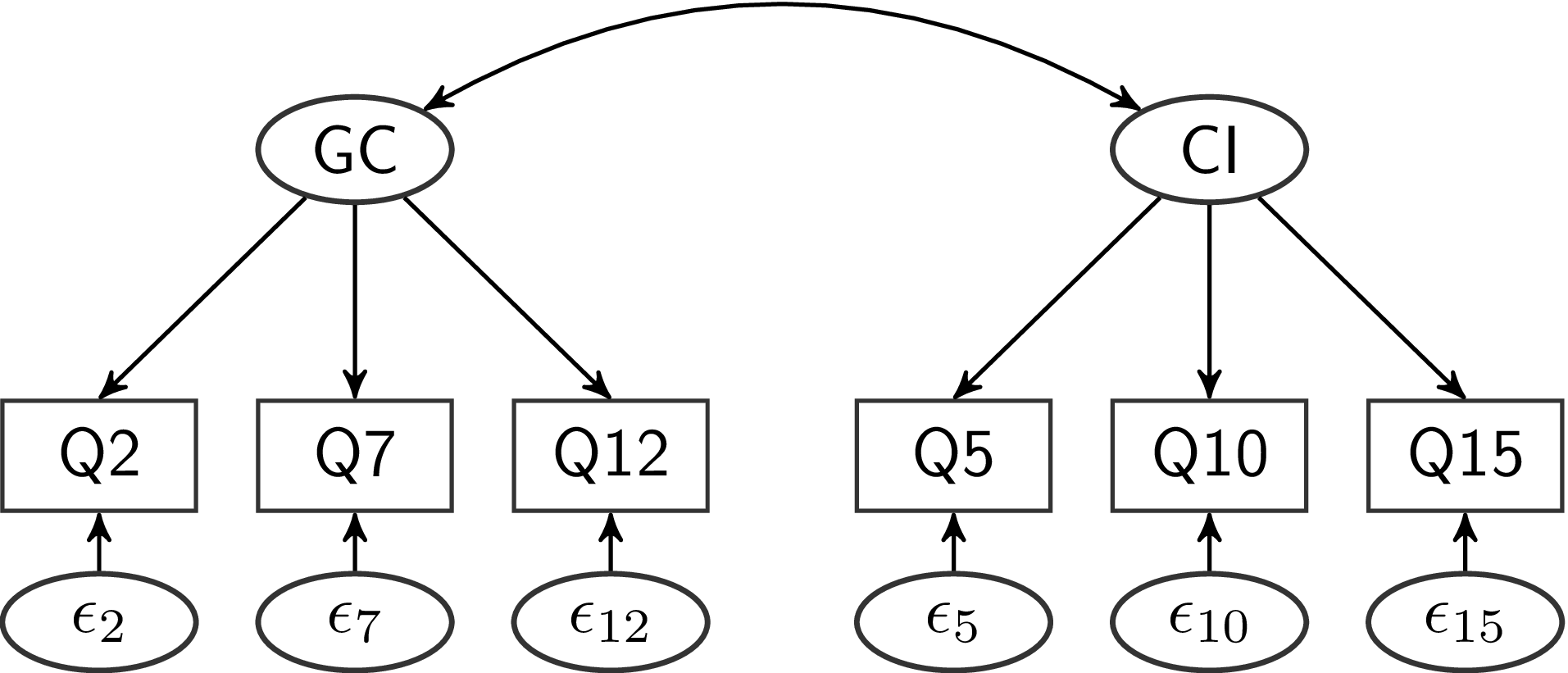
Inhaltlich wird mit diesem Modell behauptet, dass die Zustimmung zu den sechs Aussagen sich auf zwei verschiedene Überzeugungen von Personen zurückführen lässt. Die Erste stellt die Überzeugung dar, dass es eine kleine, elitäre Gruppe von Personen gibt, die das Weltgeschehen im Geheimen steuert. Diese Überzeugung äußert sich in der Zustimmung zu den drei Aussagen in Q2, Q7 und Q12. Die zweite Überzeugung beinhaltet, dass technologischer und wissenschaftlicher Fortschritt absichtlich verschleiert wird, um die Interessen einiger weniger zu schützen. Diese Überzeugung äußert sich dann in der Zustimmung zu den Aussagen in Q5, Q10 und Q15. Zusätzlich behauptet dieses Modell aber auch, dass sich eine Überzeugung bezüglich malevolent global conspiracies nicht in der Zustimmung zu den Aussagen in Q5, Q10 oder Q15 wiederfinden lässt. Zusammenhänge der Zustimmung zu den Aussagen in Q12 (“Certain significant events have been the result of the activity of a small group who secretly manipulate world events”) und Q10 (“New and advanced technology which would harm current industry is being suppressed”) sollen nur dadurch entstehen, dass die beiden grundlegenden (latenten) Überzeugungen miteinander zusammenhängen können. Diese latente Korrelation wird im Pfadmodell durch den Doppelpfeil kenntlich gemacht.
Um dieses Modell in lavaan zu implementieren, brauchen wir nur die folgenden Zeilen:
mod_two <- '
GC =~ Q2 + Q7 + Q12
CI =~ Q5 + Q10 + Q15'
Durch die oben besprochenen Voreinstellungen werden die restlichen Modellelemente ergänzt, wenn wir cfa oder sem nutzen, um das Modell zu schätzen.
fit_two <- cfa(mod_two, conspiracy,
meanstructure = TRUE)
Wir können auch hier wieder summary und inspect benutzen, um uns detaillierte Informationen über die Ergebnisse zu beschaffen.
# Allgemeiner Überblick
summary(fit_two)
## lavaan 0.6.16 ended normally after 31 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 19
##
## Number of observations 2495
##
## Model Test User Model:
##
## Test statistic 33.018
## Degrees of freedom 8
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## GC =~
## Q2 1.000
## Q7 1.055 0.023 46.149 0.000
## Q12 1.118 0.023 48.654 0.000
## CI =~
## Q5 1.000
## Q10 0.846 0.034 25.151 0.000
## Q15 0.695 0.027 25.717 0.000
##
## Covariances:
## Estimate Std.Err z-value P(>|z|)
## GC ~~
## CI 0.930 0.043 21.588 0.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .Q2 2.964 0.030 99.057 0.000
## .Q7 2.667 0.030 88.241 0.000
## .Q12 2.645 0.030 87.812 0.000
## .Q5 3.254 0.029 110.456 0.000
## .Q10 3.502 0.028 125.994 0.000
## .Q15 4.228 0.022 191.223 0.000
## GC 0.000
## CI 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q2 0.788 0.029 27.315 0.000
## .Q7 0.671 0.027 24.494 0.000
## .Q12 0.458 0.025 18.257 0.000
## .Q5 1.088 0.045 24.418 0.000
## .Q10 1.156 0.041 28.061 0.000
## .Q15 0.699 0.026 27.188 0.000
## GC 1.445 0.062 23.339 0.000
## CI 1.077 0.062 17.370 0.000
# Reliabilität der sechs Aussagen
inspect(fit_two, 'rsquare')
## Q2 Q7 Q12 Q5 Q10 Q15
## 0.647 0.706 0.797 0.497 0.400 0.427
Die summary enthält nun den neuen Abschnitt Covariances, der, wie Sie vermutlich erraten können, Kovarianzen zwischen den latenten Variablen enthält. inspect erlaubt uns eine extrem detaillierte Untersuchung unserer Ergebnisse. Ein Blick in die Hilfe mit ?inspect verrät, dass wir uns aber auch z.B. mit what = 'cor.lv' die “correlations of latent variables” anzeigen lassen können:
inspect(fit_two, 'cor.lv')
## GC CI
## GC 1.000
## CI 0.745 1.000
Parametertabelle & erweiterte Zusammenfassung
Bisher haben wir hauptsächlich mit inspect gearbeitet, um uns die Ergebnisse unserer Modelle detailliert anzugucken. In den allermeisten Fällen ist das auch der sinnvollste Ansatz. Trotzdem ist es immer gut, auch Alternativen zu kennen. Die erste sinnvolle alternative Darstellungsart von Ergebnissen ist die Parametertabelle, die wir in lavaan über paramaterEstimates anfordern können. Für das zweifaktorielle Modell sieht diese so aus:
parameterEstimates(fit_two)
## lhs op rhs est se z pvalue ci.lower ci.upper
## 1 GC =~ Q2 1.000 0.000 NA NA 1.000 1.000
## 2 GC =~ Q7 1.055 0.023 46.149 0 1.010 1.100
## 3 GC =~ Q12 1.118 0.023 48.654 0 1.073 1.163
## 4 CI =~ Q5 1.000 0.000 NA NA 1.000 1.000
## 5 CI =~ Q10 0.846 0.034 25.151 0 0.780 0.912
## 6 CI =~ Q15 0.695 0.027 25.717 0 0.642 0.748
## 7 Q2 ~~ Q2 0.788 0.029 27.315 0 0.731 0.845
## 8 Q7 ~~ Q7 0.671 0.027 24.494 0 0.617 0.724
## 9 Q12 ~~ Q12 0.458 0.025 18.257 0 0.409 0.508
## 10 Q5 ~~ Q5 1.088 0.045 24.418 0 1.001 1.176
## 11 Q10 ~~ Q10 1.156 0.041 28.061 0 1.075 1.237
## 12 Q15 ~~ Q15 0.699 0.026 27.188 0 0.649 0.749
## 13 GC ~~ GC 1.445 0.062 23.339 0 1.324 1.567
## 14 CI ~~ CI 1.077 0.062 17.370 0 0.956 1.199
## 15 GC ~~ CI 0.930 0.043 21.588 0 0.845 1.014
## 16 Q2 ~1 2.964 0.030 99.057 0 2.905 3.022
## 17 Q7 ~1 2.667 0.030 88.241 0 2.608 2.726
## 18 Q12 ~1 2.645 0.030 87.812 0 2.586 2.704
## 19 Q5 ~1 3.254 0.029 110.456 0 3.196 3.312
## 20 Q10 ~1 3.502 0.028 125.994 0 3.448 3.557
## 21 Q15 ~1 4.228 0.022 191.223 0 4.184 4.271
## 22 GC ~1 0.000 0.000 NA NA 0.000 0.000
## 23 CI ~1 0.000 0.000 NA NA 0.000 0.000
Per Voreinstellung bekommen wir damit einen Datensatz, der 9 Spalten hat und aus so vielen Zeilen besteht, wie unser Modell Parameter hat (in diesem Fall 23). Die ersten drei Spalten (lhs, op, rhs) sind dazu da, den Parameter zu kennzeichnen, der in dieser Zeile dargestellt wird. Dafür gibt op den operator - also die Art des Parameters - an. In Zeile eins steht da ein =~ also eine Faktorladung. lhs steht für left hand side und gibt an, welche Variable links des operators steht - rhs ist dann logischerweise die right hand side. Dadurch, dass hier in drei Spalten des Datensatzes zwischen den Parametern unterschieden wird, können wir sehr einfach und schnell die uns schon bekannten Verfahren nutzen, um die Parameter herauszufiltern, die uns interessieren. Z.B. können wir uns explizit nur die Intercepts und Mittelwerte aus der Parametertabelle ausgeben lassen. Dazu können wir die gesamte Tabelle in ein Objekt namens para ablegen und dann mit subset oder den eckigen Klammern (oder z.B. filter, falls Sie mit dplyr arbeiten) eine entsprechende Auswahl treffen. Intercepts und Mittelwerte sind z.B. dadurch gekennzeichnet, dass ihr operator ~1 ist:
# Parameter in Objekt ablegen
para <- parameterEstimates(fit_two)
# Mittelwerte und Intercepts ausgeben
para[para$op == '~1', ]
## lhs op rhs est se z pvalue ci.lower ci.upper
## 16 Q2 ~1 2.964 0.030 99.057 0 2.905 3.022
## 17 Q7 ~1 2.667 0.030 88.241 0 2.608 2.726
## 18 Q12 ~1 2.645 0.030 87.812 0 2.586 2.704
## 19 Q5 ~1 3.254 0.029 110.456 0 3.196 3.312
## 20 Q10 ~1 3.502 0.028 125.994 0 3.448 3.557
## 21 Q15 ~1 4.228 0.022 191.223 0 4.184 4.271
## 22 GC ~1 0.000 0.000 NA NA 0.000 0.000
## 23 CI ~1 0.000 0.000 NA NA 0.000 0.000
Über die Hilfe zu parameterEstimates können wir wieder sehen, welche Argumente diese Funktion entgegennimmt. Ein hilfreiches Argument ist z.B. standardized = TRUE, mit dem wir zusätzlich zu den normalen Ergebnissen auch noch die standardisierten Modellergebnisse anfordern können.
Wenn Sie die Aufbereitung von summary eigentlich mögen, aber sich wünschen würden, dass es einfach ein paar zusätzliche Informationen gäbe, können Sie auch die summary um zusätzliche Argumente ergänzen. Wir hatten das vorhin schon für die Varianzaufklärung bzw. Reliabilität gemacht - aber das Prinzip lässt sich auf viele Aspekte der Modellergebnisse erweitern. Im Folgenden ein paar interessante Argumente, um die wir die summary erweitern können:
rsquare = TRUE: Varianzaufklärung bzw. Reliabilitätstandardized = TRUE: Standardisierte Parameterci = TRUE: Konfidenzintervalle um die Parameterschätzerfit.measures = TRUE: Kennwerte zur Modellpassung bzw. -güte.
Wenn wir die Ergebniszusammenfassung z.B. um Konfidenzintervalle erweitern, sieht der Abschnitt der Faktorladungen so aus:
summary(fit_two, ci = TRUE)
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) ci.lower
## GC =~
## Q2 1.000 1.000
## Q7 1.055 0.023 46.149 0.000 1.010
## Q12 1.118 0.023 48.654 0.000 1.073
## CI =~
## Q5 1.000 1.000
## Q10 0.846 0.034 25.151 0.000 0.780
## Q15 0.695 0.027 25.717 0.000 0.642
## ci.upper
##
## 1.000
## 1.100
## 1.163
##
## 1.000
## 0.912
## 0.748
## [...]
Was genau es mit den Fit-Statistiken auf sich hat, gucken wir uns im nächsten Abschnitt an.
Model Fit
Im letzten Abschnitt hatten wir kurz die inhaltliche Modellimplikation besprochen und dabei festgehalten, dass das Zweifaktorenmodell die Behauptung aufstellt, dass der Zustimmung zu den Aussagen in Q2, Q7 und Q12 eine gemeinsame latente Variable zugrunde liegt und die Zustimmung zu den Aussagen in Q5, Q10 und Q15 von einer anderen, unterscheidbaren latenten Variable abhängt. Wie haltbar ist diese Aussage? Nach klassischer Popper’scher Vorstellung müssen wir eine Theorie aufstellen (unser Modell), diese mit der Empirie abgleichen (unsere Daten) und dann entscheiden, ob unsere Theorie verworfen werden muss oder beibehalten werden kann. Bei konfirmatorischer Faktorenanalyse und Strukturgleichungsmodellierung wird diese Entscheidung anhand des Model Fits getroffen.
Wie Sie in der inhaltlichen Sitzung bereits erfahren haben, wird die Modellpassung über den Vergleich der modellimplizierten und der empirischen Kovarianzmatrix bestimmt. Wenn die empirische Kovarianzmatrix $\mathbf{S}$ zu stark von unserer Modellimplikation $\mathbf{\Sigma(\widehat{\vartheta})}$ abweicht, muss das Modell verworfen werden. Wie die beiden Matrizen aussehen, können wir natürlich über inspect erfahren:
# Empirische Matrix
inspect(fit_two, 'sampstat')$cov
## Q2 Q7 Q12 Q5 Q10 Q15
## Q2 2.233
## Q7 1.517 2.279
## Q12 1.609 1.713 2.263
## Q5 1.006 0.991 1.089 2.165
## Q10 0.789 0.815 0.844 0.874 1.928
## Q15 0.659 0.648 0.681 0.733 0.689 1.220
# Modellimplizierte Matrix
inspect(fit_two, 'cov.ov')
## Q2 Q7 Q12 Q5 Q10 Q15
## Q2 2.233
## Q7 1.525 2.279
## Q12 1.615 1.704 2.263
## Q5 0.930 0.981 1.039 2.165
## Q10 0.787 0.830 0.880 0.912 1.928
## Q15 0.646 0.682 0.722 0.749 0.634 1.220
$\chi^2$ Modeltest
Den meisten Fit-Statistiken liegt die Fitfunktion $F$ zugrunde. Üblicherweise werden CFAs mit dem Maximum-Likelihood Verfahren geschätzt, sodass diese Fitfunktion als $F_{ML}[\mathbf{\Sigma(\widehat{\vartheta})}, \mathbf{S}]$ notiert wird. Wie Sie an der Notation sehen, gehen in diese Fitfunktion die beiden oben aufgeführten Matrizen ein. Wie im Beitrag zur EFA, spezifischer im Abschnitt ML-EFA, besprochen, ist das Ziel der Schätzung im Groben, dass die Wahrscheinlichkeit der Daten, gegeben unser Modell, maximiert wird. Um die Multiplikation, die notwendig ist, um die Wahrscheinlichkeiten unabhängiger Zufallsereignisse zu bestimmen, zu umgehen, wird in der Statstik lieber mit Logarithmen gearbeitet. Diese kann man einfach addieren, sodass das Problem vereinfacht wird, ohne es wirklich zu ändern. Der Logarithmus der Likelihood wird dann einfach als LogLikelihood bezeichnet.
Um alle möglichen Fit-Statistiken für ein Modell zu bestimmen, können wir wieder mit inspect arbeiten. Weil hier ein ziemlicher Wust aus Zahlen entsteht, legen wir das Ergebnis erst einmal in einem Objekt ab:
modelfit <- inspect(fit_two, 'fit.measures')
Um jetzt z.B. die LogLikelihood aus diesem Objekt zu ziehen, können wir diese über eckige Klammern auswählen. Dazu können wir erst einmal gucken, welche Werte in dem Objekt abgespeichert sind:
# Namen der Fitstatistiken
names(modelfit)
## [1] "npar" "fmin"
## [3] "chisq" "df"
## [5] "pvalue" "baseline.chisq"
## [7] "baseline.df" "baseline.pvalue"
## [9] "cfi" "tli"
## [11] "nnfi" "rfi"
## [13] "nfi" "pnfi"
## [15] "ifi" "rni"
## [17] "logl" "unrestricted.logl"
## [19] "aic" "bic"
## [21] "ntotal" "bic2"
## [23] "rmsea" "rmsea.ci.lower"
## [25] "rmsea.ci.upper" "rmsea.ci.level"
## [27] "rmsea.pvalue" "rmsea.close.h0"
## [29] "rmsea.notclose.pvalue" "rmsea.notclose.h0"
## [31] "rmr" "rmr_nomean"
## [33] "srmr" "srmr_bentler"
## [35] "srmr_bentler_nomean" "crmr"
## [37] "crmr_nomean" "srmr_mplus"
## [39] "srmr_mplus_nomean" "cn_05"
## [41] "cn_01" "gfi"
## [43] "agfi" "pgfi"
## [45] "mfi" "ecvi"
# LogLikelihood
modelfit['logl']
## logl
## -23068.19
Weil diese Zahl als solche relativ schlecht interpretierbar ist, wurden etliche Möglichkeiten entwickelt, um sie in Effektstärken oder in inferenzstatistische Prüfung der Modellpassung zu überführen. In fast allen dieser Maße wird dabei mit einem unrestringierten Referenzmodell verglichen. “Unrestringiert” heißt hier einfach, dass wir keine Einschränkungen in das Modell einführen - etwas, dass wir im Abschnitt zur Modellidentifikation schon gesehen haben und als saturiertes oder gerade identifiziertes Modell bezeichnet hatten. Wie dort besprochen, sind solche Modell nicht prüfbar, weil sie nur eine Umformulierung der Daten darstellen. Wenn wir so etwas aber als Referenz nutzen, um unser Modell damit zu vergleichen, bekommen wir eine Vorstellung davon, wie gut unser Modell ist. Wenn Sie die Namen der Werte in modelfit durchgucken, sehen Sie, dass die LogLikelihood des unrestringierten Modells als unrestricted.logl bezeichnet wird:
# LogLikelihood unrestringiertes Modell
modelfit['unrestricted.logl']
## unrestricted.logl
## -23051.68
Beinahe als sei es dafür gemacht, folgt die doppelte Differenz dieser beiden LogLikelihoods einer uns bekannten Verteilung (der $\chi^2$-Verteilung), was uns erlaubt, Inferenzstatistik zu betreiben, weil wir bei bekannten Verteilungen Ablehnungsbereiche definieren können. Die Form der $\chi^2$-Verteilung hängt, wie z.B. auch die klassische $t$-Verteilung, von Freiheitsgraden ab. Die Freiheitsgrade, die bestimmen, mit welcher Form der $\chi^2$-Verteilung wir die Differenz der LogLikelihoods prüfen können, entspricht - erneut beinahe auf magische Weise - genau der Differenz aus gegebenen Informationen und zu schätzenden Parametern des Modells. In modelfit sind diese Freiheitsgrade unter df (degrees of freedom) zu finden:
modelfit['df']
## df
## 8
Die $\chi^2$-Verteilung mit 8 Freiheitsgraden sieht so aus:
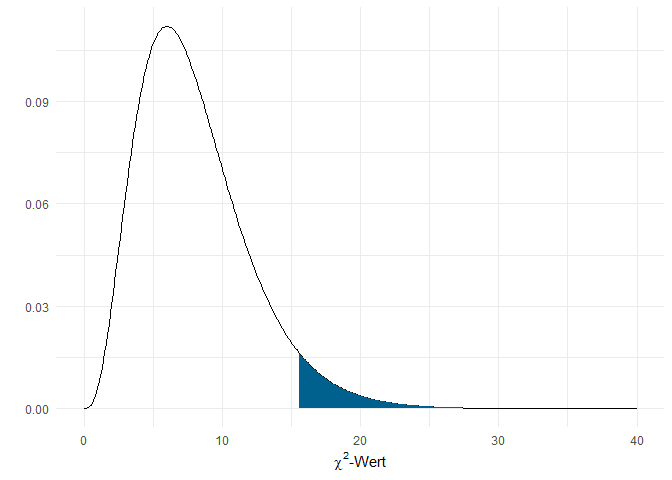
Der blau eingefärbte Bereich ist der Ablehnungsbereich bei einem $\alpha$-Fehlerniveau von 5%. Der kritische Wert liegt hier bei gerundet 15.51. Wenn die doppelte Differenz der LogLikelihoods des unrestringierten und unseres Modells diesen kritischen Wert überschreitet, muss also die Nullhypothese (unser Modell) verworfen werden:
# Empirische Prüfgröße
emp <- 2 * (modelfit['unrestricted.logl'] - modelfit['logl'])
emp
## unrestricted.logl
## 33.01761
# p-Wert
pchisq(q = emp, df = 8, lower.tail = FALSE)
## unrestricted.logl
## 6.113991e-05
In diesem Fall wird unser Modell also verworfen. Wie Ihnen bestimmt bewusst ist, können wir uns den Prozess der händischen Bestimmung des $p$-Wertes in lavaan auch sparen, weil der $\chi^2$-Test sowohl in modelfit, als auch in der summary direkt mit ausgegeben wird:
# Aus inspect:
modelfit[c('chisq', 'df', 'pvalue')]
## chisq df pvalue
## 3.301761e+01 8.000000e+00 6.113991e-05
# Aufruf des lavaan Objekts
fit_two
## lavaan 0.6.16 ended normally after 31 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 19
##
## Number of observations 2495
##
## Model Test User Model:
##
## Test statistic 33.018
## Degrees of freedom 8
## P-value (Chi-square) 0.000
Wir haben uns also leider nicht verrechnet, dieses Modell wird verworfen.
Deskriptive und relative Gütekriterien
Wie jeder inferenzstatistischer Test ist auch der $\chi^2$-Modelltest von der Stichprobengröße abhängig. Komplexe Modelle, die an kleinen Stichproben geprüft werden, müssen nicht verworfen werden, einfache Modelle, die an riesigen Stichproben ausprobiert werden, werden auch bei sehr kleinen Diskrepanzen zwischen Annahme und Realität verworfen. Weil prinzipiell nicht belohnt werden soll, so wenige Informationen aus der Empirie heranzuziehen wie möglich (also eine möglichst kleine Stichprobe zu haben), gibt es diverse Gütekriterien, mit denen versucht wird, die Beurteilung eines Modells von der Größe der Stichprobe unabhängig zu machen.
Die bekanntesten deskriptiven Gütekriterien sind der RMSEA (root mean square error of approximation) und der SRMR (standardized root mean square residual). Der RMSEA ist eine Skalierung von $F_{ML}$ anhand der Stichprobengröße, welcher nur Werte von 0 oder größer annehmen kann. Der SRMR hingegen ist eine standardisierte Summe der Differenzen zwischen den beiden Matrizen $\mathbf{S}$ und $\mathbf{\Sigma(\widehat{\vartheta})}$, hängt also nicht direkt von $F_{ML}$ ab. Das hat den Vorteil, dass der SRMR auch bei anderen Schätzverfahren zum Einsatz kommen kann und trotzdem über verschiedene Situationen hinweg vergleichbar bleibt. Allerdings haben Studien gezeigt, dass der RMSEA eine höhere Trennschärfe hat, um zwischen “guten” und “schlechten” Modellen zu unterscheiden. Für beide gilt: je höher der Werte, desto schlechter die Modellpassung. Auch diese beiden Kriterien sind in modelfit enthalten:
modelfit[c('rmsea', 'srmr')]
## rmsea srmr
## 0.03540321 0.01356834
Für beide wird häufig das Kriterium von $< .05$ als Daumenregel für gute Modellpassung angenommen. Deskriptiv scheint unser Modell anhand dieser Regeln also sehr gut zu sein.
Als relative Gütekriterien haben Sie in der Theoriesitzung GFI, TLI und CFI kennengelernt. Allen drei ist gemeinsam, dass sie als Vergleichsmodell nicht ein saturiertes bzw. unrestringiertes Modell nutzen, sondern das genaue Gegenteil: das Unabhängigkeitsmodell, in dem alle Korrelationen der beobachteten Variablen auf 0 gesetzt werden. Statt also unser postuliertes Modell mit optimaler Passung zu vergleichen und uns nur unsere Fehler vorzuhalten, betrachten diese Kriterien das schlecht möglichst Modell und geben eine Aussage darüber, wie viel besser unser Modell ist. Auch diese drei Fitkriterien können wir uns natürlich von lavaan ausgeben lassen:
modelfit[c('cfi', 'tli', 'gfi')]
## cfi tli gfi
## 0.9961648 0.9928089 0.9992903
Nehmen Sie sich einen Moment Zeit, um anhand der gesammelten Informationen zu überlegen, ob Sie dieses Modell beibehalten würden oder nicht.
Individuelle Modellbeurteilung
Die oben genannten Fitkriterien werden häufig anhand von Daumenregeln beurteilt. Wie bei allen Daumenregeln gilt auch bei diesen, dass sie nicht uneingeschränkt auf alle Situationen anwendbar sind und es meistens zu genaueren Aussagen führt, sich eine spezifische Situation anzugucken. In anderen Worten: wie für die Effektstärkemaße wie Cohens $d$ und $R^2$ gilt auch beim Modelfit, dass Sie die Grenzen aus den Daumenregeln nur dann nutzen sollten, wenn Sie hinsichtlich Ihres Forschungsgegenstandes komplett ahnungslos sind.
Eine Möglichkeit ist es, für eine spezifische Situation einfach spezifische Cut-Off Werte für die Fitstatistiken zu generieren. Die gängigen Cut-Off Werte wurden in Simulationsstudien ermittelt, die bestimmte Konstellationen bezüglich Modelltypen und -komplexität sowie Stichprobengröße machen. Wenn wir genau so eine Simulationsstudie für unsere spezifische Situation durchführen, erhalten wir auch für unsere Situation angepasst Cut-Off Kriterien. Damit wir die Simulation nicht selbst schreiben müssen, können wir einfach die ezCutoffs Funktion aus dem gleichnamigen Paket nutzen:
library(ezCutoffs)
cutoff <- ezCutoffs(mod_two, conspiracy)
## Data Generation
##
## |==================================================| 100% elapsed = 13s ~ 0s
##
## Model Fitting
##
## |==================================================| 100% elapsed = 15s ~ 0s
Die Funktion nimmt ein paar Argumente entgegen:
model: das Modell, für das wir Cut-Offs generieren möchtendata: Falls wir schon Daten haben, können wir sie hier angeben, um einen einfachen Vergleich zwischen empirischen Werten und Cut-Off in einer Tabelle zu habenn_obs: Falls wir noch keine Daten haben, können wir hier angeben, wie groß unsere Stichproben sein soll
Das Durchführen dauert ein paar Sekunden, weil per Voreinstellung nun 1000 neue Datensätze erzeugt werden, auf die unser Modell dann auch 1000 mal angewandt werden muss. Darüber hinaus sei gesagt, dass, weil es sich hier um einen Zufallsprozess handelt, die Ergebnisse, die Sie erzeugen, wenn Sie die Analyse auf Ihrem Rechner durchführen, nicht 100%ig deckungsgleich mit denen sein werden, die sie hier sehen.
Um uns die neu entstandenen Cut-Off Werte anzusehen, können wir einfach das Objekt aufrufen:
cutoff
## Empirical fit Cutoff (alpha = 0.05)
## chisq 33.24343262 16.089762505
## cfi 0.99621179 0.998770472
## tli 0.99289710 0.997694635
## rmsea 0.03584388 0.020291241
## srmr 0.01547626 0.009364649
Wir sehen hier, dass die Cut-Off Werte, die für unsere Situation erzeugt wurden (dargestellt in der Cutoff (alpha = 0.05) Spalte), sehr viel restriktiver sind als die generellen Leitlinien. Für den RMSEA ergibt sich ein Cut-Off von ca. 0.02, statt der üblichen 0.05, für den SRMR sogar 0.01. Anhand dieser spezifischen Cut-Off Werte muss unser Modell abgelehnt werden.
Lokalisierung von Misfit
Die letzten beiden Abschnitte haben uns nur gezeigt, dass unser Modell nicht passt, aber noch keine konkrete Aussage über das Warum zugelassen. Wenn wir ganz an den Anfang des Abschnitts zurück denken, dann hatten wir dort die beiden Kovarianzmatrizen gesehen, in denen sich die einzelnen Elemente mitunter ein wenig unterscheiden. lavaan kann uns die Differenz der beiden Matrizen natürlich auch direkt geben, indem wir die residuals der Kovarianzmatrix ($cov) inspizieren:
inspect(fit_two, 'residuals')$cov
## Q2 Q7 Q12 Q5 Q10 Q15
## Q2 0.000
## Q7 -0.008 0.000
## Q12 -0.006 0.009 0.000
## Q5 0.076 0.010 0.050 0.000
## Q10 0.002 -0.016 -0.036 -0.038 0.000
## Q15 0.013 -0.034 -0.041 -0.016 0.055 0.000
Leider haben Varianzen und Kovarianzen die ungünstige Eigenschaft, dass Sie keine leicht interpretierbare Skala haben. Wie immer hilft dann die Standardisierung. Diese können wir mit dem residuals-Befehl anfordern:
residuals(fit_two, 'standardized')$cov
## Q2 Q7 Q12 Q5 Q10 Q15
## Q2 0.000
## Q7 -1.211 0.000
## Q12 -1.372 2.688 0.000
## Q5 3.664 0.554 3.259 0.000
## Q10 0.113 -0.780 -2.119 -2.961 0.000
## Q15 0.768 -2.193 -3.256 -1.706 4.365 0.000
Die einzelnen Einträge können wir jetzt quasi als $z$-Werte interpretieren: wenn ein Wert vom Betrag also größer als 1.96 ist, ist der Unterschied zwischen Modellimplikation und Empirie an dieser Stelle auf einem $\alpha$-Fehlerniveau von 5% statistisch bedeutsam. Wir sehen z.B., dass in unserem Modell der Zusammenhang zwischen Q10 und Q15 sehr stark unterschätzt wird (das Residuum ist hier 4.37). Eine detaillierte Untersuchung des lokalen Misfits anhand der Residuen in der Kovarianzmatrix finden Sie im im Appendix.
Die standardisierten Residuen der Kovarianzmatrizen erlauben uns, direkt und detailliert die Diskrepanz zwischen unserem Modell und den empirischen Daten zu beleuchten. Ein Problem besteht aber darin, dass wir uns dabei die rohe Information in der Kovarianzmatrix angucken, statt in der Sprache des Modells zu sehen, welche Parameter Probleme verursachen. Diesen Weg können wir gehen, wenn wir mit Modifikationsindizes arbeiten.
Um Modifikationsindizes in lavaan zu ermitteln, können wir mit inspect(fit_two, 'modindices') arbeiten. Wie schon bei den Residuen im letzten Abschnitt sind wir dabei aber in den Optionen etwas eingeschränkt, sodass es mehr Sinn macht, den eigens dafür geschaffenen modindices-Befehl zu nutzen. Dieser nimmt ein paar Argumente entgegen, die das Lesen der Ergebnisse erheblich vereinfachen können:
object: Das Ergebnisobjekt unserercfasort.: Ob die Ergebnisse nach Größe des Modifikationsindex sortiert sein sollenminimum.value: Grenze die Modifikationsindizes überschreiten müssen, um angezeigt zu werdenfilter: Parameter, auf die der Output beschränkt werden soll (z.B.'=~'für Faktorladungen)
Um ein bisschen besser zu verstehen, was diese Argumente bewirken, gucken wir uns am besten das Ergebnis mal an:
modindices(fit_two, sort. = TRUE, minimum.value = 5)
## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 44 Q10 ~~ Q15 21.165 0.124 0.124 0.138 0.138
## 24 GC =~ Q5 21.165 0.282 0.339 0.231 0.231
## 26 GC =~ Q15 8.210 -0.121 -0.145 -0.131 -0.131
## 42 Q5 ~~ Q10 8.210 -0.109 -0.109 -0.097 -0.097
## 27 CI =~ Q2 7.568 0.122 0.126 0.085 0.085
## 35 Q7 ~~ Q12 7.568 0.107 0.107 0.193 0.193
Die Ergebnistabelle beginnt wieder mit den gleichen drei Spalten, wie die Tabelle der Parameter, die wir uns mit paramaterEstimates haben ausgeben lassen. Danach kommt mit mi die Spalte für die Modifikationsindizes. Dieser Index stellt eine Schätzung über die Veränderung des $\chi^2$-Wertes des Modells dar, wenn wir die Restriktion dieser Zeile lockern würden. Zur Erinnerung: der $\chi^2$-Wert des Modells ist 33.02. Diesen Wert könnten wir um 21.16 “Punkte” verringern, wenn wir unsere Annahmen über die Residualkovarianz zwischen Q10 und Q15 lockern würden. Im Modell wird die Annahme gemacht, dass die Q10 und Q15 deswegen korreliert sind, weil sie (zusammen mit Q5) einen gemeinsamen Faktor als Ursache haben. Die restliche Varianz in Q10 und Q15 wird als Messfehler definiert, welche im Verständnis der KTT per Definition unkorreliert sind. Der Modifikationsindex zeigt uns hier, dass die Annahme, dass es sich hier um unkorrelierte, pure Messfehler handelt, in der Empirie eventuell nicht haltbar ist.
Die folgenden Spalten beziehen sich allesamt auf den expected parameter change (EPC). Die erste Variante ist unstandardisiert (also in der ersten Zeile eine Kovarianz). Der sepc.lv ist der Wert, wenn wir statt der 1. Faktorladungen die latenten Varianzen auf 1 fixieren würden (das verändert für Residualvarianzen überhaupt nichts). Der sepc.all ist der Wert, wenn alle Variablen im Modell standardisiert sind und entspricht in diesem Fall der Korrelation. Zu guter Letzt ist der sepc.nox der Wert, wenn alle Variablen außer die exogenen manifesten Variablen standardisiert werden (in unserem Fall gibt es keine solche Variablen, also ist der Wert mit sepc.all identisch).
Zusammengefasst heißt das Ergebnis für die 1. Zeile also: wenn wir die Residualkovarianz zwischen Q10 und Q15 zulassen, erwarten wir eine Verbesserung des $\chi^2$-Wertes um 21.16 Einheiten und die resultierende Residualkorrelation sollte einen Wert von 0.14 annehmen.
Alternativ zur Residualkorrelation zwischen Q10 und Q15 können wir auch die Querladung von Q5 zulassen. Beide Modifikationsindizes sind praktisch identisch. Das liegt daran, dass in beiden Fällen das Gleiche erreicht wird. Der Fehlpassung liegt das Problem zugrunde, dass Q10 und Q15 empirisch stärker korreliert sind, als das Modell zulässt, wie auch die 4.37 zeigt, die wir als standardisiertes Residuum dieser Kovarianz gesehen hatten. Wenn wir die Residualkovarianz zwischen Q10 und Q15 zulassen, wird diesem Punkt direkt Rechnung getragen. Wenn wir die Querladung zulassen, erfolgt das Gleiche indirekt: die Querladung bewirkt, dass der GC Faktor aus Q5 auspartialisiert und der Rest vom CI Faktor beeinflusst wird. Dieser Rest ist höher mit Q10 und Q15 korreliert, sodass deren Korrelation untereinander durch die unkorrlierten Anteile in Q5 nicht mehr nach unten gedrückt werden muss, um einen gemeinsamen Faktor zu erzeugen.
Modellvergleiche
Wenn wir die Querladung im Modell zulassen, ergibt sich ein anderes Modell als das von uns ursprünglich Postulierte. In Form des Pfaddiagramms sieht das dann so aus:
Wir können dieses Modell wieder in zwei Zeilen definieren:
# Modell
mod_three <- '
GC =~ Q2 + Q7 + Q12 + Q5
CI =~ Q5 + Q10 + Q15'
# Schätzung
fit_three <- cfa(mod_three, conspiracy,
meanstructure = TRUE)
Die Ergebnisse haben sich in einigen Punkten verändert:
summary(fit_three)
## lavaan 0.6.16 ended normally after 37 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 20
##
## Number of observations 2495
##
## Model Test User Model:
##
## Test statistic 12.481
## Degrees of freedom 7
## P-value (Chi-square) 0.086
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## GC =~
## Q2 1.000
## Q7 1.055 0.023 46.130 0.000
## Q12 1.118 0.023 48.684 0.000
## Q5 0.225 0.043 5.257 0.000
## CI =~
## Q5 1.000
## Q10 1.177 0.096 12.318 0.000
## Q15 0.970 0.079 12.248 0.000
##
## Covariances:
## Estimate Std.Err z-value P(>|z|)
## GC ~~
## CI 0.646 0.059 10.961 0.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .Q2 2.964 0.030 99.057 0.000
## .Q7 2.667 0.030 88.241 0.000
## .Q12 2.645 0.030 87.812 0.000
## .Q5 3.254 0.029 110.456 0.000
## .Q10 3.502 0.028 125.994 0.000
## .Q15 4.228 0.022 191.223 0.000
## GC 0.000
## CI 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q2 0.788 0.029 27.334 0.000
## .Q7 0.672 0.027 24.550 0.000
## .Q12 0.457 0.025 18.212 0.000
## .Q5 1.198 0.046 26.130 0.000
## .Q10 1.091 0.044 24.997 0.000
## .Q15 0.651 0.028 23.340 0.000
## GC 1.445 0.062 23.337 0.000
## CI 0.604 0.087 6.970 0.000
Auffällig ist natürlich vor allem, dass die Faktorladungen sich verändert haben - besonders dass Q5 jetzt auch auf den Faktor GC lädt.
Wenn wir uns mit inspect(fit_three, 'fitmeasures') oder fitmeasures(fit_three) die Fitstatistiken dieses Modells ausgeben lassen, erhalten wir im direkten Vergleich mit dem Modell ohne Querladung folgendes Bild:
| LogLikelihood | $\chi^2$ | $df$ | $p$ | RMSEA | SRMR | CFI | TLI | |
|---|---|---|---|---|---|---|---|---|
| Mit Querladung | -23057.9 | 12.481 | 7 | 0.086 | 0.018 | 0.007 | 0.999 | 0.998 |
| Ohne Querladung | -23068.2 | 33.018 | 8 | 0.000 | 0.035 | 0.014 | 0.996 | 0.993 |
Wie wir sehen, schneidet das Modell mit Querladung bei jeder Fitstatistik besser ab. Darüber hinaus muss das Modell auch anhand des $\chi^2$-Tests nicht mehr verworfen werden. Aber ist dieser Unterschied im Vergleich zum Modell ohne Querladung statistisch bedeutsam? Oder statistisch korrekt formuliert: müssen wir die Annahme, dass die Querladung exakt 0 ist (es also keine Querladung gibt) verwerfen? Für den direkten Vergleich zweier geschachtelter Modelle haben Sie im Theorieabschnitt schon den Likelihood-Ratio Test kennengelernt.
Wie der Name verrät, werden bei diesem Test die Likelihoods der beiden Modelle verglichen. Genau genommen passiert bei diesem Test exakt das, was wir schon beim einfachen $\chi^2$-Test gesehen haben: ein Modell wird mit einem anderen, weniger restriktiven Modell verglichen, indem die Differenz der beiden LogLikelihoods bestimmt wird. Diese Differenz folgt auch hier der $\chi^2$-Verteilung, jetzt allerdings mit der Differenz der Freiheitsgrade der beiden Modelle als $df$.
In diesem Fall ist das Modell mit Querladung das weniger strenge oder unrestringierte Modell ($M_U$). Das Modell ohne Querladung ist ein Sonderfall dieses Modells, weil es die Querladung auf den Wert 0 restringiert und wird daher als $M_R$ bezeichnet. Ob diese Restriktion beibehalten werden kann, können wir mit dem Likelihood-Ratio oder auch Modelldifferenztest prüfen. In lavaan brauchen wir dafür lediglich beide Ergebnisobjekte und den lavTestLRT-Befehl:
lavTestLRT(fit_two, fit_three)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff
## fit_three 7 46156 46272 12.481
## fit_two 8 46174 46285 33.018 20.537 0.088489 1
## Pr(>Chisq)
## fit_three
## fit_two 5.85e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Die Tabelle beginnt zunächst mit den Freiheitsgraden df der beiden Modelle. Darauf folgen zwei Informationskriterien, Akaike’s Information Criterion (AIC) und das Bayesian Information Criterion (BIC). Für beide ist zunächst folgende Daumenregel ausreichend: kleinere Werte sind bessere Werte. Dann kommt noch einmal der $\chi^2$-Wert der einzelnen Modelle (Chisq). Die restlichen drei Spalten befassen sich direkt mit dem Ergebnis des Differenztests: Chisq Diff ist der Unterschied der $\chi^2$-Werte (bzw. $-2$-mal die Differenz der LogLikelihoods), Df diff ist der Unterschied der Freiheitsgrade und Pr(>Chisq) ist der $p$-Wert.
In diesem Fall hat der Modellvergleich einen Freiheitsgrad, weil fit_two genau eine Restriktion gegenüber fit_three vornimmt: die Querladung von Q5 wird auf 0 fixiert. Diese eine Restriktion macht fit_two um einen Freiheitsgrad sparsamer, weil es einen Parameter weniger gibt, der frei geschätzt werden muss.
Der letzten Spalte können wir entnehmen, dass der Modellvergleich signifikant ausfällt. Das bedeutet, dass die Restriktionen in $M_R$ verworfen werden müssen und wir stattdessen $M_U$ nutzen sollten. Wäre der Vergleich nicht bedeutsam ausgefallen, könnten wir - aufgrund des Sparsamkeitsprinzips - $M_R$ beibehalten.
Mit den Modellvergleichen können Sie nun neben dem direkten Test eines Modells, dass aus einer Theorie abgeleitet wird nun auch Modelle vergleichen, die aus konkurrierenden Theorien abgeleitet werden können. Dazu sei allerdings angemerkt, dass in einigen Publikationen der Likelihood-Ratio Test genutzt wird, um zu prüfen, ob z.B. ein Einfaktor-Modell oder ein Zwei-Faktormodell einen Satz von Items besser abbildet. Diese Modellvergleiche sind mit dem LRT als problematisch einzustufen, weil die Likelihood-Differenz bei Restriktionen an den Grenzen des zulässigen Parameterraums (Varianzen gleich 0 setzen, Korrelationen auf 1 setzen, usw.) nicht der postulierten $\chi^2$-Verteilung folgt.
Außerdem müssen wir an dieser Stelle anmerken, dass wir unser Modell mit Hilfe der Modifikationsindizes datengetrieben verändert haben. Somit verliert diese Analyse an konfirmatorischen Charakter - wir sind hier explorativ vorgegangen. Um die Kreuzladung als mögliche Modellerweiterung zu untersuchen, müssten wir dies erneut an einem unabhängigen (z.B. neu erhobenen) Datensatz untersuchen. Dies wird auch Kreuzvalidierung genannt, da wir die neue Theorie an einem neuen Datensatz einer neuen Validierung unterziehen.
Appendix A
Lokalisierung von Misfit in Kovarianzmatrizen
Im Abschnitt zur Lokalisierung von Misfit haben wir die Residuen in Kovarianzmatrizen schon angeschnitten. Hier noch einmal die standardisierten Residuen:
residuals(fit_two, 'standardized')$cov
## Q2 Q7 Q12 Q5 Q10 Q15
## Q2 0.000
## Q7 -1.211 0.000
## Q12 -1.372 2.688 0.000
## Q5 3.664 0.554 3.259 0.000
## Q10 0.113 -0.780 -2.119 -2.961 0.000
## Q15 0.768 -2.193 -3.256 -1.706 4.365 0.000
Um besser interpretieren zu können, was uns die Abweichungen sagen, hilft es, die Matrix in vier grobe Teile aufzuteilen:
- Die Varianzen der Items in der Diagonale
- Die Kovarianzen zwischen den Items, die malevolent global conspiracies angehören
- Die Kovarianzen zwischen den Items, die control of information angehören
- Die Kovarianzen zwischen den Items, die unterscheidlichen Faktoren angehören
Dazu legen wir die Matrix am besten in einem Objekt ab und gucken uns die Teile einzeln an:
# Als Objekt anlegen
resi <- residuals(fit_two, 'standardized')$cov
# Varianzen in der Diagonale
diag(resi)
## Q2 Q7 Q12 Q5
## -1.168548e-08 -1.203046e-07 -1.037327e-07 -1.283563e-08
## Q10 Q15
## 6.144777e-08 1.097784e-07
Die Varianzen können durch das Modell also beinahe perfekt repliziert werden. Ein wenig anders sieht es z.B. bei den Kovarianzen zwischen den Items zu malevolent global conspiracies aus:
resi[1:3, 1:3]
## Q2 Q7 Q12
## Q2 -1.168548e-08 -1.211380e+00 -1.371748e+00
## Q7 -1.211380e+00 -1.203046e-07 2.688481e+00
## Q12 -1.371748e+00 2.688481e+00 -1.037327e-07
Hier ist die empirische Kovarianz deutlich größer als die modellimplizierte. Was bedeutet das? Unser Modell behauptet, dass die Kovarianz zwischen Q7 und Q12 einfach die durch die Faktorladungen gewichtete Varianz der latenten Variable ist: $cov(Q7, Q12) = \lambda_7 \cdot \lambda_{12} \cdot var(GC)$. Das gilt für alle Kovarianzen zwischen den Items Q2, Q7 und Q12. Wenn diese Erwartung nicht der empirischen Beobachtung entspricht, lässt sich das in etwa so interpretieren, dass die Items Q7 und Q12 mehr untereinander gemeinsam haben, als sie mit dem Item Q2 gemeinsam haben. Wenn wir uns die Formulierungen der Aussagen noch einmal vor Augen führen, können wir versuchen, einen inhaltlichen Grund für dieses Problem zu finden.
Auch für die Items der latenten Variable control of information können wir das Ganze genauer inspizieren:
resi[4:6, 4:6]
## Q5 Q10 Q15
## Q5 -1.283563e-08 -2.961201e+00 -1.706323e+00
## Q10 -2.961201e+00 6.144777e-08 4.365493e+00
## Q15 -1.706323e+00 4.365493e+00 1.097784e-07
An welchen Stellen springt Ihnen hier Misfit ins Auge? Wenn Sie die Itemformulierungen betrachten - woran könnte das inhaltlich liegen?
Für ein zweifaktorielles Modell wahrscheinlich relevanter ist der letzte Teil: die Kovarianzen zwischen Items, die nicht zum gleichen Faktor gehören. In der CFA, wie wir sie hier aufgebaut haben, haben wir impliziert, dass Item Q2 und Item Q5 nur deswegen zusammenhängen, weil es einen Zusammenhang zwischen den grundlegenden Überzeugungen malevolent global conspiracies und control of information gibt. Item Q5 fällt allerdings direkt zwei mal negativ auf:
resi[4:6, 1:3]
## Q2 Q7 Q12
## Q5 3.6644113 0.5540613 3.259169
## Q10 0.1131168 -0.7800295 -2.118839
## Q15 0.7682879 -2.1926923 -3.255747
Sowohl mit Q2 als auch mit Q12 scheint es höher zu korrelieren, als durch unser Modell abgebildet werden kann. Ein möglicher Grund könnte hier sein, dass Q5 in seiner Formulierung impliziert, dass die Täuschung im Auftrag der kleinen, geheimen Gruppen durchgeführt wird, welche der zentrale Bestandteil des Faktor malevolent global conspiracies sind. Q10 und Q15 hingegen verdeutlichen, dass solche Täuschung aus Selbstinteresse geschieht. Es könnte also sein, dass Q5 nicht eindeutig genug auf control of information zurückzuführen ist, sondern auch Elemente der malevolent global conspiracies enthält und eigentlich eine Querladung auf diesen Faktor zugelassen werden müsste.
Appendix B
Hierarchie der Messmodelle
In vielen Bereichen der Psychologie ist es wichtig, nicht nur festzuhalten, dass mehrere beobachtbare Variablen ein gemeinsames latentes Konstrukt erheben, sondern auch sicherzustellen, dass sie dies in gleicher Weise tun. Nehmen wir an, sie kämen in die Situation, für einen, nicht näher benannten, Statistik-lastigen Kurs im Master der Psychologie drei parallele Formen einer Modulprüfung entwickeln zu müssen. In dem Fall würden Sie im Interesse der Kursteilnehmer und -teilnehmerinnen versuchen, sicherzustellen, dass die drei Formen die statistischen Kompetenzen (das latente Konstrukt) auch in gleicher Weise erheben und sich nicht z.B. in der mittleren Schwierigkeit unterscheiden.
Verschiedene Formen der “Gleichheit” dieser drei Messungen werden in der Hierarchie der Messmodelle festgehalten:
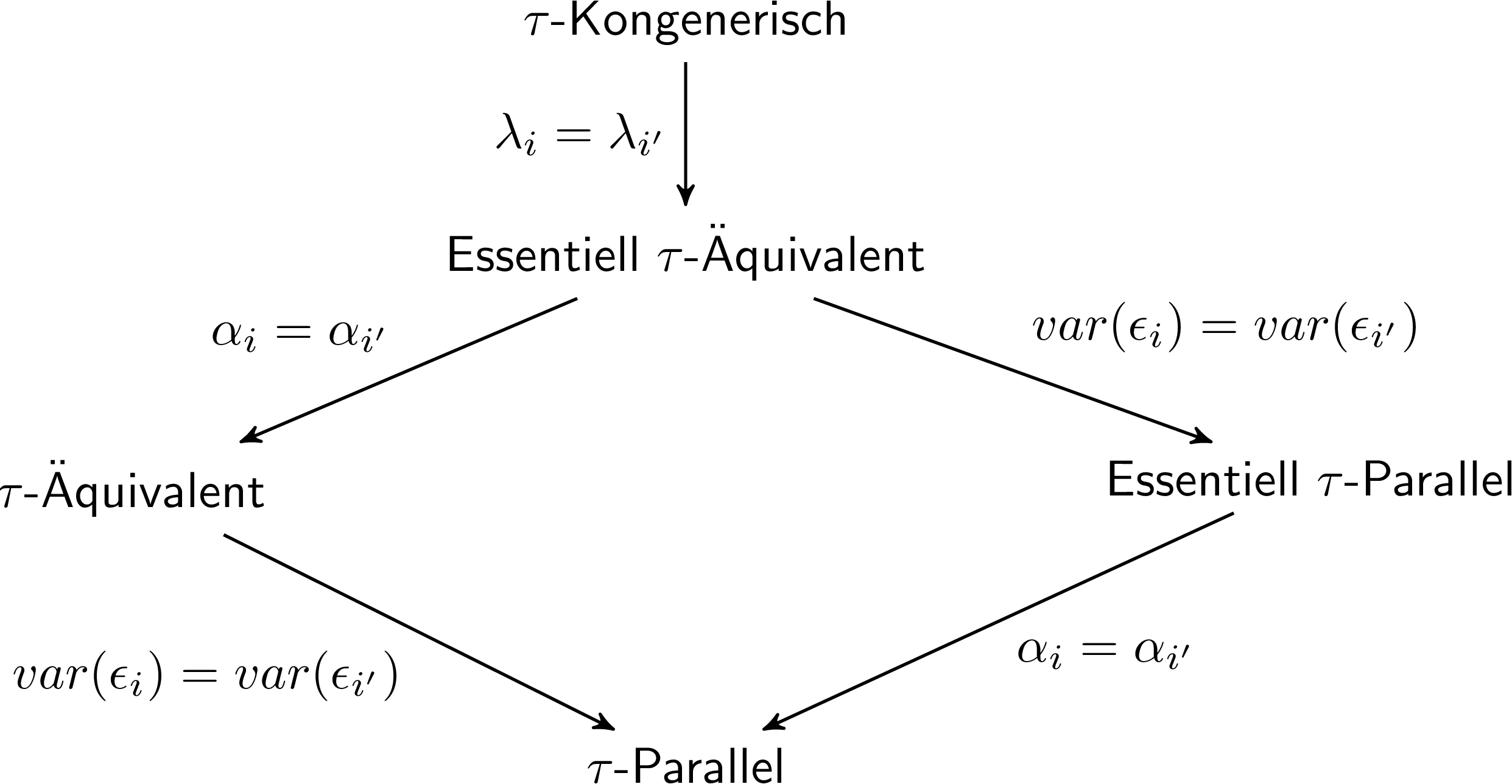
In der Abbildung sind die fünf typischen Messmodelle der klassischen Testtheorie zu sehen. In der Bezeichnung bezieht sich der Buchstabe $\tau$ auf den zugrundeliegenden, wahren Wert einer manifesten Variable. Anders als die latenten Variablen, die wir bisher betrachtet haben, ist so ein $\tau$ für jede manifeste Variable einzeln definiert, kann aber ohne weitere Modellannahmen nicht empirisch geschätzt werden. Die Namen der Messmodelle beziehen sich darauf, wie die wahren Werte $\tau$ verschiedener manifester Variablen im Verhältnis zueinander stehen. $\tau$-parallel heißt also z.B., dass die wahren Werte zweier Parallelformen der Statstikprüfung wirklich parallel sind - also in jedweder Hinsicht gleiche Eigenschaften haben. Der Weg, um von einem Messmodell zum nächsten zu kommen, ist stets an den Verbindungen dargestellt.
Im Folgenden arbeiten wir mit ein paar fiktiven Daten zu dieser imaginären Prüfung.
#load(url("https://pandar.netlify.app/daten/stat_test.rda"))
load(url("https://courageous-donut-84b9e9.netlify.app/post/stat_test.rda"))
Der Datensatz enthält lediglich drei Variablen:
summary(stat_test)
## test1 test2 test3
## Min. :-1.1672 Min. :-1.5487 Min. :-1.2554
## 1st Qu.: 0.3794 1st Qu.: 0.2927 1st Qu.: 0.3684
## Median : 0.8089 Median : 0.8373 Median : 0.9853
## Mean : 0.7867 Mean : 0.8193 Mean : 0.9033
## 3rd Qu.: 1.2571 3rd Qu.: 1.2846 3rd Qu.: 1.4364
## Max. : 2.7485 Max. : 2.6747 Max. : 2.5199
Die Werte stellen auf einer Skala von ca. -3 bis 3 die geschätzte Fähigkeit in drei verschiedenen Versionen des Tests dar.
$\tau$-kongenerisches Modell
Das am weitesten verbreitete Messmodell in der Psychologie ist das $\tau$-kongenerische Messmodell. Dieses haben wir z.B. auch in den anderen Abschnitten dieser Sitzung gesehen. Für unsere fiktive Statstikprüfung können wir es wie folgt anlegen:
# Modell
mod1 <- 'stat =~ test1 + test2 + test3'
# Schätzung
fit1 <- cfa(mod1, stat_test,
meanstructure = TRUE)
Der Abschnitt zu den Parametern sieht in der Zusammenfassung dann so aus:
summary(fit1)
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## stat =~
## test1 1.000
## test2 1.087 0.126 8.615 0.000
## test3 1.265 0.132 9.616 0.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.787 0.064 12.306 0.000
## .test2 0.819 0.077 10.707 0.000
## .test3 0.903 0.071 12.724 0.000
## stat 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.169 0.033 5.171 0.000
## .test2 0.323 0.051 6.373 0.000
## .test3 0.090 0.041 2.224 0.026
## stat 0.321 0.064 5.004 0.000
## [...]
Oder etwas bildlicher ausgedrückt:
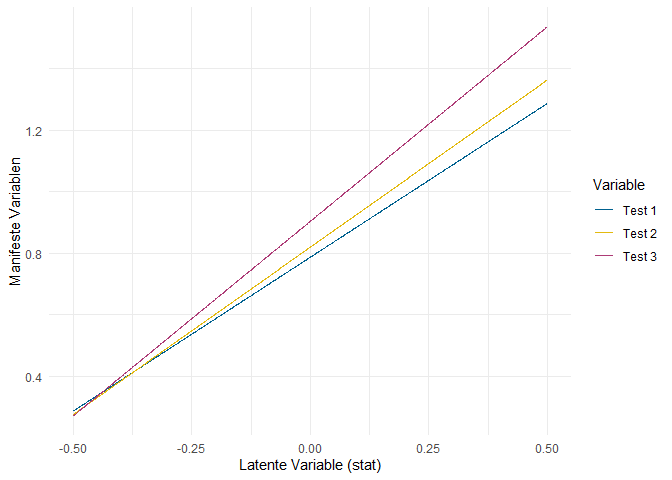
Die Regression der drei Tests auf die latente Variable unterscheidet sich also in der Steigung (Faktorladung) und dem Intercept. Das bedeutet, dass unsere drei Tests unterschiedlich gut darin sind, zwischen Personen zu unterscheiden: wenn Urs eine bessere Fähigkeit auf der latenten Dimension aufweist als Hans, wird er im 3. Test um mehr Punkte besser abschneiden, als im 1. Test. Darüber hinaus sind beide Tests unterschiedlich schwierig: eine durchschnittliche Person wird auf dem 3. Test mehr Punkte erhalten als auf dem 1. Beide Zustände wären äußerst ungünstig, weil Personen (anders als unsere Normierungsstichprobe, die wir hier betrachten) normalerweise nur einen der drei Tests ablegen und Personen, die den 3. Test ablegen, dann im Mittel einen Vorteil hätten.
Mit den Restriktionen der Messmodelle können wir jetzt über Modellvergleiche prüfen, ob diese Unterschiede statistisch bedeutsam oder nur zufällige Schwankungen aufgrund der Stichprobenziehung sind.
Esentiell $\tau$-äquivalentes Modell
Der erste Schritt, der bei der Restriktion von Messmodellen stets vorgenommen werden muss, ist die Gleichsetzung der Diskriminationsparameter. Nur so kann garantiert werden, dass andere Gleichsetzungen sinnvoll interpretierbar und von der Skala, mit der wir die Ergebnisse beschreiben, unabhängig sind.
Weil wir zur Skalierung unserer latenten Variable die erste Faktorladung auf 1 setzen und das essentiell $\tau$-äquivalente Messmodell postuliert, dass alle Faktorladungen gleich sein sollen, können wir alle Faktorladungen auf 1 fixieren. Dafür können wir händisch den jeweiligen Parameter festlegen:
# Modell
mod2 <- 'stat =~ 1*test1 + 1*test2 + 1*test3'
# Schätzung
fit2 <- cfa(mod2, stat_test,
meanstructure = TRUE)
Der Abschnitt zu den Parametern sieht in der Zusammenfassung dann so aus:
summary(fit2)
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## stat =~
## test1 1.000
## test2 1.000
## test3 1.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.787 0.067 11.756 0.000
## .test2 0.819 0.077 10.605 0.000
## .test3 0.903 0.068 13.368 0.000
## stat 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.137 0.030 4.618 0.000
## .test2 0.316 0.049 6.447 0.000
## .test3 0.147 0.031 4.823 0.000
## stat 0.400 0.059 6.733 0.000
## [...]
Alle Faktorladungen sind nun identisch. Das heißt, dass die Linien der unterschiedlichen Tests im Bild parallel verlaufen sollten, weil wir jetzt den Einfluss der latenten Variable auf die manifesten Variablen gleichgesetzt haben:
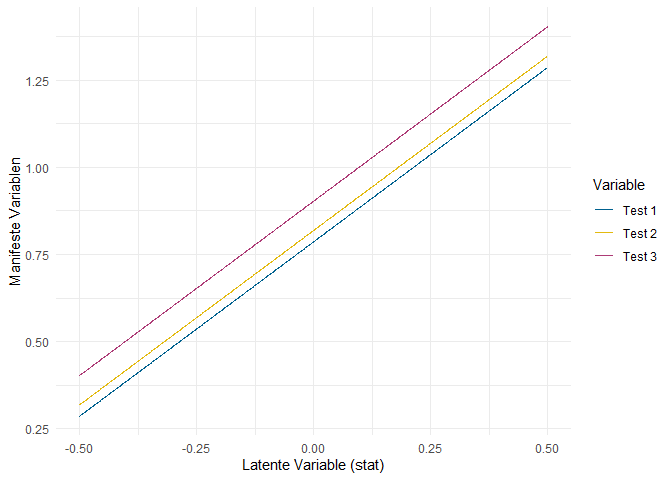
Das bedeutet, dass sich der Unterschied zwischen Urs und Hans in der statistischen Fähigkeit in allen drei Tests im gleichen Punkteunterschied äußern sollte. Das sollte ist dabei wichtig, weil es natürlich in jedem Einzelfall aufgrund von Messfehlern zu Unterschieden kommen kann, wenn wir den Test aber unendlich häufig durchführen würden, wäre der Unterschied zwischen beiden immer gleich, egal welchen der drei Tests wir nutzen.
Ist diese Annahme haltbar? Wir können sie mit dem Modellvergleich explizit prüfen:
lavTestLRT(fit1, fit2)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
## fit1 0 675.66 700.75 0.000
## fit2 2 677.05 696.56 5.383 5.383 0.11872 2 0.06778 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Der Test hat 2 Freiheitsgrade, weil wir nun nicht mehr die beiden Ladungen für test2 und test3 schätzen müssen, sondern diese einen vorgegebenen Wert angenommen haben. Bei einem $\alpha$-Fehlerniveau von 5% muss diese Annahme also nicht verworfen werden und wir können das sparsamere, essentiell $\tau$-äquivalente Messmodell für diese drei Tests beibehalten.
Die Annahme der essentielle $\tau$-Äquivalenz spielt eine wichtige Rolle, wenn Skalen aus Itemsummen oder -mittelwerten bestimmt werden — sie muss mindestens gelten, damit einfaches Aufsummieren oder Mitteln zulässig ist. Genauso ist sie Voraussetzung für das bekannte Reliabilitätsmaß Cronbach’s $\alpha$ (neben bspw. Eindimensionaltität der Skala). Gilt diese Annahme auf essentielle $\tau$-Äquivalenz nicht, so führen Analysen, die einfache Skalensummen oder -mittelwerte verwenden zu verzerrten Schlüssen und die Reliabilitätsschätzung unterliegt ebenfalls Verzerrungen. Alternativen bilden hier die latente Modellierung und als Skalenreliabilität könnte bspw. McDonald’s $\omega$ verwendet werden.
$\tau$-äquivalentes Modell
In der Hierarchie der Messmodelle haben wir zwei Möglichkeiten, vorzugehen: wir können im Anschluss an das essentiell $\tau$-äquivalente Messmodell entweder die Intercepts restringieren und so beim $\tau$-äquivalenten Messmodell ankommen, oder uns die Residualvarianzen vornehmen und so beim essentiell $\tau$-parallelen Messmodell angelangen. Wir entscheiden uns hier für den häufiger genutzten linken Weg der Abbildung und beziehen uns zunächst auf die Mittelwertsstruktur:
# Modell
mod3 <- 'stat =~ 1*test1 + 1*test2 + 1*test3
test1 ~ (alp)*1
test2 ~ (alp)*1
test3 ~ (alp)*1'
# Schätzung
fit3 <- cfa(mod3, stat_test,
meanstructure = TRUE)
Mit (...) wird in lavaan einem Parameter ein Label gegeben. Diese Labels können beliebig benannt sein, sie müssen nur mit einem Buchstaben beginnen. In der Zeile test1 ~ (alp)*1 wird also das Intercept von test1 angefordert und diesem Intercept der Name alp gegeben. In der nächsten Zeile machen wir für test2 das Gleiche. Dadurch, dass wir hier den gleichen Namen nutzen werden die beiden Parameter zur Gleichheit gezwungen. In der Zusammenfassung tauchen diese Labels auch wieder auf, um zu verdeutlichen welche Parameter absichtlich gleich sind:
summary(fit3)
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## stat =~
## test1 1.000
## test2 1.000
## test3 1.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .test1 (alp) 0.838 0.062 13.564 0.000
## .test2 (alp) 0.838 0.062 13.564 0.000
## .test3 (alp) 0.838 0.062 13.564 0.000
## stat 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.141 0.030 4.642 0.000
## .test2 0.314 0.049 6.401 0.000
## .test3 0.156 0.032 4.914 0.000
## stat 0.398 0.059 6.694 0.000
## [...]
Diese Restriktion können wir erneut mit dem LRT prüfen:
lavTestLRT(fit2, fit3)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
## fit2 2 677.05 696.56 5.383
## fit3 4 678.83 692.77 11.166 5.7829 0.12555 2 0.05549 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Erneut erhalten wir 2 Freiheitsgrade beim Modellvergleich: jetzt müssen wir statt drei Intercepts nur noch Eines schätzen (den Wert von alp). Und wieder ist bei einem $\alpha$-Fehlerniveau von 5% der Modellvergleich nicht statistisch bedeutsam, sodass wir auch hier wieder das sparsamere Modell beibehalten können.
Inhaltlich heißt dieses Ergebnis, dass wir für zwei Personen, die die gleiche statistische Fähigkeit haben auch den gleichen Wert in einem Test - egal welchem der drei - erwarten. Auch hier können Messfehler natürlich dazu führen, dass im Einzelfall Unterschiede entstehen. Über unendlich viele Wiederholungen hinweg sind die Erwartungswerte dieser Personen aber gleich. Wichtig ist, dass das nicht nur innerhalb eines Tests gilt, sondern auch über Tests hinweg. Wir können unterschiedlichen Personen also unterschiedliche Tests vorlegen - wenn Sie die gleiche Fähigkeit haben, dann erwarten wir für beide das gleiche Ergebnis. Die Ergebnisse der drei verschiedenen Formen der Modulprüfung sind also vergleichbar. Wenn die Annahme des $\tau$-äquivalenten Messmodells allerdings nicht hält, sind die Prüfungen nicht direkt vergleichbar.
Auch in der Abbildung zeigt sich jetzt, dass die Tests äquivalent sind:
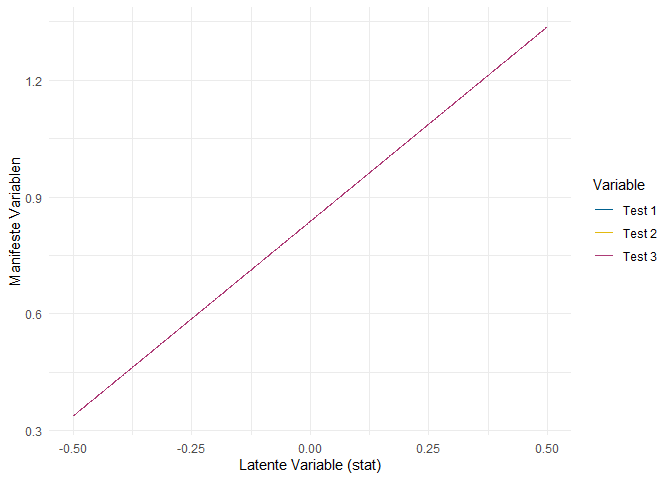
Essentiell $\tau$-paralleles Modell
Im Essentiell $\tau$-parallelen Modell werden die Restriktionen bezüglich der Intercepts zunächst außer Acht gelassen. Stattdessen wird das essentiell $\tau$-äquivalente Modell bezüglich der Kovarianzstruktur so restringiert, dass die Varianzzerteilung aller manifester Variablen gleich ist. Das bewirkt inhaltlich, dass alle drei Tests jetzt die gleiche Reliabilität haben.
Wie schon im letzten Abschnitt müssen wir erneut mit Labels arbeiten, nur dass sie sich in diesem Fall auf die Residualvarianzen beziehen:
mod4 <- 'stat =~ 1*test1 + 1*test2 + 1*test3
test1 ~~ (eps)*test1
test2 ~~ (eps)*test2
test3 ~~ (eps)*test3'
fit4 <- cfa(mod4, stat_test,
meanstructure = TRUE)
Das entstehende Ergebnis können wir uns wieder mit summary angucken. In diesem Fall nehmen wir mit rsq = TRUE die Reliabilitätsschätzungen auf, um meine Behauptung auf den Prüfstand zu stellen:
summary(fit4, rsq = TRUE)
## [...]
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## stat =~
## test1 1.000
## test2 1.000
## test3 1.000
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|)
## .test1 0.787 0.071 11.132 0.000
## .test2 0.819 0.071 11.593 0.000
## .test3 0.903 0.071 12.783 0.000
## stat 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .test1 (eps) 0.200 0.018 10.954 0.000
## .test2 (eps) 0.200 0.018 10.954 0.000
## .test3 (eps) 0.200 0.018 10.954 0.000
## stat 0.399 0.060 6.605 0.000
##
## R-Square:
## Estimate
## test1 0.666
## test2 0.666
## test3 0.666
## [...]
Um einen Test dieser Restriktion durchführen zu können, ist es wichtig zu bedenken, dass das $\tau$-äquivalente Modell und das esentiell $\tau$-parallele Modell nicht direkt miteinander verglichen werden können. Das liegt daran, dass keines der beiden durch die Einführung von Restriktionen in das Andere überführt werden kann. Allerdings kann auch das $\tau$-parllele Modell durch die Restriktion der Residualvarianzen aus dem essentiell $\tau$-äqauivalenten Modell gewonnen werden. Daher muss auch hiermit der Modellvergleich erfolgen, um die Zusatzannahme (die Gleichheit der Residualvarianzen) inferenzstatistisch zu prüfen:
lavTestLRT(fit2, fit4)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
## fit2 2 677.05 696.56 5.383
## fit4 4 685.45 699.38 17.782 12.399 0.20816 2 0.00203
##
## fit2
## fit4 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Wir sehen in diesem Fall, dass die Annahme gleicher Residualvarianzen (und somit gleicher Reliabilitäten) verworfen werden muss.
$\tau$-paralleles Modell
Das $\tau$-parallele Messmodell ist das restriktivste Messmodell. Hier sind Ladungen, Intercepts und Residualvarianzen über die drei Tests hinweg gleich gesetzt. Das bedeutet, dass die beiden Annahmen aus dem $\tau$-äquivalenten Messmodell und dem essentiell $\tau$-parallelen Messmodell zusammengeführt werden.
In lavaan sieht das folgendermaßen aus:
mod5 <- 'stat =~ 1*test1 + 1*test2 + 1*test3
test1 ~ (alp)*1
test2 ~ (alp)*1
test3 ~ (alp)*1
test1 ~~ (eps)*test1
test2 ~~ (eps)*test2
test3 ~~ (eps)*test3'
fit5 <- cfa(mod5, stat_test,
meanstructure = TRUE)
Erneut können wir den Likelihood-Ratio Test nutzen. Wie auch bei der anova-Funktion, die Sie letztes Semester genutzt haben, um Regressionsmodelle zu vergleichen, können Sie bei lavTestLRT sequentiell mehrere Modelle testen lassen. Für den Überblick über den linken Pfad der Hierarchie:
lavTestLRT(fit1, fit2, fit3, fit5)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
## fit1 0 675.66 700.75 0.000
## fit2 2 677.05 696.56 5.383 5.3830 0.11872 2 0.067780
## fit3 4 678.83 692.77 11.166 5.7829 0.12555 2 0.055495
## fit5 6 685.76 694.12 22.093 10.9271 0.19286 2 0.004238
##
## fit1
## fit2 .
## fit3 .
## fit5 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Wir sehen also, dass wir in diesem Fall bei fit3 den Schlussstrich ziehen sollten und das $\tau$-äquivalente Messmodell annehmen können, weil dessen Restriktionen nicht verworfen werden (gegenüber dem Modell mit essentiell $\tau$-äquivalenten Messungen), aber die zusätzliche Restriktion der gleichen Residualvarianzen bei einem $\alpha$-Fehlerniveau von 5% abgelehnt wird.
fit3 und fit4 können über den LRT nicht direkt miteinander verglichen werden, weil keins der Beiden ein Sonderfall des Anderen ist - daher stehen Sie in der Hierarchie auch auf der gleichen Stufe. Sie können aber natürlich auch den rechten Pfad prüfen:
lavTestLRT(fit1, fit2, fit4, fit5)
##
## Chi-Squared Difference Test
##
## Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
## fit1 0 675.66 700.75 0.000
## fit2 2 677.05 696.56 5.383 5.3830 0.11872 2 0.06778
## fit4 4 685.45 699.38 17.782 12.3994 0.20816 2 0.00203
## fit5 6 685.76 694.12 22.093 4.3106 0.09812 2 0.11587
##
## fit1
## fit2 .
## fit4 **
## fit5
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Literatur
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden (5. Auflage, 1. Auflage: 2010). Weinheim: Beltz.
Brotherton, R., French, C. C., & Pickering, A. D. (2013). Measuring belief in conspiracy theories: the generic conspiracist beliefs scale. Frontiers in Psychology, 4, 279, DOI: 10.3389/fpsyg.2013.00279.
- Blau hinterlegte Autor:innenangaben führen Sie direkt zur universitätsinternen Ressource.